













Pomegranate - Storing Billions and Billions of Tiny Little Files

Pomegranate is a novel distributed file system built over distributed tabular storage that acts an awful lot like a NoSQL system. It's targeted at increasing the performance of tiny object access in order to support applications like online photo and micro-blog services, which require high concurrency, high throughput, and low latency. Their tests seem to indicate it works:
We have demonstrate that file system over tabular storage performs well for highly concurrent access. In our test cluster, we observed linearly increased more than 100,000 aggregate read and write requests served per second (RPS).
Rather than sitting atop the file system like almost every other K-V store, Pomegranate is baked into file system. The idea is that the file system API is common to every platform so it wouldn't require a separate API to use. Every application could use it out of the box.
The features of Pomegranate are:
- It handles billions of small files efficiently, even in one directory;
- It provide separate and scalable caching layer, which can be snapshot-able;
- The storage layer uses log structured store to absorb small file writes to utilize the disk bandwidth;
- Build a global namespace for both small files and large files;
- Columnar storage to exploit temporal and spatial locality;
- Distributed extendible hash to index metadata;
- Snapshot-able and reconfigurable caching to increase parallelism and tolerant failures;
- Pomegranate should be the first file system that is built over tabular storage, and the building experience should be worthy for file system community.
Can Ma, who leads the research on Pomegranate, was kind enough to agree to a short interview.
Can you please give an overview of the architecture and what you are doing that's cool and different?
Basically, there is no distributed or parallel file system that can handle billions of small files efficiently. However, we can foresee that web applications(such as email, photo, and even video), and bio-computing(gene sequencing) need massive small file accesses. Meanwhile, file system API is general enough and well understood for most programmers.
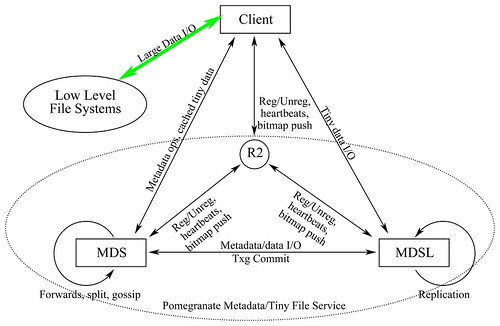
Thus, we want to built a file system to manage billions of small files, and provide high throughput of concurrent accesses. Although Pomegranate is designed for accesses to small files, it support large files either. It is built on top of other distributed file systems, such as Lustre, and only manage the namespace and small files. We just want to stand on ''the Shoulders of Giants". See the figure bellow:

Pomegranate has many Metadata Servers and Metadata Storage Servers to serve metadata requests and small file read/write requests. The MDSs are just a caching layer, which load metadata from storage and commit memory snapshots to storage. The core of Pomegranate is a distributed tabular storage system called xTable. It supports key indexed multi-column lookups. We use distributed extendible hash to locate server from the key, because extendible hash is more adaptive to scale up and down.
In file systems, directory table and inode table are always separated to support two different types of lookup. Lookups by pathname are handled by directory table, while lookups by inode number are handled by inode table. It is nontrivial to consistently update these two indexes, especially in a distributed file system. Meanwhile, using two indexes has increased the lookup latency, which is unacceptable for accessing tiny files. Typically, there are in memory caches for dentry and inode, however, the caches can't easily extend. Modifying metadata has to update multiple locations. To keep consistency, operation log is introduced. While, operation log is always a serial point for request flows.
Pomegranate use a table-like directory structure to merge directory table and inode table. Two different types of lookup are unified to lookups by key. For file system, the key is the hash value of dentry name. Hash conflicts are resolved by a global unique id for each file. For each update, we just need to search and update one table. To eliminate the operations log, we design and support memory snapshot to get a consistent image. The dirty regions of each snapshot can be written to storage safely without considering concurrent modifications.(The concurrent updates are COWed.)
However, there are some complex file system operations such as mkdir, rmdir, hard link, and rename that should be considered. These ops have to update at least two tables. We implement a reliable multisite update service to propagate deltas from one table to another. For example, on mkdir, we propagate the delta("nlink +1") to the parent table.
Are there any single points of failure?
There is no SPOF in design. We use cluster of MDSs to serve metadata request. If one MDS crashed, the requests are redirected to other MDSs(consistent hash and heartbeats are used). Metadata and small files are replicated to multiple nodes either. However, this replication is triggered by external sync tools which is asynchronous to the writes.
