For different scenarios, we should choose different key-value store. There is no silver-bullet key-value store for all solutions. But if you just want a simple key-value store, easy to use, very fast, supporting many powerful data structures, redis may be a good choice for your start.
Redis is advanced key-value cache and store, under BSD license. It is very fast, has many data types(String, Hash, List, Set, Sorted Set …), uses RDB or AOF persistence and replication to guarantee data security, and supplies many language client libraries.
Most of all, market chooses Redis. There are many companies using Redis and it has proved its worth.
Although redis is great, it still has some disadvantages, and the biggest one is memory limitation. Redis keeps all data in memory, which limits the whole dataset size and lets us save more data impossibly.
The official redis cluster solves this by splitting data into many redis servers, but it has not been proven in many practical environments yet. At the same time, it need us to change our client libraries to support “MOVED” redirection and other special commands, this is unacceptable in running production too. So redis cluster is not a good solution now.
QDB
We like redis, and want to go beyond its limitation, so we building a service named QDB, which is compatible with redis, saves data in disk to exceed memory limitation and keeps hot data in memory for performance.
Introduction
QDB is a redis like, fast key-value store.It has below good features:
-
Compatible with Redis. If you are familiar with Redis, you can use QDB easily. QDB supports most of Redis commands and data structures (String, Hash, List, Set, Sorted Set).
-
Saves data in disk (exceeding memory limitation) and keeps hot data in memory, thanks to the backend storage.
-
Mutli backend storage support, you can choose RocksDB, LevelDB or GoLevelDB (Later, we will use RocksDB for example).
-
Bidirectional synchronization with Redis, we can sync data from Redis as a slave and replicate data into Redis as a master.
Backend Storage
QDB uses LevelDB/RocksDB/GoLevelDB as the backend storage. These storages are all based on log structured merge tree (LSM Tree) with very fast write and good read performance, at the same time, they all use bloom filter and LRU cache to improve read performance.
LevelDB is the earliest version developed by google, RocksDB is a optimized version maintained by facebook, GoLevelDB is a pure go implementation of LevelDB. If you only want a quick trial and don’t want to build and install RocksDB or LevelDB, you can use GoLevelDB directly, but we don’t recommend you to use it in production because of its low performance.
LevelDB and RocksDB are both great for your production, but we prefer RocksDB because its awesome performance, Later we may only support RocksDB and GoLevelDB, one for production and one for trial and test.
RebornDB
QDB is great, we can save huge data in one machine with high write/read performance. But as the dataset grows, we still meet the problem that we cannot keep all data in one machine. At the same time, the QDB server will become both a bottleneck and a single point of failure.
We must consider cluster solution now.
Introduction
RebornDB is a proxy-based distributed redis cluster solution. It’s similar to twemproxy which is nearly the earliest and most famous redis proxy-based cluster solution.
But twemproxy has its own problems. It only supports static cluster topology, so we cannot add or remove redis for data re-sharding dynamically. If we run many twemproxys and want to add a backend redis, how to let all twemproxys update the configuration safely is another problem which increases complexity for IT operation. At the same time, twitter, the company developing twemproxy, has already given up and not used it in production now.
Unlike twemproxy, RebornDB has a killer feature: re-sharding dataset dynamically, this is useful when your dataset grows quickly and you have to add more storage nodes for scalability. And above all, RebornDB will do re-sharding transparently and not influence current running services.
Architecture
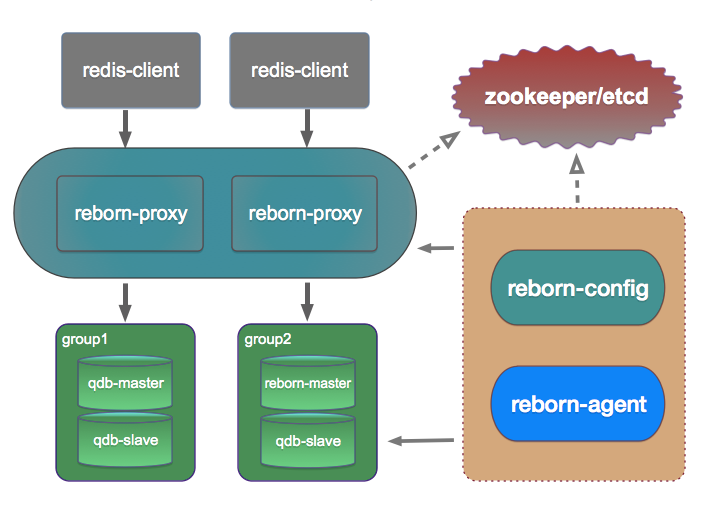
We can think RebornDB is a black box and use any existent redis client to communicate with it like a single redis server. The following picture shows the RebornDB architecture.
RebornDB has following components: reborn-proxy, backend store, coordinator, reborn-config, and reborn-agent.
Reborn-proxy
The unique outward service client reborn-proxy. Any redis client can connect to any reborn-proxy and run commands.
Reborn-proxy parses command sent from client using RESP, dispatches it to the corresponding backend store, receives the reply and returns to the client.
Reborn-proxy is stateless, which means that you can horizontally scale redis-proxy easily to serve more requests.
We may have many reborn-proxys, how to let clients to discover them is another topic in distributed system design, but we will not dive into it here, some practical approaches are using DNS, LVS, HAProxy, etc...
Backend store
Backend store is reborn-server (a modifed redis version) or QDB. We introduces a concept named group to manage one or more backend stores. A group must have a master and zero, one, or more slaves to form a replication topology.
We split whole dataset into 1024 slots(we will use hash(key) % 1024 to determine which slot the key belongs to), and save different slots in different groups. If you want to do re-sharding, you can add a new group and let RebornDB migrate all data in one slot from other group to it.
We can also use different backend stores in different groups. E.g, we want group1 to save hot data and group2 to save large cold data, and we can use reborn-server in group1 and QDB in group2. Reborn-server is much faster than QDB, so we can guarantee hot data read/write performance.
Coordinator
We use zookeeper or etcd as the coordinator, which coordinate all services when we need to do some write operations, like resharding, failover, etc.
All RebornDB informations are saved in coordinator, e.g. key routing rules, with them reborn-proxy can dispatch commands to correct backend store.
Reborn-config
Reborn-config is the management tool, we can use it to add/remove group, add/remove store in a group, migrate data from one group to another, etc.
We must use reborn-config if we want to change RebornDB cluster information. E.g, we cann’t use “SLAVEOF NO ONE” command on backend store directly to promote a master, and must use “reborn-config server promote groupid server”. We must not only change the replication topology in group, but also update the information in coordinator too, only reborn-config can do this.
Reborn-config also supplies a web site so that you can manage RebornDB easily, and you can also use its HTTP restful API for more control.
Reborn-agent
Reborn-agent is a HA tool. You can use it to start/stop applications (reborn-config, qdb-server, reborn-server, reborn-proxy). We will discuss in detail in subsequent High Availability section.
Resharding
RebornDB supports resharding dynamically. How do we support this?
As we said above, we will split whole dataset into 1024 slots, and let different groups store different slots. When we add a new group, we will migrate some slots from old groups into the new group. We call this migration when in resharding, and the minimum migration unit is slot in RebornDB.
Let’s start with a simple example below:

