













Strategy: Exploit Processor Affinity for High and Predictable Performance
Martin Thompson wrote a really interesting article on the beneficial performance impact of taking advantage of Processor Affinity:
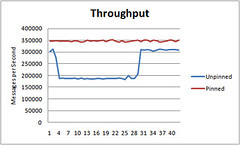
The interesting thing I've observed is that the unpinned test will follow a step function of unpredictable performance. Across many runs I've seen different patterns but all similar in this step function nature. For the pinned tests I get consistent throughput with no step pattern and always the greatest throughput.
The idea is by assigning a thread to a particular CPU that when a thread is rescheduled to run on the same CPU, it can take advantage of the "accumulated state in the processor, including instructions and data in the cache." With multi-core chips the norm now, you may want to decide for yourself how to assign work to cores and not let the OS do it for you. The results are surprisingly strong.
 HighScalability Team
HighScalability Team
Reader Comments (5)
This is important for sharded applications. Sharding down to the node level means you have a mismatch between your sharding strategy and the actual communication costs of the underlying hardware. I think that sharding applications down to sockets is the way to go since you have already eaten the pain of sharding.
CPUs will always have groups of cores that share a cache where thread communication and migration is cheaper and it make sense to express this affinity with groups of threads that are pinned to the groups of cores.
Being too restrictive when pinning threads can have unintended consequences WRT to latency. You restrict the scheduler's options and it may choose to not schedule you immediately in order to satisfy it's own ideas of what is best. Schedulers also can't understand your latency/throughput requirements unless you muck with thread priority. It just so happens that on a loaded system the threads servicing the latency sensitive workload will also be doing the most work and thus receive the worst treatment when a background task comes up for air.
If there is a 1:1 relationship between application threads and cores you will get predictable behavior, but then you end up implementing your own scheduler to support fine grained interleaving of background tasks with foreground tasks that are latency sensitive.
You could also incorporate this into the OS to do it for you. z/OS has had Hiperdispatch available for some time now, which does this processor and book* affinitiy management for you.
Surely some bright spark in Linux kernel development could code this?
* In System z hardware a book is a physical card which contains processor engines and real storage (RAM)
Peter Lawrey has an open source library for java to achieve this at a finer level of control thank taskset.
https://github.com/peter-lawrey/Java-Thread-Affinity
Think about "Affinity" and "pinning" at many levels. If each server can Cache all of the pages it serves it will perform better. As described in this post, the thread reuses state.
The same is true at the server sharding level. If I could shard out the pages of a site so each server only serves pages that fit in the local cache, then, performance would be higher.
Apply the same ideas to Database and NoSQL. Keep the "Affinity" of the data set in mind as you shard...
@ariel: well, the idea is to set aside x of your n cores (x << n) for system work (e..g background procs) and dedicate the rest to 'work'.
Thompson's observations are valid but the real standing issue is that we are still programming on POSIX and malloc. There is /no/ semantic injection from user to kernel space beyond parent/child (for processes) and time-locality (for memory allocations). The upshot is that per Amdahl's Law, it is /very/ difficult to conceive of a (richer) alternative that would present a reasonable complexity-of-code and performance-gain relationship.
Another contemporary fact is the prevalence of hypervisors and pervasive virtualization. It is difficult to have "mechanical sympathy" when sitting on n layers of virtualization.
For niche/specific problems, the mechanical sympathy approach is well worth taking: you have a specific deployment environment and are making specific tunings. But it is a blind ally if there is a disconnect to the virtual platform.