The email sent will contain a link to this article, the article title, and an article excerpt (if available). For security reasons, your IP address will also be included in the sent email.
Hey, it's HighScalability time:
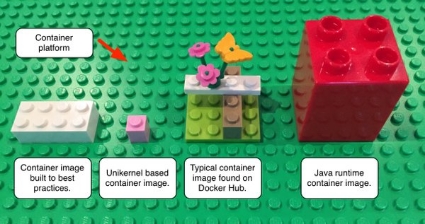
If you can't explain it with Legos then you don't really understand it.
If you like this sort of Stuff then please support me on Patreon.
- 700 trillion: more pixels in Google's Satellite Map; 9,000km: length of new undersea internet cable from Oregon to Japan; 60 terabits per second: that undersea internet cable again; 12%: global average connection speed increase; 76%: WeChat users who spend more than 100RMB ($15) per month; 5 liters: per day pay in beer for Pyramid workers; 680: number of rubber bands it takes to explode a watermelon; 1,000: new Amazon services this year; $15 billion: amount Uber has raised; 7 million: # of feather on on each bird in Piper; 5.8 million: square-feet in Tesla Gigafactory; 2x: full-duplex chip could double phone-network data capacity;
- Quotable Quotes:
- @hyc_symas: A shame everyone is implementing on top of HTTP today. Contemporary "protocol design" is a sick joke.
- @f3ew: Wehkamp lost dev and accept environments 5 days before launch. Shit happens. 48 hours to recovery. #devopsdays
- Greg Linden: Ultimately, [serverless computing] this is a good thing, making compute more efficient by allowing more overlapping workloads and making it easier to move compute around. But it does seem like compute on demand could cannibalize renting VMs.
- @viktorklang: What if we started doing only single-core chips with massive eDRAM on-package and PCI-E peer-writes MPI between? (Micro-blade machines?)
- Robert Graham: Programmers fetishize editors. Real programmers, those who produce a lot of code, fetishize debuggers
- @jasonhand: "Systems are becoming more ephemeral and we have to find a way to deal with it" (regarding monitoring) - @adrianco #monitorama
- @aphyr: Queues *can* improve fault tolerance, but this only happens if they don't lose your messages. The only one I know of that doesn't is Kafka.
- Tom Simon: There are, accordingly, two ways of reading books; but infinitely many ways to divide up the act of reading into two classes.
- Puppet: High-performing IT organizations deploy 200 times more frequently than low performers, with 2,555 times faster lead times.
- @benzobot: “The system scaled with the number of engineers - more engineers, more metrics.” #monitorama
- fizx: You seem to have installation confused with administration. Off the top of my head you forgot security, monitoring, logging config, backups, handling common production issues such as splitbrains, write multiplication, garbage collection snafus, upgrades between versions with questionably compatible internal apis.
- @Mark_J_Perry: This has to be one of the most remarkable achievements ever: Global Poverty Fell Below 10% for 1st Time in 2015
- ewams: If you are a services company, he is right, you should be focusing on outcomes. But, if you can't tell me in 2-3 sentences what problem you are solving and how it benefits the customer you are doing it wrong.
- @retrohack3r: Dance like nobody is watching. Encrypt like everyone is.
- @GundersenMarius: ES6 + HTTP/2 + Service Workers + Bloom-filter = efficient module loading without bundlin mariusgundersen.net/module-pusher/
- @timperrett: Distributed systems are about protocols, not implementations. Forget languages, protocols are everything.
- steveblank: What’s holding large companies back?...companies bought into the false premise that they exist to maximize shareholder value – which said “keep the stock price high.” As a consequence, corporations used metrics like return on net assets (RONA), return on capital deployed, and internal rate of return (IRR) to measure efficiency. These metrics make it difficult for a company that wants to invest in long-term innovation.
- Greg Linden: Like a lot of things at Amazon, this went through many stages of wrong before we got it right. As I remember it, this went through some unpleasant, heavyweight, and inefficient RPC (esp. CORBA) and pub-sub architectures before an unsanctioned skunkworks project built iquitos for lightweight http-based microservices
- @rawrthis: "We all die." Except my legacy stack. That crap will live forever. #devopsdays
- Jim Handy: The industry already has more than enough DRAM wafer capacity for the foreseeable future. Why is this happening? The answer is relatively simple: the gigabytes per wafer on a DRAM wafer are growing faster than the market’s demand for gigabytes.
- SwellJoe: A container doesn't consume complexity and emit order. The complexity is still in there; you still have to build your containers in a way that is replicable, reliable, and automatable. I'm not necessarily saying configuration management is the only way to address that complexity, but it does have to be addressed in a container-based environment.
- Deep Learning desires data, so if you want to build an AI that learns how to program this is how you would go about it, you would bring all the open source code into your giant, voracious, data crunching maw. Making open source data more available: Today, [GitHub] we're delighted to announce that, in collaboration with Google, we are releasing a collection of additional BigQuery tables to expand on the GitHub Archive...This 3TB+ dataset comprises the largest released source of GitHub activity to date. It contains activity data for more than 2.8 million open source GitHub repositories including more than 145 million unique commits, over 2 billion different file paths.
- In almost all cases, the single-threaded implementation outperforms all the others, sometimes by an order of magnitude, despite the distributed systems using 16-128 cores. Scalability! But at what COST? The paper is, at its heart, a criticism of how the performance of current research systems are evaluated. The authors focus on the field of graph processing, but their arguments extend to most distributed computation research where performance is a key factor. They observe that most systems are currently evaluated in terms of their scalability, how their performance changes as more compute resources are used, but that this metric is often both useless and misleading.
- hinkley: The older I get the more I feel like we're an accelerate version of the fashion industry. At least in fashion you can make an excuse that the design is thirty years old and most people don't remember the last time we did this. With software it's every six or seven. It's hard not to judge my peers for having such short memories. We were in the midst of one of these upheavals when I first started, and so I learned programming in that environment. It also means I have one more cycle than most people near my age. Now it all looks the same to me, and I understand those people who wanted to be more conservative. In fact I probably owe some people an apology.
Don't miss all that the Internet has to say on Scalability, click below and become eventually consistent with all scalability knowledge (which means this post has many more items to read so please keep on reading)...














 Return to Article
Return to Article