Small files have usually been the death of filesystems because of directory structure maintenance. How do you get around that?
Yep, it is deadly slow for small file access in traditional file systems. We replace the traditional directory table (B+ tree or hash tree) to distributed extendible hash table. The dentry name and inode metadata are treated as columns of the table. Lookups from clients are sent(or routed if needs) to the correct MDS. Thus, to access a small file, we just need to access one table row to find the file location. We keep each small file stored sequentially in native file system. As a result, one I/O access can serve a small file read.
What posix apis are supported? Can files be locked, mapped, symlinks, etc?
At present, the POSIX support is progressing. We do support symlinks, mmap access. While, flock is not supported.
Why do a kernel level file system rather than a K-V store on top?
Our initial objective is to implement a file system to support more existing applications. While, we do support K/V interface on top of xTable now. See the figure of architecture, the AMC client is the key/value client for Pomegranate. We support simple predicates on key or value, for example we support "select * from table where key < 10 and 'xyz' in value" to get the k/v pairs that value contains "xyz" and key < 10.
How does it compare to other distributed filesystems?
We want to compare the small file performance with other file systems. However, we have not tested it yet. We will do it in the next month. Although, we believe most distributed file systems can not handle massive small file accesses efficiently.
Are indexes and any sort of queries supported?
For now, these supports has not be properly considered yet. We plan to consider range query next.
Does it work across datacenters, that is, how does it deal with latency?
Pomegranate only works in a datacenter. WAN support has not been considered yet.
It looks like you use an in-memory architecture for speed. Can you talk about that?
We use a dedicated memory cache layer for speed. Table rows are grouped as table slices. In memory, the table slices are hashed in to a local extendible hash table both for performance and space consumption. Shown by the bellow figure,

Clients issue request by hash the file name and lookup in the bitmap. Then, using a consistent hash ring to locate the cache server(MDS) or storage server(MDSL). Each update firstly gets the *opened* transaction group, and can just apply to the in memory table row. Each transaction group changing is atomic. After all the pending updates are finished, the transaction group can be committed to storage safely. This approach is similar as Sun's ZFS.
How is high availability handled?
Well, the central server for consistent hash ring management and failure coordinator should be replicated by Paxos algorithm. We plan to use ZooKeeper for high available central service.
Other components are designed to be fault tolerant. Crashes of MDS and MDSL can be configured as recovered immediately by routing requests to new servers (by selecting the next point in consistent hash ring).
Operationally, how does it work? How are nodes added into the system?
Adding nodes to the caching layer is simple. The central server (R2) add the new node to the consistent hash ring. All the cache servers should act on this change and just invalidate their cached table slices if they will be managed by the new node. Requests from clients are routed to the new server, and a CH ring change notification will piggyback to client to pull the new ring from the center server.
How do you handle large files? Is it suitable for streaming video?
As described earlier, large files are relayed to other distributed file systems. Our caching layer will not be polluted by the streaming video data.
Anything else you would like to add?
Another figure for interaction of Pomegranate components.
 HighScalability Team
HighScalability Team
Reader Comments (6)
FWIW, and if you don't mind me borrowing a bit of your "Google juice" to promote it, I've written up some of my own thoughts about Pomegranate on my site. Thanks for finding this, and for writing up such a good intro.
Jeff,
Very good post. Can you elaborate how you get around the directory listing, file/directory renaming in your VoldFS?
Thanks Jeff. Good questions!
1. We originally claim “Pomegranate should be the first file system that is built over tabular storage” for the following reasons:
We have implement a truely tabular storage, named xTable, underlying Pomegranate. It supports query like to find a table cell. Thus, it is different from Ceph’s RADOS both in API and the internal implementation.
However, we do not notice your CassFS and VoldFS, and Artur Beergman’s PiakFuse. Therefor, we withdraw our claim to be the first one. Thanks for your reference:)
2. Actually, the small files’ data are not stored on underlying DFS, they are stored on our underlying tabular storage. We just relay large files to underlying DFS. Pomegranate manages both metadata and small files’ data.
3. For posix write, we do not guarantee the data hit disk on the return of write syscall. However, if we see a fsync, we trigger our caching layer to snapshot the memory image and commit the modifications to disk. We can also keep our promise that in 5 or other customized seconds later, the modified files will be on
disk. Thus, this 5 seconds promise can catch up with ext3. The small files’s data could be not cached in caching layer. In our test, we set file data write-through instead of write-back. However, in our test we also use our dynamic snapshot interval adjustment to delay the write-backs to absorb more metadata modifications.
