













DbShards Part Deux - The Internals
This is a follow up article by Cory Isaacson to the first article on DbShards, Product: dbShards - Share Nothing. Shard Everything, describing some of the details about how DbShards works on the inside.
The dbShards architecture is a true “shared nothing” implementation of Database Sharding. The high-level view of dbShards is shown here: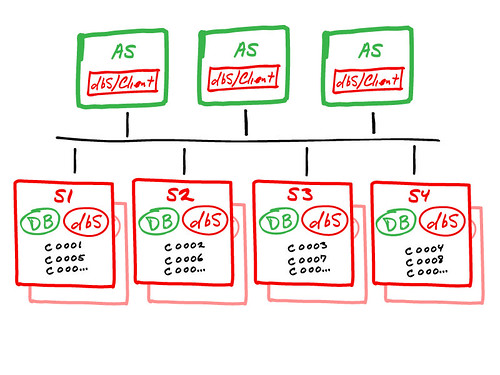
The above diagram shows how dbShards works for achieving massive database scalability across multiple database servers, using native DBMS engines and our dbShards components. The important components are:
- dbS/Client: A design goal of dbShards is to make database sharding as seamless as possible to an application, so that application developers can write the same type of code they always have. A key component to making this possible is the dbShards Client. The dbShards Client is our intelligent driver that is an exact API emulation of a given vendor’s database driver. For example, with MySQL we have full support for JDBC, and the the MySQL C driver (used in PHP, Python, Ruby, Django, etc.). In effect, the dbShards Client driver is a thin “wrapper” around the vendor driver. A key to this strategy is that all actual database calls are delegated to the underlying vendor driver, so there is actually nothing between the application and the native DBMS. For a sharded query here is how it works:
- The dbS/Client driver evaluates the SQL statement (based on the dbShards configuration set up by the system administrator, this is where the sharding scheme is define). Internally we have a very high-performance SQL parser to evaluate the SQL, and use a sophisticated internal cache to avoid re-parsing common queries.
- The correct shard is identified, and dbS/Client delegates the statement to the native vendor driver.
- If the query cannot be fulfilled from a single shard, then we flag it as a “Go Fish” query (a nickname for dbS/Parallel queries). In this case, the driver delegates the query to be run on all shards simultaneously, with the results seamlessly rolled up by the dbShards Agent running on the database servers. To the developer this looks just like a single query and result set, no special handling by the application is required.In effect we use something like a Map Reduce algorithm in the dbShards/Agent to perform this operation on a streaming basis (i.e., as soon as result rows are available they are returned to the requesting client).
- Shard Server: Each shard server has two primary components on it:
- DB: The native DBMS (MySQL, Postgres, etc.). Since dbShards is database agnostic, and we rely on proven DBMS engines that have been around for years, we can take full advantage of these products in the sharded environment. This also means that we support the same SQL and client APIs that developers are used to. The dbS/Client communicates directly with the native DBMS, without any intervening middle-tier. This is a key to dbShards performance.
- dbS/Agent: The dbShards Agent is used to manage our reliable replication capabilities, and Go Fish (parallel) queries. (The reliable replication feature is described below). When required, the dbS/Client seamlessly connects to the dbS/Agent as part of a write transaction or to fulfill a Go Fish query, again no special handling by the developer is required.
The dbShards architecture is a “shared nothing” implementation, such that as you add application servers and database servers, all components are independent and can be used for increased scalability. Using this sharded approach, applications can expect linear write scalability, and often better than linear read scalability. How is better than linear scalability possible? Because the native DBMS engines perform exceedingly well on smaller, properly sized databases, and when the shard size is correct for a given application, we alter the Database Size to Memory/CPU balance, achieving incredibly fast query times. The DBMS engines are highly efficient at caching recent results, indexes, and with dbShards we allow applications to take advantage of this capability. (In many cases this reduces the need for external caching tools).
