
This is a guest post by Doug Barth, a software generalist who has currently found himself doing operations work at PagerDuty. Prior to joining PagerDuty, he worked for Signal in Chicago and Orbitz, an online travel company.
A little over six months ago, PagerDuty switched its production MySQL database to XtraDB Cluster running inside EC2. Here's the story of why and how we made the change.
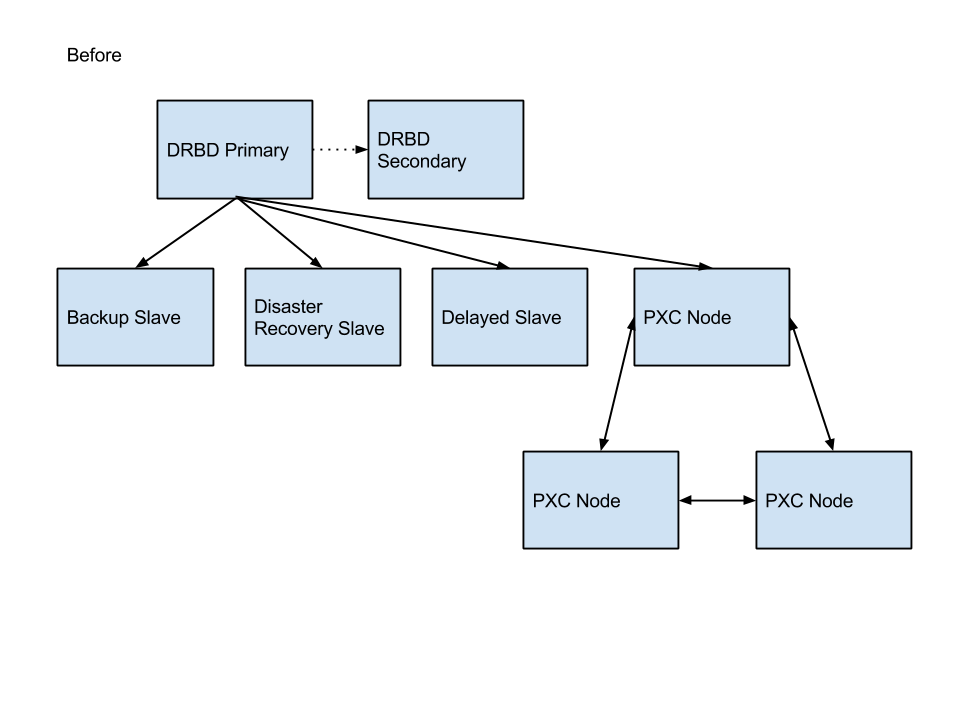
How the Database Looked Before
PagerDuty's MySQL database was a fairly typical deployment. We had:
-
A pair of Percona Servers writing data to a DRBD-backed volume.
-
EBS disks for both the primary and secondary servers backing the DRBD volume.
-
Two synchronous copies of the production database. (In the event of a failure of the primary, we wanted to be able to quickly switch to the secondary server without losing any data.)
-
A number of asynchronous replication slaves for disaster recovery, backups and accidental modification recovery.
Problems With the Old Setup
Our database setup served us well for several years, but the failover architecture it provided didn't meet our reliability goals. Plus, changing hosts was a hassle: To flip from one DRBD host to another, we had to stop MySQL on the primary, unmount the DRBD volume, change the secondary to primary status, mount the volume on the secondary and start MySQL. That setup requires downtime - and once MySQL was up and running on the new server, we had a cold buffer pool which would need to warm up before the application's performance returned to normal.
We tried using Percona's buffer-pool-restore feature to shorten the downtime window, but our buffer pool was prohibitively large. We found restoring the saved buffer pool pages used more system resources than servicing incoming request traffic slowly.
Another issue: Our async slaves became unrecoverable if an unplanned flip occurred. We were storing the binlogs on a separate, non-DRBD-backed disk and had disabled sync_binlog (due to the performance penalty it introduced). This setup meant that we needed to restore our async slaves from backup after an unplanned flip.
