













Part 2: The Cloud Does Equal High performance

This a guest post by Anshu Prateek, Tech Lead, DevOps at Aerospike and Rajkumar Iyer, Member of the Technical Staff at Aerospike.
In our first post we busted the myth that cloud != high performance and outlined the steps to 1 Million TPS (100% reads in RAM) on 1 Amazon EC2 instance for just $1.68/hr. In this post we evaluate the performance of 4 Amazon instances when running a 4 node Aerospike cluster in RAM with 5 different read/write workloads and show that the r3.2xlarge instance delivers the best price/performance.
Several reports have already documented the performance of distributed NoSQL databases on virtual and bare metal cloud infrastructures:
-
Altoros Systems examined the performance of different NoSQL databases on Amazon Extra Large Instances in a report titled “A Vendor-independent Comparison of NoSQL Databases: Cassandra, HBase, MongoDB, Riak”.
-
Thumbtack Technology examined the performance of different NoSQL databases (Aerospike, MongoDB, Cassandra and Couchbase) on bare metal in pure RAM and on SSDs in a report titled “Ultra-High Performance NoSQL Benchmarking”.
-
More recently, the CloudSpectator report titled “Performance Analysis: Benchmarking a NoSQL Database on Bare-Metal and Virtualized Public Cloud”, examined performance of Aerospike on Internap’s bare-metal servers and SSDs as well as on Amazon EC2 and Rackspace clouds.
For this series of experiments we tested Amazon instances using a 4 node Aerospike cluster with data in memory (RAM), and 5 real world workloads - from 100% writes, 50/50 balanced reads/writes, 80/20 and 95/5 to 100% reads. In addition, instead of 1 node, 100% reads and 10 Million objects used in the first post, in this experiment, we used 40 Million objects and the 4 node Aerospike cluster with mixed reads and writes was doing more work than the single node, to ensure synchronous replication and immediate consistency.
We used the following 4 Amazon instances:
-
m1.large: Previous generation
-
m3.xlarge: Current generation without enhanced network
-
r3.2xlarge: Current generation
-
r3.large: Current generation to validate linear scaling,
running a 80/20 workload on a 2,4,6,8 node cluster)
Result 1: Amazon r3.* scales Aerospike cluster TPS linearly with percentage of reads 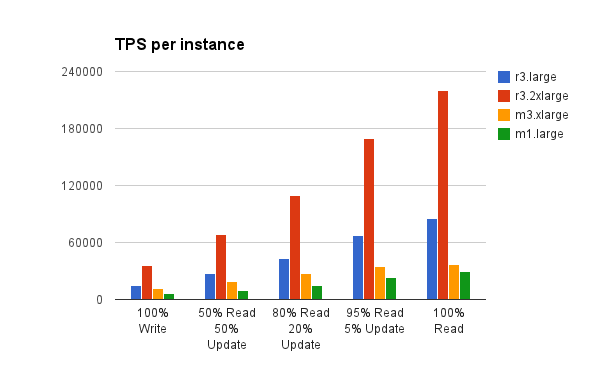
(Higher is better)
On a 4 node Aerospike cluster, the Amazon r3.* instance delivers the highest throughput across workloads and scales linearly with the percentage of reads. Other instance types bottleneck on the network and cannot push higher amounts of reads
Result 2: Amazon latencies vs TPS per instance
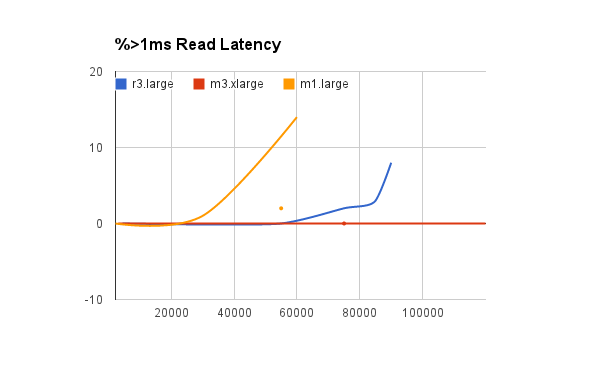
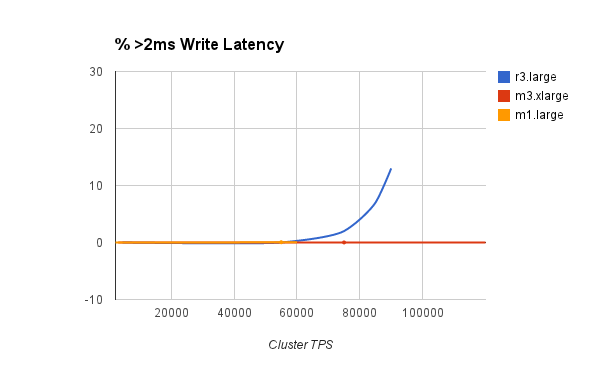
(Lower is better)
Each Amazon instance has a limited number of requests that can be processed with low latency. Once the limit is reached even though higher throughput can be achieved, latency characteristics deteriorate rapidly.