Note that each Shard Server has a Secondary server backing it up. This is another key to the dbShards approach, because when you add shards you are adding failure points. The design goal was clear: Provide full reliability for each shard (for planned and unplanned “hot” failover), in a high-performance, scalable implementation. After researching every existing database reliability technology, we came to the conclusion that this capability did not exist. All previous implementations were either too slow, or relied on shared components that would conflict with a pure “shared nothing” design. Based on this analysis, we developed dbS/Replicate, our reliable replication technology. For each shard, here is how the architecture works:

We call this approach “out of band” replication, because we perform high-speed replication outside the native DBMS. The way it works is as follows:
- The dbS/Client streams SQL write statements to the DB (DBMS) and dbS (dbS/Agent) simultaneously, on the Primary shard server.
- The dbS/Agent then replicates the transaction to the dbS/Agent on the Secondary shard server. Now the transaction is reliable, as it exists on 2 servers. Once this happens, the transaction is committed to the DBMS on the Primary server.
- The dbS/Agent on the Secondary server then replicates the transaction to the DBMS on the Secondary server, generally a few milliseconds behind the Primary DBMS.
If a failure occurs, or if maintenance is required, the Secondary can be “promoted” to the Primary role at any time. A single shard can operate with just a single shard server temporarily, or a spare hot standby can be used as the new Secondary, maintaining the same level of reliability. Failover generally takes only a few seconds from the time the failure is detected (or initiated by a system administrator).
There are several advantages to this approach:
- It is very lightweight, and scales linearly as more shard servers are added.
- The approach provides the lowest possible latency for write transactions (85% - 90% the speed of an unprotected native DBMS).
- The Secondary DBMS can be taken offline for maintenance, without affecting reliability or application operations. This capability is used for “re-sharding” a database, performing index optimizations, schema changes, etc.
- The Secondary provides a near-real-time copy of the database, which can be used for reporting queries without adversely impacting application operations.
In summary, dbShards provides an easy to implement approach for a wide array of application requirements, with high scalability, reliable replication, and seamless implementation for both new and existing applications. Because we rely on proven native DBMS engines, and get them to perform at their optimum (through proper balancing of database size, CPU and memory), we can take full advantage of these products at what they do best. The result is linear scalability, and support for very high transaction volumes, all in an environment that is familiar to application developers.
Related Articles
 HighScalability Team
HighScalability Team
Reader Comments (7)
Did I miss something? Do you do distributed queries? Joins?
Out of the topic question : What software did they use for the drawings ?
II really like them. It's neat but also not as 'strict' as the Visio ones. Any ideas ?
I asked Tom and they are a kind of font built from freehand drawings made using pens on high gloss paper.
Vladimir, the technology definitely has great parallel query support, I was just worried about the length of the article. We like to call our parallel query support "Go Fish" queries, when the driver cannot determine the shard, then we perform the query on all shards and automatically roll up the results. This is described briefly in the article, but I see not completely enough. The way it works is we broadcast the query to all shards, then we elect a dbShards Agent to roll up the results. Its very fast, as we stream the rows as we build the result, similar to a highly efficient Map Reduce operation So queries such as:
SELECT count(*) FROM customer WHERE last_order_date >= '7/1/2010'
work fine as Go Fish.We can also support GROUP BY, ORDER BY, aggregate functions, etc.
For join support we have another technology (also not mentioned) called Global Tables. We replicate all Global Tables to every shard. This way each shard has the same schema, and joins are satisfied. We don't recommend cross-shard joins, but to date we have not had a use case that really required this.
If you would like more details, we'll be happy to provide them.
you Go-Fish and global table are alot like VoltDB multi-partition query and the "small replicated tables".
VoltDB is also alot like a sharding layer on top of in-memory sql DB.
that is the problem when sharding SQL you lose the relation power,so i rather have a database that has inline array datatype rather than a shard SQL db since there is no way for me to have a column with multiple values(which is would done in a normal db with one to many relation).
but i guess you can get away with most of the joins the way you described.
Uriel,
You can perform partitioned joins on a partition key in VoltDB. These do not have the overhead of a distributed join because only rows from a single partition need to be considered.
I assume that DbShards and Clustrix are also smart enough to do the right thing if you do a join on a partition key.
-Ariel Weisberg
VoltDB Engineering
Cory, I have a couple questions more:
1. SELECT count (distinct x) - do you support distinct in particular and holistic aggregates in general?
2. do you you support DBs other than MySQL?