Authored by Chris Fregly: Former Netflix Streaming Platform Engineer, AWS Certified Solution Architect and Purveyor of fluxcapacitor.com.
Ahead of the upcoming 2nd annual re:Invent conference, inspired by Simone Brunozzi’s recent presentation at an AWS Meetup in San Francisco, and collected from a few of my recent Fluxcapacitor.com consulting engagements, I’ve compiled a list of 10 useful time and clock-tick saving tips about AWS.
1) Query AWS resource metadata

Can’t remember the EBS-Optimized IO throughput of your c1.xlarge cluster? How about the size limit of an S3 object on a single PUT? awsnow.info is the answer to all of your AWS-resource metadata questions. Interested in integrating awsnow.info with your application? You’re in luck. There’s now a REST API, as well!
Note: These are default soft limits and will vary by account.
2) Tame your S3 buckets


Delete an entire S3 bucket with a single CLI command:
aws s3 rb s3://<bucket-name> --force
Recursively copy a local directory to S3:
aws s3 cp <local-dir-name> s3://<bucket-name> --region <region-name> --recursive
3) Understand AWS cross-region dependencies
A PagerDuty-outage blog post from earlier this summer revealed an interesting cross-region dependency that violates conventional thinking regarding region isolation in AWS.
Summary: degradation of a Northern California common peering point between the us-west-1 and us-west-2 regions led to the loss of 2 simultaneous AZ’s - each running in a different region. Those relying on this deployment configuration for things like HA, quorum (ZooKeeper, in PagerDuty’s example), or load balancing were hosed for those 86 mins on April 13, 2013.
4) Use ZFS with EBS

Two great tastes come together.
Per the AWS documentation, EBS volumes can expect an annual failure rate (AFR) of between 0.1-0.5% compared with commodity hard disks that have an AFR of around 4%; where failure is a complete loss of the volume.
To protect yourself against this risk (albeit small), you can pool multiple EBS volumes within ZFS in a RAIDZ configuration. While relatively undocumented, Chip Schweiss has a great blog post - as well as some useful scripts - detailing this topic.
5) Stripe your RDS disks for better performance

There’s an easy trick to maximizing the performance of your MySQL and Oracle RDS instances. Initially, provision your instance to the minimum size possible. Then slowly increase your storage by 5GB increments. Each increment will create an additional disk stripe which will increase IO and reduce seek time.
This, and many other optimization tips, can be found at the EX-AWS Engineer IAMA.
6) Avoid noisy neighbors

In any multi-tenant, non-dedicated, virtualized environment like AWS, you will certainly experience the noisy neighbor effect measured by CPU Steal. CPU Steal is the percentage of time that your virtualized guest is involuntarily waiting for physical host CPU from another guest. Great explanations of CPU steal can be found at Stackdriver’s blog here and here.
When using EBS-backed EC2 instances, you can flee a noisy environment by simply stopping and starting the instance. Of course, you’ll need to make sure your healthcheck policies don’t terminate the instance before it restarts. For S3-backed EC2 instances, the only option is to terminate/launch a new instance.
You can avoiding noisy neighbors by preferring larger EC2 instance types. Larger virtualized guest instances require more physical host resources - and therefore the host can support less overall tenants. Tenants are always of equal instance type. t1.micro’s are extremely noisy and bursty - similar to my old college-dorm neighbors above.
The most effective way to avoid noisy neighbors, however, is to pay extra for dedicated EC2 instances. Can’t remember how much a dedicated instance costs? Our buddies at awsnow.info have your answer.
7) Embrace CloudFormation

AWS has developed a tool called CloudFormer that allows you to create CloudFormation templates from your existing AWS resources. This tool is as slick and mysterious as CloudFormation itself.
Maintenance of CloudFormation templates is not easy. However, you can use #include-like macros on your template sources to cobble together per-resource snippets into a complete template. This facilitates template reuse and snippet comments.
The new unified AWS CLI has support for CloudFormation templates per a recent post by AWS’s Movember-friendly Evan Brown.
Another project, troposphere, is gaining traction along the same lines. Peter Sankauskas from Answers For AWS describes this project here.
It’s worth noting that CloudFormation recently added support for Virtual Private Cloud (VPC).
8) Avoid underperforming CPU architectures for your workload
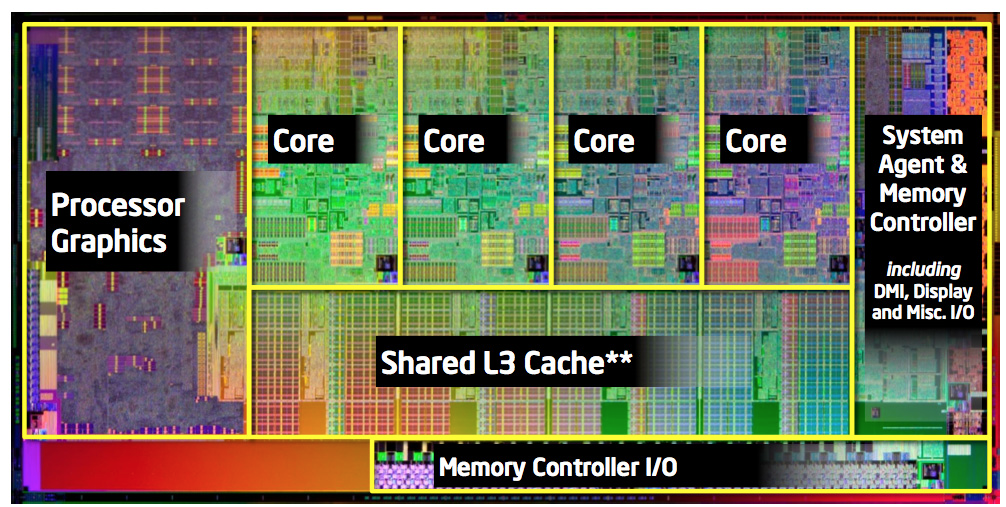
Different CPU architectures enable better performance for certain workloads depending on the NUMA characteristics, cache sizes, number of cores, number of hardware threads, GPU, etc.
Virtualized environments like AWS do not guarantee a particular CPU architecture. Physical hardware is being refreshed throughout AWS data centers on a daily basis. One of AWS’s oldest regions, us-east-1, contains a few different types of CPUs including AMD Opteron, Intel Xeon, and Intel Sandy Bridge. My British colleague, Adrian Cockroft, from Netflix loves Sandy Bridge as much as mayonnaise on his fries.
If your workload is sensitive to such physical CPU architecture, it’s best to detect this at startup (cat /proc/cpuinfo on Linux) and restart/terminate the instance. If you’re sensitive to cost, you can run the instance for 55 minutes, then terminate it. With AWS, you’re paying for the hour either way.
9) Use Virtual Private Cloud (VPC) from the start