Result 3: Amazon r3.large scales Aerospike TPS linearly on just a handful of nodes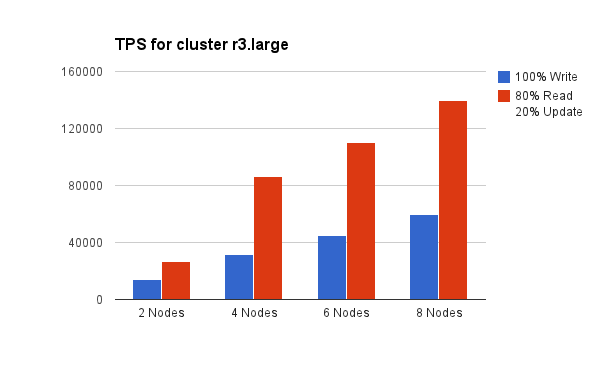
(Higher is better)
On Amazon r3.large and a 80/20 read/write workload, Aerospike TPS scales linearly from 27k TPS on two nodes to 140k TPS on just 8 nodes.
Result 4: Comparing Number of Nodes vs TPS across Amazon Instances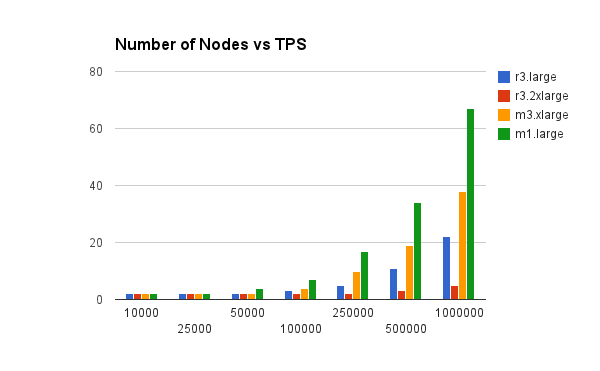
(Lower is better)
Result 5: Amazon r3.2xlarge shows optimal price/performance with Aerospike
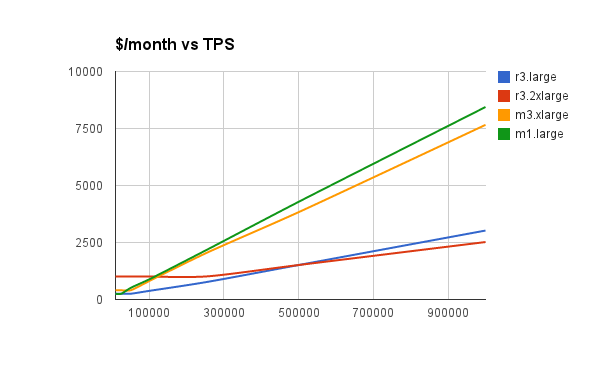
(Lower is better)
Depending on the instance, 2-67 nodes are required to deliver performance ranging from 15k TPS to 1 Million TPS, for prices starting at just $252 per month to $8552 per month. Costs can go down further with yearly reservation and this graph shows that the best Amazon instance for Aerospike is the r3.large or r3.2xlarge, with r3.2xlarge requiring slightly fewer nodes and lower costs for the same performance.