We have two groups, group1 has slots 1,2, and group2 has slots 3, 4, 5. Now group2 has a high workload, we will add a group3 and migrate slot 5 into it.
We can use following command to migrate slot 5 from group2 to group3.
reborn-config slot migrate 5 5 3
This comamnd looks simple, but we need to do more work internally to guarantee migration safety. We must use a 2PC to tell reborn-proxy that we will migrate slot5 from group2 to group3, after all reborn-proxys confirm and reponse, we will begin to migrate.

The migration flow is simple: get a key in slot5, migrate its data from group2 to group3, then delete the key in group2, once again. In the end, group2 has no slot5 data and all slot5 data is in group3.
When slot5 is in migration, Reborn-proxy may handle a command which the key belongs to slot5, but reborn-proxy cannot know whether this key is in group2 or in group3 at that time. So reborn-proxy will send a key migration command to group2 first, then dispatch this command to group3.
The key migration is atomic, so we can be sure that the key is in group3 after doing migration command, whether it was in group2 or group3 before.
If no data belongs to slot5 exists in group2, we will stop migration, and the topology looks like below:

High Availability
RebornDB uses reborn-agent to supply HA solution.
Reborn-agent will check applications it started whether are alive or not every second. If the reborn-agent finds an application is down, it will restart it again.
Reborn-agent is similar like supervisor but has more great features.
Reborn-agent supplies HTTP Restful API so that we can add/remove applications which need to be monitored dynamically. E.g, we can use HTTP “/api/start_redis” API to start a new reborn-server, or “/api/start_proxy” API to start a new reborn-proxy, we can also use “/api/stop” to stop a running application and remove it from monitoring list.
Reborn-agent is not only for local application monitoring, but also for backend store HA. Mutli reborn-agents will first elect a leader through coordinator, a leader reborn-agent will check backend store alive every second, if it finds the backend store is down, it will do failover. If the down backend store is slave, reborn-agent will only set it offline in coordinator, but if the down backend store is master, reborn-agent will select a new master from slaves, and do failover.
Todo……
Although RebornDB has many great features, we still need more work to improve it. We may do following things later:
-
More user friendly. Now running RebornDB is not easy, we may do some work like initializing slots, adding server to group, assigning slots to one group, etc. How to reduce the user threshold must be considered for us in future work.
-
Replication migration. Now we migrate slot key by key, it is not fast when a slot has much data. Using replication migration may be better. In the above example, group2 first generate a snapshot from which group3 can get all slot5 data at that point time, then group3 syncs the changes from group2 incrementally. When we find group3 catches all data changes in slot5 with group2, we will do switchover, and delete slot5 in group2.
-
Pretty dashboard. We want to control and monitor everything through dashboard, in order to provide a better user experience.
-
P2P based cluster, now RebornDB is a proxy-based cluster solution, we may redesign whole architecture and use P2P like official redis cluster later.
Conclusion
Building up a distributed key-value store is not an easy thing. The road ahead will be long and we have just made a small step now.
If you want to use a redis-like key-value store, saving more data and supporting resharding dynamically in distributed system, RebornDB is a good choice for you.
You can try it here and any advice and feedback is very welcome. :-)
Related Articles