What We Liked About XtraDB Cluster
There were a few things about XtraDB Cluster that stood out.
-
Instead of having an active and passive server pair, we would be able to have three live servers replicating changes between each other synchronously. That would enable us to move connections over more quickly.
-
Since XtraDB Cluster is multi-master, it would let us send traffic to multiple servers, ensuring that each server had a warm buffer pool at all times. In XtraDB Cluster, asynchronous slaves can use any node as a master and be moved between nodes without breaking the replication stream.
-
The cluster's automatic node provisioning fit well with our existing automation. After configuring a new node, all we’d have to do is provide another node’s address - the new node would receive a copy of the dataset automatically (and join the cluster once it had synced).
What We Did to Prepare
Getting our application ready for XtraDB Cluster did involve a few new constraints. Some of those were simple MySQL tweaks that are mostly hidden from the application logic, while others were more fundamental changes.
On the MySQL side:
-
We needed to ensure that only InnoDB tables with primary keys were used.
-
We had to ensure our application wasn't dependent on the query cache being enabled (since it is not supported by the cluster).
-
We had to switch from statement-based to row-based replication.
Besides these MySQL configuration changes, which we were able to test out in isolation on the DRBD server side, the application logic needed to change:
-
We needed to move to a distributed locking mechanism, since MySQL locking (e.g., SELECT FOR UPDATE statements) is local to the cluster node.
-
Thus, we replaced our MySQL locks with Zookeeper locks (Zookeeper was already being used for that purpose in other parts of our system).
-
To account for the fact that writesets would need to be sent synchronously to all nodes, we changed the logic of jobs that make large changes (typically archiving jobs) to use many smaller transactions rather than one big transaction.
How We Handled Schema Changes
Schema changes are especially impactful in XtraDB Cluster. There are two options for controlling how schema changes are applied in the cluster: total order isolation (TOI) and rolling schema upgrade (RSU).
RSU allows you to upgrade each node individually, desyncing that node from the cluster while the DDL statement is running and then rejoining the cluster. But this approach can introduce instability - and RSU wouldn't avoid operational issues with schema changes on large tables (since it buffers writesets in memory until the DDL statement completes).
TOI, by contrast, applies schema upgrades simultaneously on all cluster nodes, blocking the cluster until the change completes. We decided to use TOI with Percona's online schema change tool (pt-online-schema-change). It ensures that any blocking operations are quick and therefore don't block the cluster.
The Migration Process
Having established the constraints that XtraDB Cluster would introduce, we started the rollout process.
First, we stood up a cluster in production as a slave of the existing DRBD database. By having that cluster run in production and receive all write traffic, we could start seeing how it behaved under real production load. We also set up metrics collection and dashboards to keep an eye on the cluster.
In parallel to that effort, we spent some time running load tests against a test cluster to quantify how it performed relative to the existing DRBD setup.
Running those benchmarks led us to discover that a few MySQL configs had to be tweaked to get the same level of performance that we’d been enjoying:
-
Setting innodb_flush_log_at_trx_commit to 0 or 2 resulted in the best write performance (setting it to 1, by contrast, limited write scalability to just 4 threads on our test VMs). Since all changes are replicated to 3 nodes, we don’t lose any data in the event of a failure, even with relaxed disk consistency for a single node.
-
A large innodb_log_file_size value was needed. We ended up with a 1GB file for our production servers.
After satisfying ourselves that XtraDB Cluster would be able to handle our production load, we started the process of moving it into production use.
Switching all of our test environments to a clustered setup (and running load and failure tests against them) came first. In the event of a cluster hang, we needed a way to quickly reconfigure our system to fall back to a one-node cluster. We scripted that procedure and tested it while under load.
Actually moving the production servers to the cluster was a multi-step process. We had already set up a production cluster as a slave of the existing DRBD server, so we stood up and slaved another DRBD pair. (This DRBD server was there in case the switch went horribly wrong and we needed to fall back to a DRBD-based solution, which thankfully we didn't end up having to do.)