We have documented the steps so that you too can validate the performance of Amazon instances and reproduce results that show linear scalability, extremely high throughput and predictable low latency with Aerospike on Amazon.
Step by Step Setup
-
Setup Instances for Servers: Bring up Aerospike on 4 Amazon instances of the same type in the same availability zone for each Aerospike server. You can use AWS Marketplace to create these instances. You should use an instance which supports enhanced networking and VPC is a prerequisite for using HVM with enhanced networking. The security group should allow ports 3000-3003 for Aerospike within the instances and 8081 for AMC from the internet.
-
Setup Aerospike:
-
Setup mesh configuration to make a 4 node Aerospike cluster.
-
Run afterburner.sh (cd /opt/aerospike/bin; sudo ./afterburner.sh) to set the optimal number of threads on each Aerospike server.
-
-
Setup System:
-
Make sure RPS is enabled for the ethernet card. This can be configured for eth0 by running command echo f | sudo tee /sys/network/eth0/rx-0/rps_cpus
-
-
Setup Instances for Clients: Bring up 4-8 Amazon instances for client machines. i.e For a 4 node Aerospike cluster, use 4 client instances of the same class or 8 instances of the next best class e.g for a C3.8xlarge server instance, 8 C3.4xl instances may be needed to push enough load.
-
Install java benchmark client on the client instances. Use one of the boxes to run AMC service.
-
Start the cluster on the server instances and let the migration finish. You can check migration progress in AMC.
-
Load 40 million records, each 100 bytes in size (10 bins each of 10 bytes). Run the sample Java Benchmark command:
cd <java client>/benchmarks./run_benchmarks -z 40 -n test -w I -o S:10 -b 10 -l 23 -k 40000000 -latency 5,1 -h YOUR_AWS_INTERNAL_IP - Fire up, from multiple java benchmark clients, the uniform distribution workload. (We used a single client on r3.8xlarge as it was enough for our loading requirement).
Run the Tests Yourself
We have published a cloud formation script - which should take care of spinning up server and client instances and setup up the Aerospike cluster. Follow instruction in the README to try it yourself. This should be quick and cost you 1 hour worth of instance time that is $5.60 ($2.8 each for servers and clients).
Related Articles
- 1 Aerospike Server X 1 Amazon EC2 Instance = 1 Million TPS For Just $1.68/Hour
- The Quest For Database Scale: The 1 M TPS Challenge - Three Design Points And Five Common Bottlenecks To Avoid
- Russ’ 10 Ingredient Recipe For Making 1 Million TPS On $5K Hardware
- Switch Your Databases To Flash Storage. Now. Or You're Doing It Wrong
 HighScalability Team
HighScalability Team
Reader Comments (10)
I like the architecture of Aerospike, and I would like to use it in my production. But, it's too JAVA oriented and since I use PHP language, I can't implement it as the way I want. Because there are many differences between JAVA and PHP clients.
Unlike JAVA client, their PHP client is too out-dated and that limits my application. Let me explain with the following examples;
http://www.aerospike.com/docs/client/php/examples/
http://www.aerospike.com/docs/client/java/examples.html
delete SET support for JAVA: https://github.com/aerospike/delete-set
delete SET support for PHP: None
set "SET -> KEY , VALUE" for JAVA: natural
set "SET -> KEY , VALUE" for PHP: not natural -> you have to command in client side ~ $client->set_default_set('myset') every time before you set a value.
Why not like this: $client->set('myset', 'key', 'value'); ?
+ It would be good to pay attention to have pure PHP client, so we can use it on HHVM as an alternative to Redis.
The PHP client offers features that similar to basic key, value storage like Memcache. You can't really take the advantage of Aerospike data hierarchy with the current PHP client. Too bad, the only JAVA client offers advanced features.
I hope, I get any response from this issue. Because I don't want to create an account at their website to just report this problem.
BTW, Thanks for the post, looks impressive.
Hi, great work, thanks for it !
Why benchmarking only things in-memory ?
I mean does this use case represent a large portion of your users ?
One of the hardest balance we have to maintain, using AWS at least, is between amount of data, throughput and price. Why not doing a similar benchmark but taking into consideration the (most common ?) use case you have to store some data. Let's say 20 TB in your cluster and showing a matrix of cost / Throughput performance depending on machines in use ?
