The email sent will contain a link to this article, the article title, and an article excerpt (if available). For security reasons, your IP address will also be included in the sent email.
When we last visited WhatsApp they’d just been acquired by Facebook for $19 billion. We learned about their early architecture, which centered around a maniacal focus on optimizing Erlang into handling 2 million connections a server, working on All The Phones, and making users happy through simplicity.
Two years later traffic has grown 10x. How did WhatsApp make that jump to the next level of scalability?
Rick Reed tells us in a talk he gave at the Erlang Factory: That's 'Billion' with a 'B': Scaling to the next level at WhatsApp (slides), which revealed some eye popping WhatsApp stats:
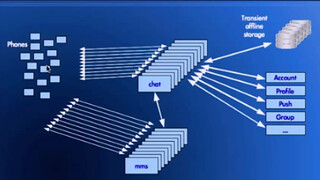
What has hundreds of nodes, thousands of cores, hundreds of terabytes of RAM, and hopes to serve the billions of smartphones that will soon be a reality around the globe? The Erlang/FreeBSD-based server infrastructure at WhatsApp. We've faced many challenges in meeting the ever-growing demand for our messaging services, but as we continue to push the envelope on size (>8000 cores) and speed (>70M Erlang messages per second) of our serving system.
What are some of the most notable changes from two years ago?
-
Obviously much bigger in every dimension, except the number of engineers. More boxes, more datacenters, more memory, more users, and more scale problems. Handling this level of growth with so few engineers is what Rick is most proud of: 40 million users per engineer. This is part of the win of the cloud. Their engineers work on their software. The network, hardware, and datacenter is handled by someone else.
-
They’ve gone away from trying to support as many connections per box as possible because of the need to have enough head room to handle the overall increased load on each box. Though their general strategy of keeping down management overhead by getting really big boxes and running efficiently on SMP machines, remains the same.
-
Transience is nice. With multimedia, pictures, text, voice, video all being part of their architecture now, not having to store all these assets for the long term simplifies the system greatly. The architecture can revolve around throughput, caching, and partitioning.
-
Erlang is its own world. Listening to the talk it became clear how much of everything you do is in the world view of Erlang, which can be quite disorienting. Though in the end it’s a distributed system and all the issues are the same as in any other distributed system.
-
Mnesia, the Erlang database, seemed to be a big source of problem at their scale. It made me wonder if some other database might be more appropriate and if the need to stay within the Erlang family of solutions can be a bit blinding?
-
Lots of problems related to scale as you might imagine. Problems with flapping connections, queues getting so long they delay high priority operations, flapping of timers, code that worked just fine at one traffic level breaking badly at higher traffic levels, high priority messages not getting serviced under high load, operations blocking other operations in unexpected ways, failures causing resources issues, and so on. These things just happen and have to be worked through no matter what system you are using.
-
I remain stunned and amazed at Rick’s ability to track down and fix problems. Quite impressive.
Rick always gives a good talk. He’s very generous with specific details that obviously derive directly from issues experienced in production. Here’s my gloss on his talk…
Stats














 Return to Article
Return to Article