













How MySpace Tested Their Live Site with 1 Million Concurrent Users
This is a guest post by Dan Bartow, VP of SOASTA, talking about how they pelted MySpace with 1 million concurrent users using 800 EC2 instances. I thought this was an interesting story because: that's a lot of users, it takes big cajones to test your live site like that, and not everything worked out quite as expected. I'd like to thank Dan for taking the time to write and share this article.
In December of 2009 MySpace launched a new wave of streaming music video offerings in New Zealand, building on the previous success of MySpace music. These new features included the ability to watch music videos, search for artist’s videos, create lists of favorites, and more. The anticipated load increase from a feature like this on a popular site like MySpace is huge, and they wanted to test these features before making them live.
If you manage the infrastructure that sits behind a high traffic application you don’t want any surprises. You want to understand your breaking points, define your capacity thresholds, and know how to react when those thresholds are exceeded. Testing the production infrastructure with actual anticipated load levels is the only way to understand how things will behave when peak traffic arrives.
For MySpace, the goal was to test an additional 1 million concurrent users on their live site stressing the new video features. The key word here is ‘concurrent’. Not over the course of an hour or day… 1 million users concurrently active on the site. It should be noted that 1 million virtual users are only a portion of what MySpace typically has on the site during its peaks. They wanted to supplement the live traffic with test traffic to get an idea of the overall performance impact of the new launch on the entire infrastructure. This requires a massive amount of load generation capability, which is where cloud computing comes into play. To do this testing, MySpace worked with SOASTA to use the cloud as a load generation platform.
Here are the details of the load that was generated during testing. All numbers relate to the test traffic from virtual users and do not include the metrics for live users:
- 1 million concurrent virtual users
- Test cases split between searching for and watching music videos, rating videos, adding videos to favorites, and viewing artist’s channel pages
- Transfer rate of 16 gigabits per second
- 6 terabytes of data transferred per hour
- Over 77,000 hits per second, not including live traffic
- 800 Amazon EC2 large instances used to generate load (3200 cloud computing cores)
Test Environment Architecture
SOASTA CloudTest™ manages calling out to cloud providers, in this case Amazon, and provisioning the servers for testing. The process for grabbing 800 EC2 instances took less than 20 minutes. Calls we made to the Amazon EC2 API and requests servers in chunks of 25. In this case, the team was requesting EC2 Large instances with the following specs to act as load generators and results collectors:
- 7.5 GB memory
- 4 EC2 Compute Units (2 virtual CPU cores with 2 EC2 Compute Units each)
- 850 GB instance storage (2×420 GB plus 10 GB root partition)
- 64-bit platform
- Fedora Core 8
- In addition, there were 2 EC2 Extra-Large instances to act as the test controller instance and the results database with the following specs:
- 15 GB memory
- 8 EC2 Compute Units (4 virtual cores with 2 EC2 Compute Units each)
- 1,690 GB instance storage (4×420 GB plus 10 GB root partition)
- 64-bit platform
- Fedora Core 8
- PostgreSQL Database
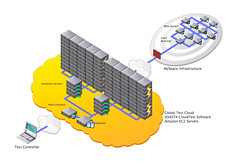
Once it has all of the servers that it needs for testing it begins doing health checks on them to ensure that they are responding and stable. As it finds dead servers it discards them and requests additional servers to fill in the gaps. Provisioning the infrastructure was relatively easy. The diagram (figure 1.) below shows how the test cloud on EC2 was set up to push massive amounts of load into MySpace’s datacenters.

figure 1.
While the test is running, batches of load generators report their performance test metrics back to a single analytics service. Each of the analytics services connect
to the PostgreSQL database to store the performance data in an aggregated repository. This is part of the way that tests of this magnitude can scale to generate and store so much data – by limiting access to the database to only the metrics aggregators and scaling out horizontally.
Challenges
Because scale tends to break everything, there were a number of challenges encountered throughout the testing exercise.