I think this would answer to more common use case. Actually just adding the necessity of keeping some data in memory will change the results of your test. r3.2xLarge only have 160 GB disk available, so are actually a really poor choice for database that don't fit in memory while I2 are worth speaking of, maybe are also m1.xLarge instances, HDD based...
An other reason is that will allow us comparing things easily with direct concurrents like Cassandra, since the community edition of Cassandra has no In memory option built in.
@Alain Rodriguez: I can't answer your questions about Aerospike paper, but Cassandra does support memory caches (built-in). Search for; Cassandra "row cache" and "key cache".
As an addition to my previous comment, they have no published PHP client officially. See: https://github.com/aerospike/?query=php
http://www.datastax.com/2014/02/why-we-added-in-memory-to-cassandra
DSE, package based on Apache Cassandra does, AFAIK Cassandra don't. Having some row and key cached is not enough to say that the database is "In Memory". Actually, if you have row cache, it is that you also have data in disk and you loaded it at some point. An in memory Cassandra would keep all the data into big memtables (RAM) and would not need any row cache.
At least that's the grasp I have about it.
Re: Aerospike PHP API
Dear no-author,
Our updated PHP implementation will be available shortly. I had reached out to various PHP developers, people who know PHP internals, and we had no real luck on that front. Made a key hire a few months ago, and some contractors, and have made a lot of progress. I realize this may not be fast enough for you, and my apologies, but we're on our way to a solid PHP client.
Our C#, Go, Node, C clients are all well used and well loved by developers.
Ruby is another language that we had a while ago, and are now updating - right after PHP.
Brian Bulkowski, CTO and founder
@Alain Rodriguez: "Having some row and key cached is not enough to say that the database is "In Memory". "
That's right of course... "memory caches != in memory DB" Actually, I didn't mean; Cassandra is in memory database, but you have some possibilities around it "as you already know".
@Brian Bulkowski: I'm glad to hear the good news, looking forward to implement, test and benchmark it in my application :)
One last question; is it possible to create Aerospike HHVM extension at the same time ? My application is able to use HHVM with no performance issue as it has been developed with HHVM performance in mind "no global, variable variable, top level code etc.."
BTW, HHVM supports Redis; https://gist.github.com/clue/8645729
So, any chances for Aerospike HHVM support ? :)
Thanks.
@ Alain,
Our original exercise started with trying to figure out how does AWS fair when trying to do as much as that can be and of course how AeroSpike performs in those cases. So first benchmark was in memory to remove io boundedness from the equation. Of course there are lot of caching use cases where velocity and latency (real time) are biggest concern
We have already done quite a bit of experimentation with persistence in AWS. Aerospike is optimized to run with SSD so our experiments were only with SSD.
Direct attach SSD are ephemeral the durability span of persistence on it is duration of instance. Newer instances and also higher instances (4x and above) generally are pretty reliable. But it cannot be trusted for the situations like availability zone going down (there is precedence). So there are two models of persistence.
1. Replicate across availability zone
2. Put the data on EBS ssd.
Both have pros and cons of its own. Across availability zone every byte transfer is a cost. Replication traffic and in case of failure application traffic may go over availability zone for data which could cost a lot.
Though the behavior of direct attach ssd is pretty good, the EBS ssd has iops restriction and much poor latency characteristic ... If reads were to go directly to EBS, that would hit the millisecond SLA which is unacceptable.
We very early in Aerospike realized caching some part of data is enemy of predictability so all data has to be equal. One of the solution considered is multi level storage where entire direct attach ssd is seen as RAM and work with data in memory kind of setup and put data on EBS in the background. Making it much more seamless than manual snapshot and restore.
You are correct when you say real challenge is the balance between data and cost. One more dimension to it is reliability as well.
We will publish what we found in much more detail in another post someday.. Keep watching the space :)
Raj
This looks awesome, but it is a shame that Aerospike had discontinued support of their lib event based c client, and that their Python client is blocking vs asynchronous.
I've checked the PHP Client of Aerospike tonight and saw that they NOW have a NEW PHP Client. :)
So, I'm going to code some cool stuff :P
http://www.aerospike.com/docs/client/php/start/