We then moved the rest of our async slaves (disaster recovery, backups, etc.) behind XtraDB Cluster. With those slaves sitting behind XtraDB Cluster, we executed a normal slave promotion process to move production traffic to the new system.
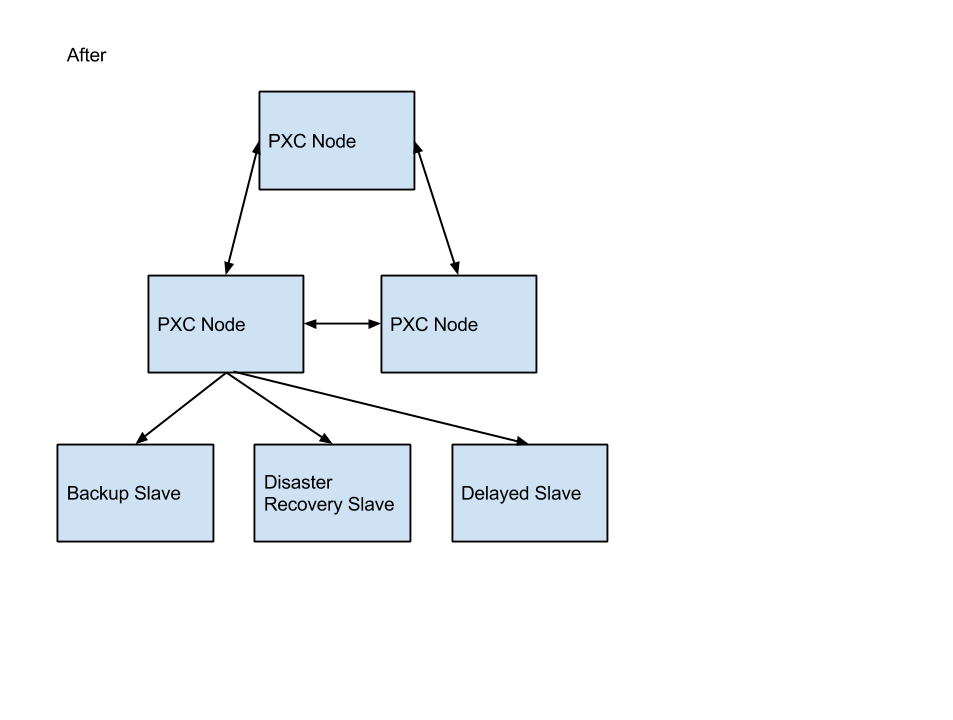
Real-World Performance: Benefits
With a bit over six months of production use, we have found a number of benefits to running on XtraDB Cluster:
-
We have successfully performed rolling restarts and upgrades of our production cluster without stopping production traffic.
-
We have performed schema modifications on our production systems using pt-online-schema-change.
-
We have optimized how write conflicts are handled. XtraDB Cluster returns a deadlock error on experiencing a conflict - even when using pt-online-schema-change to execute quick DDL statements. Conflicts lead our application servers to return a 503 response, which our load balancing tier will catch. The load balancer will subsequently retry the request on another server.
Real-World Performance: Annoyances
Along the way, we have also found a few frustrating issues:
-
Some of the cluster’s key status counters are stateful, meaning they reset to zero after running "SHOW GLOBAL STATUS". This made it difficult to monitor the system for critical counters like flow control, which increment infrequently but are critical to understanding how the system is behaving. (This issue is fixed, however, in Galera 3.x, which XtraDB Cluster 5.6 uses.)
-
ActiveRecord's MySQL adapter was hiding exceptions thrown from transactional statements, which occur when a writeset conflict takes place. (This error was fixed in Rails 4.1.)
-
We still have some work to do to be rid of the cold server problem. Currently, our application servers connect to a local HAproxy instance, which forwards their connection to a single cluster node. For planned maintenance, we slowly bleed traffic over to another cluster node to warm up its buffer pool before giving it the full production load. In the future, we plan to switch to a fully multi-master setup to ensure that all nodes have a warm buffer pool.