This is a guest post by Thiago Wolff from Peecho.
In a nutshell, Peecho is all about turning your digital content into professionally printed products. Although it might look like a simple task, a lot of stuff happens behind the scenes to make that possible. In this article, we’re going to tell you about our processing architecture as well as at a recent performance improvement with the integration of AWS Lambda functions.
Print-ready files
In order to make digital content ready for printing facilities, there are some procedures that must occur after the order is received and before the final printing. In printing industry this process is called pre-press and the Peecho platform fully automates its initial stages before routing orders to printers.
Once the file has been created by the customer and uploaded to Peecho, it undergoes our processing stage. During processing, the file is checked to make sure it contains all the elements necessary for a successful print run: do the images have the proper format and resolution, are all the fonts included, are the RGB/CMYK colors set up appropriately, are all layout elements such as margins, crop marks and bleeds set up correctly, etc.
All these checks are automated by our backend systems. The entire process is quite complex and involves heavy computational activities to be executed that are expensive and time consuming. Let’s take a more detailed look at our processing architecture.
Processing Architecture
The processing stage starts right after an order is placed and payment has been confirmed. It’s initiated by the order intake server by adding a message to a SQS processing queue with all information about the order and file to be processed. Whenever there is a message available in the queue, a new processing machine (a large EC2 instance) starts working to transform the original data into a print ready file.
At the core of the processing code we use open source libraries like iText as well as third party software for PDF and image encoding/conversion like PStill and ImageMagick. As the result of processing we generate PDF/X-3 files.
In earlier versions, when the Peecho platform first launched, all processing was executed by EC2 instances. For a single order it was done sequentially; page by page as illustrated below.
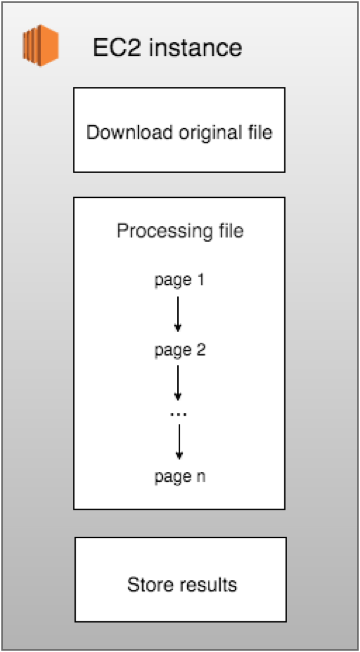
Since we can deal with any kind of files and usually really tough ones, the described transformation process could take hours to be executed. In average, it would take 15 seconds per page. Since it needed to be done sequentially, the processing time increased linearly according to the number of pages. For example, a 400-page document would take around 1 hour and 40 minutes to be processed, which is a considerable amount of time for a single file.
Recently, our development team has integrated the new AWS Lambda functions into the processing architecture and that has changed the story enormously.
AWS Lambda
Imagine if you could simply define a piece of code that runs in a dedicated machine in the cloud, without worrying about provisioning, managing and scaling the servers that you use to run the code? That’s exactly what AWS Lambda is: a compute service where you can define functions that respond to events, such as changes to data in Amazon S3.
In the new processing architecture, we took the existing processing code and converted it into a AWS Lambda function that performs all file transformations on a single page in a document. The new function is written in Node.js and is triggered after S3 file uploads.
After the processing starts, the original document is split into separate pages and uploaded to S3; when the upload completes for every page, a new Lambda instance is launched and starts cracking the page data.
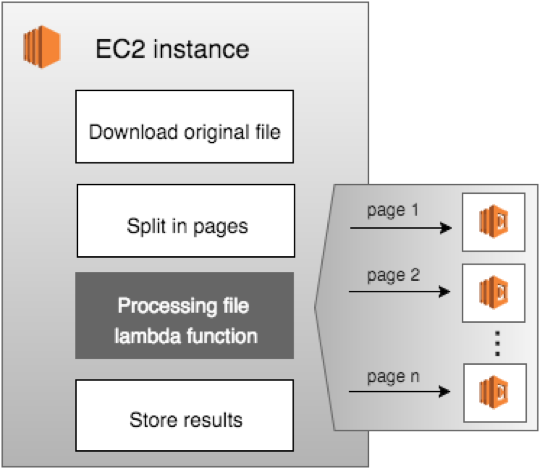
By doing that, we are now able to run a separate processing instance for each page in parallel. It means that for a 400-page document we now launch 400 Lambda instances simultaneously and process the entire document at the same period of time it would take to process a single page. Therefore, the processing time does not increase with the number of pages. And as a result, we can process almost any document in the same time we used to process a single page!
Although AWS Lambda is a great and powerful function, it has some limitations regarding execution time, disk space and memory. For instance, we are not able to use Lambda to process files larger than 500MB. Since we still have to process these big guys, the Peecho platform falls back to the previous mechanism whenever we need to handle corner cases like that.
More on Lambda
Other than document processing, Peecho also uses AWS Lambda functions in some other cool features like the generation of thumbnails for publication covers as well as content previews. For that, Lambda functions are triggered right after a publication is uploaded, so image thumbnails are instantly available in our dashboard, website and checkout pages.
Our development team is obsessed in making things simpler and faster. We are continuously seeking new possibilities for improving performance across Peecho applications. When it comes to that, AWS Lambda function makes a great fit and it’s definitely going to be more and more explored in future releases.
Article originally appeared on (http://highscalability.com/).
See website for complete article licensing information.