VPC is now the default configuration for new accounts in most regions. Retrofitting a non-VPC environment to use VPC is very time-consuming task - particularly in large deployments with lots of security groups.
There is currently no migration path for non-VPC security groups (ingress only) and VPC security groups (ingress and egress). In fact, Netflix is still running non-VPC given this lack of security-group migration.
Another benefit is that VPC enable ELB’s as a middletier load balancer behind a private subnet. Without VPC, ELBs are public-facing.
A common configuration is to use ELB with HAProxy to enable more fine-grained control over the load balancing algorithms since ELB’s are black boxes and can be stickier than expected.
It’s worth noting that Network Address Translation (NAT) instances in a VPC are actually EC2 instances performing Port Address Translation (PAT) versus dedicated hardware devices with single-purpose ASIC chips.
10) Pre-warm and autoscale-out your AWS resources before expected spikes

ELBs - along with other AWS blackbox resources such as NAT, S3, DynamoDB, Glacier, and Beanstalk - are made up of EC2 instances just like your custom application.
These instances need to autoscale up and down just like your application - unless you provision them ahead of time. There is currently no way to do this without contacting AWS directly.
By default, Amazon will do their best to autoscale based on traffic, but it’s always best to notify them for pre-warm and provisioning ahead of an expected spike.
To demonstrate the difference in provisioning, here is dig against a high-traffic, pre-warmed and provisioned ELB at Netflix:
$dig cbp-us.nccp.netflix.com
;; ANSWER SECTION:
cbp-us.nccp.netflix.com. 291 IN CNAME dualstack.nccp-cbp-us-frontend-61636918.us-east-1.elb.amazonaws.com.
dualstack.nccp-cbp-us-frontend-61636918.us-east-1.elb.amazonaws.com. 18 IN A 107.21.243.94
dualstack.nccp-cbp-us-frontend-61636918.us-east-1.elb.amazonaws.com. 18 IN A 107.20.155.88
dualstack.nccp-cbp-us-frontend-61636918.us-east-1.elb.amazonaws.com. 18 IN A 107.21.237.35
dualstack.nccp-cbp-us-frontend-61636918.us-east-1.elb.amazonaws.com. 18 IN A 50.17.181.99
dualstack.nccp-cbp-us-frontend-61636918.us-east-1.elb.amazonaws.com. 18 IN A 107.22.188.158
dualstack.nccp-cbp-us-frontend-61636918.us-east-1.elb.amazonaws.com. 18 IN A 107.20.146.144
dualstack.nccp-cbp-us-frontend-61636918.us-east-1.elb.amazonaws.com. 18 IN A 23.21.242.67
dualstack.nccp-cbp-us-frontend-61636918.us-east-1.elb.amazonaws.com. 18 IN A 174.129.230.252
Notice the 8 ELB instances that are returned. Also notice that they’re dualstack, IPv6-enabled.
Next, here is dig against a low-traffic, default ELB for my FluxCapacitor open source project demo:
$dig edge.fluxcapacitor.com
;; ANSWER SECTION:
edge.fluxcapacitor.com. 300 IN CNAME awseb-e-j-awsebloa-pjstt309pthn-1823662872.us-east-1.elb.amazonaws.com.
awseb-e-j-awsebloa-pjstt309pthn-1823662872.us-east-1.elb.amazonaws.com. 60 IN A 23.21.119.137
awseb-e-j-awsebloa-pjstt309pthn-1823662872.us-east-1.elb.amazonaws.com. 60 IN A 54.225.176.201
Notice only 2 ELB instances are returned.
Again, these are the instances that makeup the actual ELB - not the instances behind the ELB.
Discuss on Hacker News.