4. Pomegranate supports POSIX readdir() operation. First, let me describe distributed extendible hash that we used in Pomegranate.
1) Tranditional extendible hash(EH) can extend by explot the two level indexes: the directory and buckets. On inserting, if the bucket is overflow, new bucket are generated to absort outflows. If bucket slots are full, the directory is extended exponentially. This approach is efficient both for small numbers of entries and for large numbers of entries.
2) We use GIGA+ like distributed extendible hash for locating a table slice (bucket in EH). The directory in EH is represented as a distributed bitmap. Each bits means a bucket exists or not.
On list a directory, the client firstly request to get the most accurate bitmap of the directory. Then, it use this bitmap to iterate and retrieve the existing table slices. Each table slice contains some table rows(fs’s directory entries).
5. We have optimize complex operations such as mkdir, rmdir, hard link. While, rename is not optimized yet. It is slow for now. Yep, the reliable update service should be the qualitative change from tabular storage to file system. In general, the update service accepts delta update requests and execute as follows:
1) log the delta updates to disk in source site’s snapshot;
2) transfer the delta updates to sink site’s memory;
3) update sink site’s memory;
4) commit to disk in sink site’s snapshot;
5) sink site acknowledge the request to source site;
6) mark in the log that the update completed.
There are so many stages in the execution, however, the node failures can be recovered from the logs, memory state, and on-disk state. It is truely very complex, and implementation and validation are on-going.
Thanks for your constructive questions! We are glad to receive your valuable feedbacks:)
Hi, Can Ma. Thanks for providing these clarifications, and thanks even more for the interesting work behind them. If you don't mind, I'd like to follow up further on a couple of points.
(1) If xTable provides query-like operations to find a single cell, how would you compare Pomegranate to some of the database-backed filesystems such as Oracle's DBFS?
(3) I mean no offense to you or ext3's authors, but ext3 sets a pretty low standard in terms of data protection. For a production environment, I and many others would demand something significantly better. Given the I/O rates that are common even on cheap commodity systems nowadays, a five-second window is often unacceptably large.
(4) That seems like a sound approach to directory listing, not entirely dissimilar to how I handled the same issue in VoldFS. How do you deal with uneven distribution of entries e.g. when files are created in lexical order?
(5) If there's one thing I'd like to remove from the POSIX spec, it's rename across directories. Renames within a directory are reasonable enough, but renames (really moves) across directories are very difficult to implement well and it's not worth it because all sane applications already avoid them or have their own way to deal with EXDEV failures when the directories are on separate mountpoints.
(P.S. I responded to Juri over at my site because that question was about my own work rather than Can Ma's.)
Thanks Jeff. The approach of directory listing in VoldFS is interesting.
1) I think the most important difference between Pomegranate and traditional database-backed file systems is that Pomegranate may be more scalable. It is difficult to scale a thick ACID DB. Meanwhile, the metadata and tiny file services of file system are very latency sensitive. We expect the NoSQL manner that xTable adopts can be more lightweight than relational DBs. This is also the reason why supply a caching layer.
3) All right. Five-second guarantee maybe sufficient for desktops, it cannot satisfy strictly data reliability demands in production environments. In Pomegranate, we introduce the caching layer initially for serving read-dominant requests, e.g. the online photo service. In QZone's Photo Album (a popular photo service from Tencent), almost 100 million images are uploaded every day (about 1157 uploads per second). While, there are about 20,000 downloads served per second. A caching layer reduces the metadata query latency significantly. Moreover, these applications require more metadata consistency than strictly data reliability. For example, a missing photo can be re-uploaded by user, while inconsistent metadata will bore users.
4) For now, range queries in Pomegranate cannot be well handled. For uneven distribution of entries, we have tried many hash functions, such as murmurhash, to got a uniform value space from entry names. In our test, clients create files in pattern "client-xnet-test-[seqno of files]-[dir id]-[siteid]". Thus, all the file names look similar. We have observed that the hash value is evenly distributed on the cluster (except 2 or 3 nodes with fewer entries). The approaches used in VoldFS and Pomegranate are similar. File names are hashed for both quickly locating and uniform distribution. For range query, I think the B-tree-ish approach used in VoldFS is saner than the distributed extendible hash approach used in Pomegranate. By using an order preserving hash function F, it is fast to locate and iterate on the given range in B-tree. While, it is difficult to preserve the storage order of entries in EH even using hash F.
5) Yep, I agree with you.
Last news are from 2010... Is this project dead?