The test was limited to using 800 EC2 instances
SOASTA is one of the largest consumers of cloud computing resources, routinely using hundreds of servers at a time across multiple cloud providers to conduct these massive load tests. At the time of testing, the team was requesting the maximum number of EC2 instances that it could provision. The limitation in available hardware meant that each server needed to simulate a relatively large number of users. Each load generator was simulating between 1,300 and 1,500 users. This level of load was about 3x what a typical CloudTest™ load generator would drive, and it put new levels of stress on the product that took some creative work by the engineering teams to solve. Some of the tactics used to alleviate the strain on the load generators included:
- Staggering every virtual user’s requests so that the hits per load generator were not all firing at once
- Paring down the data being collected to only include what was necessary for performance analysis
A large portion of MySpace assets are served from Akamai, and the testing repeatedly maxed out the service capability of parts of the Akamai infrastructure
CDN’s typically serve content to site visitors based on their geographic location from a point of presence closest to them. If you generate all of the test traffic from, say, Amazon’s East coast availability zone, then you are likely going to be hitting only one Akamai point of presence.
Under load, the test was generating a significant amount of data transfer and connection traffic towards a handful of Akamai datacenters. This equated to more load on those datacenters than what would probably be generated during typical peaks, but that would not necessarily be unrealistic given that this feature launch was happening for New Zealand traffic only. This stress resulted in new connections being broken or refused by Akamai at certain load levels, and generating lots of errors in the test.
This is a common hurdle that needs to be overcome when generating load against production sites. Large-scale production tests need to be designed to take this into account and accurately stress entire production ecosystems. This means generating load from multiple geographic locations so that the traffic is spread out over multiple datacenters. Ultimately, understanding the capacity of geographic POPs was a valuable takeaway from the test.
Because of the impact of the additional load, MySpace had to reposition some of their servers on-the-fly to support the features being tested
During testing the additional virtual user traffic was stressing some of the MySpace infrastructure pretty heavily. MySpace’s operations team was able to grab underutilized servers from other functional clusters and use them to add capacity to the video site cluster in a matter of minutes.
Probably the most amazing thing about this is that MySpace was able to actually do it. They were able to monitor capacity in real time across the whole infrastructure and elastically shrink and expand where needed. People talk about elastic scalability all of the time and it’s a beautiful thing to see in practice.
Lessons Learned
- For high traffic websites, testing in production is the only way to get an accurate picture of capacity and performance. For large application infrastructures there are far too many ‘invisible walls’ that can show up if you only test in a lab and then try to extrapolate.
- Elastic scalability is becoming an increasingly important part of application architectures. Applications should be built so that critical business processes can be independently monitored and scaled. Being able to add capacity relatively quickly is going to be a key architecture theme in the coming year and the big players have known this for a long time. Facebook, Ebay, Intuit, and many other big web names have evangelized this design principle. Keeping things loosely coupled has a whole slew of benefits that have been advertised before, but capacity and performance are quickly moving to the front of that list.
- Real-time monitoring is critical. In order to react to capacity or performance problems, you need real-time monitoring in place. This monitoring should tie in to your key business processes and functional areas, and needs to be as real time as possible.
 HighScalability Team
HighScalability Team
Reader Comments (19)
another article that is disappointingly short on any details :/
this article is as useful to learning as looking at the real clouds.
this could've been such an amazing article to read, but it turned out more of an ad for soasta :(
uhm. i expected more details, too. nothing new in it but an ad for soasta.
What details would you like Paul?
I wonder how much the Amazon bill for this test was?
While maybe a little ad-like, I didn't think it was overly so. SOASTA was only specifically mentioned three times, and considering they both performed the tests and wrote the article about the tests, it seems reasonable.
Overall, I thought it was a pretty decent article and provided me with a lot of insight I didn't have before. Maybe it's because I'm not involved in large-scale sites that require cloud-deployed testing. If I were, I might think differently.
Depending on the reader, an article is almost always going to have either too little detail or too much, and I thought this one struck a nice balance.
Thanks for the write-up.
That sounds like an ad for an essentially bad service.
How does stressing Akamai's US infrastructure help prepare for an onslaught of traffic from New Zealand? Those New Zealanders would end up at Akamai's New Zealand infrastructure.
