The email sent will contain a link to this article, the article title, and an article excerpt (if available). For security reasons, your IP address will also be included in the sent email.
Hey, it's HighScalability time:
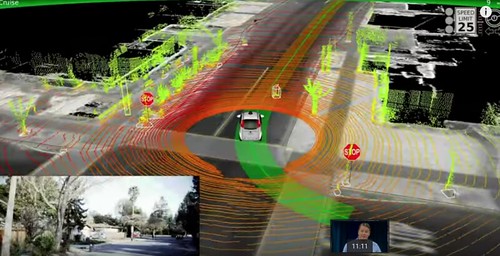
Hunter-Seeker? Nope. This is the beauty of what a Google driverless car sees.
Great TED talk.
- $2.8 billion: projected Instagram ad revenue in 2017; 1 trillion: Azure event hub events per month; 10 million: Stack Overflow questions asked; 1 billion: max volts generated by a lightening strike; 850: apps downloaded every second from the AppStore; 2000: years data can be stored in DNA; 60: # of robots needed to replace 600 humans; 1 million: queries per second with Nginx, Ubuntu, EC2
- Quotable Quotes:
- Tales from the Lunar Module Guidance Computer: we landed on the moon with 152 Kbytes of onboard computer memory.
- @ijuma: Included in JDK 8 update 60 "changes GHASH internals from using byte[] to long, improving performance about 10x
- @ErrataRob: I love the whining over the Bitcoin XT fork. It's as if anarchists/libertarians don't understand what anarchy/libertarianism means.
- Network World: the LHC Computing Grid has 132,992 physical CPUs, 553,611 logical CPUs, 300PB of online disk storage and 230PB of nearline (magnetic tape) storage. It's a staggering amount of processing capacity and data storage that relies on having no single point of failure.
- @petereisentraut: Chef is kind of a distributed monkey-patching festival running as root.
- @SciencePorn: If you were to remove all of the empty space from the atoms that make up every human on earth, all humans would fit into an apple.
- SDN for the cloud: Most of the concepts presented in the papers have been put into practice in Microsoft cloud infrastructures. As a result of these improvements, modern Azure services can carry up to 1,400,000 SQL databases. Moreover, a typical Azure event hub sees as high as 1 trillion events per month.
- On the Alphabet Google reorg...what Horace Dediu has to say on functional vs divisional organizations may provide insight. A functional organization, which is used by the Army and Apple, prevents cross divisional fights for resources and power. Those are the kind of internal politics that kill a company. Why not just sidestep all that?
- Here's how Pinterest shards MySQL to scale: All data needed to be replicated to a slave machine for backup, with high availability and dumping to S3 for MapReduce...You never want to read/write to a slave in production...Slaves lag, which causes strange bugs; I still recommend startups avoid the fancy new stuff — try really hard to just use MySQL. Trust me. I have the scars to prove it...We created a 64 bit ID that contains the shard ID...To create a new Pin, we gather all the data and create a JSON blob...A mapping table links one object to another...there are three primary ways to add more capacity...more RAM...open up new ranges...move some shards to new machines...This system is best effort. It does not give you Atomicity, Isolation or Consistency in all cases...We stored the shard configuration table in ZooKeeper...This system has been in production at Pinterest for 3.5 years now and will likely be in there forever.
- Nobody expects the quadruple fault! Google loses data as lightning strikes: four successive lightning strikes on the local utilities grid that powers our European datacenter caused a brief loss of power to storage systems...only a very small number of disks remained affected, totalling less than 0.000001% of the space of allocated persistent disks...full recovery is not possible.
- Flxone upgraded to Go version 1.5 and reduced their 95-percentile garbage collector from 279 milliseconds down to just 10 ms, a 96% decrease in garbage collection pause time. Average request latency dropped by 53%. I wonder now if they can reduce the number of nodes required to meet their SLA? And would the results hold if they wrote their app more natively, that is to generate garbage?
Don't miss all that the Internet has to say on Scalability, click below and become eventually consistent with all scalability knowledge (which means this post has many more items to read so please keep on reading)...














 Return to Article
Return to Article