Also, if you want to load-test back-ends at MySpace as opposed to serving content by Akamai, it does not make much sense to test the Akamai part at all. Just run the tests internally in the MySpace network.
Finally, what kind of product needs 16 gigs of RAM to download a few http requests concurrently? You've got to be kidding me. What is this written in, Java?!
This article is quite underwhelming. Given that a single core Pentium M notebook can easily saturate a gigabit ethernet connection, especially incoming, there is no excuse to use more than 16 servers for this. And to buy them all from Amazon is particularly stupid because they tend to be well connected, as opposed to DSL customers in New Zealand. If launching the service really has that much impact, you'd hit a natural limit with New Zealand's meager internet connectivity and having to share it with all the other New Zealanders.
In regards to the previous complaints, I think you left the readers hanging on at least one point:
(1) What was the solution to the problem of hitting only a single Akamai datacenter? Were you able to get through that bottleneck and test other potential bottlenecks?
I'd also like to know:
(2) Were there any challenges getting
- Transfer rate of 16 gigabits per second
- 6 terabytes of data transferred per hour
in to Amazon AWS? Or was simply spawning enough instances sufficient to get this kind of transfer rate?
Can you please describe why you've chosen PostgreSQL to store log data?
I'm pretty sure that some key-value storage system would hog up less resources while storing the log data faster than regular SQL system.
Even though it doesn't describe every detail, it is still very interesting to see/hear about a way to do this sort of load test using EC2.
Thanks
Felix, I decided even though you behave like a child trolling anonymously on YouTube, that I would try and get answers to your questions. Here they are:
> How does stressing Akamai's US infrastructure help prepare for an onslaught of traffic from New Zealand? Those New Zealanders would end up at Akamai's New Zealand infrastructure.
Content from Akamai was only a part of the overall infrastructure being tested. This came up during the design of the test and was accepted by the teams because:
1) There was no other option - no major cloud player has a presence in New Zealand (yet) with an API as robust as some of the bigger players and with that quantity of servers
2) Most Akamai points of presence are relatively repeatable in terms of their performance, so since we werent primarily testing Akamai, we assumed similar performance from other datacenters in New Zealand as everyone was willing to accept this risk.
With SLA's in place and a stress test on a datacenter that was much higher than anticipated, it was a logically acceptable risk.
>
> if you want to load-test back-ends at MySpace as opposed to serving content by Akamai, it does not make much sense to test the Akamai part at all. Just run the tests internally in the MySpace network.
If you want 100% confidence that all parts of the infrastructure can sustain the projected load, every piece needs to be tested. We quite often test CDNs at the request of our customers. In this case, noone expected trouble with the CDN, yet we had a lot. Even though we may have been stressing one POP harder than expected, we observed a capacity point that noone knew of previously.
One thing to bear in mind is that it's about more than just testing Akamai from a capacity standpoint. There are bad things that happen when something is supposed to be served from Akamai, but isnt, and ends up going back to the origin servers and crushes the MySpace infrastructure. The team needed to ensure first and foremost that content was all coming from Akamai. Secondly, we needed to make sure no load got through to MySpace during Akamai cache refreshes and things like that.
Also, running tests internally does not give as accurate of a picture of performance as testing from outside of the firewalls.
>
> What kind of product needs 16 gigs of RAM to download a few http requests concurrently? You've got to be kidding me. What is this written in, Java?!
Not worth the time to answer this. Happy to respond if it sounds like the reader understands anything that was going on here ;)
>
> This article is quite underwhelming. Given that a single core Pentium M notebook can easily saturate a gigabit ethernet connection, especially incoming, there is no excuse to use more than 16 servers for this. And to buy them all from Amazon is particularly stupid because they tend to be well connected, as opposed to DSL customers in New Zealand. If launching the service really has that much impact, you'd hit a natural limit with New Zealand's meager internet connectivity and having to share it with all the other New Zealanders.
Performance testing online applications is about much more than saturation. Opening threads and sockets that actually remain open while downloading or streaming content is where you eat up all of your capacity on a server by server basis. Downloading content takes time, and while content is downloading or streaming you have lost capacity to generate load.
In addition to that, for performance testing you arent just firing off requests to generate load and letting them go. You are recording massive amounts of performance data about every single user. How much time every hit took, bandwidth transferred, errors, and things of that nature.
On the DSL point, bandwidth throttling is rarely done in performance tests because end-user connection if out of the control of application companies.
>
> (1) What was the solution to the problem of hitting only a single Akamai datacenter? Were you able to get through that bottleneck and test other potential bottlenecks?
>
We accepted the risk that we were essentially testing one Akamai point-of-presence at a magnitude higher than we would for this launch. However, identifying the bottleneck was a key learning and knowing what it's thresholds are is now understood by the operations teams and in their minds as traffic grows as something that may need to be addressed down the line.
> I'd also like to know:
>
> (2) Were there any challenges getting
>
> - Transfer rate of 16 gigabits per second
> - 6 terabytes of data transferred per hour
>
> in to Amazon AWS? Or was simply spawning enough instances sufficient to get this kind of transfer rate?
>
I'd love to tell you if there were, but there were no challenges at all. Just spawning the EC2 instances got us everything else, including seemingly wide open data transfer pipes and disk access and i/o that worked flawlessly. In fact after 3 years of doing these tests partnering with Amazon we have never run into any issues with bandwidth or I/O.
I liked the article, thanks for writing it.
Todd - If you are going to take the time to rebut a statement, better to take the time to spell check to increase credibility
Other than MySpace themselves, were other parties(Akamai and/or other carriers along the path) aware of this "controlled DoS"? If not to add capacity to handle a sudden increase in traffic, but at least to be aware that this is a requested and legitimate traffic and not some DoS attack?
You didn't have problem getting so many instances and resources from Amazon because Amazon knows who you are and what kind of business this is so they removed any limits on your account? or does Amazon really have that much excess capacity to give out to anybody that pay?
How long did this test take? How long did it take you to prepare for it?
Did you miss capturing some data that you later realized would have been useful?
Were you ramping up hits as you were seeing that MySpace was handling the load or was it 0 to 1mill from start till end?
For one of my jobs we did a similar run of tests; everything seemed to run well until we went to production. Going live revealed is that some of our backend logging and reporting systems were doing DNS reverse lookups. Because our tests were coming in from a limited IP space the lookups were not all that visible - however having several thousand users with different IP locations we found that this created a massive bottleneck. Worth keeping in mind.
Wow, I can't imagine having to deal with all that traffic and any issues that may rise during the "opening" period. I've dealt with high traffic sites but nothing like Myspace.
I'm in the performance business, and have used the cloud to simulate 40,000 virtual users. The article reinforces some of the issues that I faced - large datasets, spreading load across availability zones etc. There is one that I haven't managed to solve, and that is jmeter's inability to do parallel downloads like a browser would. This is reflected in large transactioon response times when downloading all resources for a page hit. This is also made worse by a 250 millisecond RTT on each request between Australia and us-west. Thus far I've had to account for this in my reports by stating that although the results say transaction x took between 12 and 15 seconds, this really equates to a 0.5 to 3.5 second response time, and that overall throughput isn't bottlenecking.
Does the SOASTA load tool perform parallel downloads, and did you factor out the 250 ms RTT?
One other thing - if 1,000,000 New Zealanders were all using Myspace concurrently, the streets would be noticably emptier over there.
Oh, and another thing. Sure you can run 1,000 users from a laptop. You won't saturate 1GB/sec. And your response time measurements will reflect latencies in your test hardware rather than the system under test. It's all about whether your load generator can service the interupts generated by the network card in a timely manner.
SeaPerf, why don't you read what he said instead of looking for spelling mistakes? Get a life. No one needs another jackass on the internet complaining about spelling.
Hi,
Thanks for the article it is interesting. I am working on the subject and I have some questions. Perhaps you can help.
How can you define how many computer we need to stress.
For example if I use apache bench where is the bottleneck, can I run 1000 simultanous users ?
There is some bottleneck with the network, with the CPU and RAM, how to define them ?
What kind of soft do you recommand for smaller stressing test ? (Apache bench, JMeter, Siege, ...) and how did you define your scenariis ? (using Jmeter proxy, working on apache access logs ?)
Cyril