













Building nginx and Tarantool based services
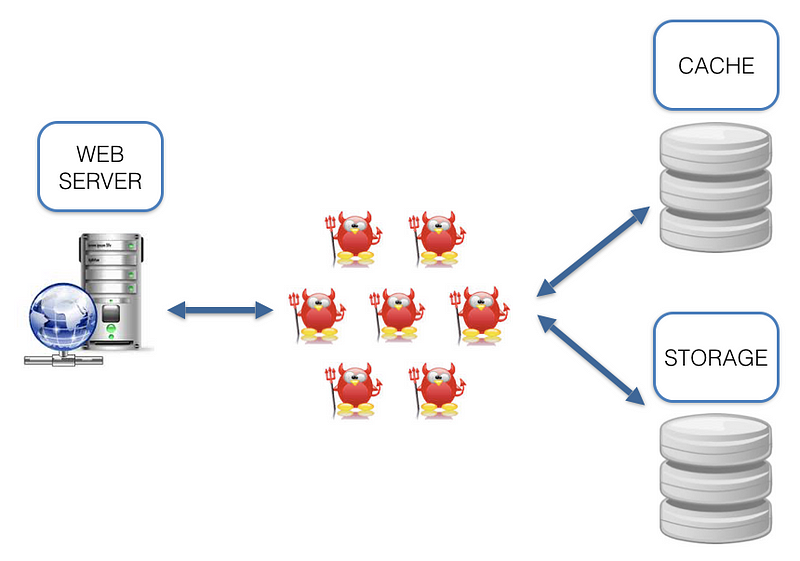
Are you familiar with this architecture? A bunch of daemons are dancing between a web-server, cache and storage.
What are the cons of such architecture? While working with it we come across a number of questions: which language (-s) should we use? Which I/O framework to choose? How to synchronize cache and storage? Lots of infrastructure issues. And why should we solve the infrastructure issues when we need to solve a task? Sure, we can say that we like some X and Y technologies and treat these cons as ideological. But we can’t ignore the fact that the data is located some distance away from the code (see the picture above), which adds latency that could decrease RPS.
The main idea of this article is to describe an alternative, built on nginx as a web-server, load balancer and Tarantool as app server, cache, storage.
Improving cache and storage
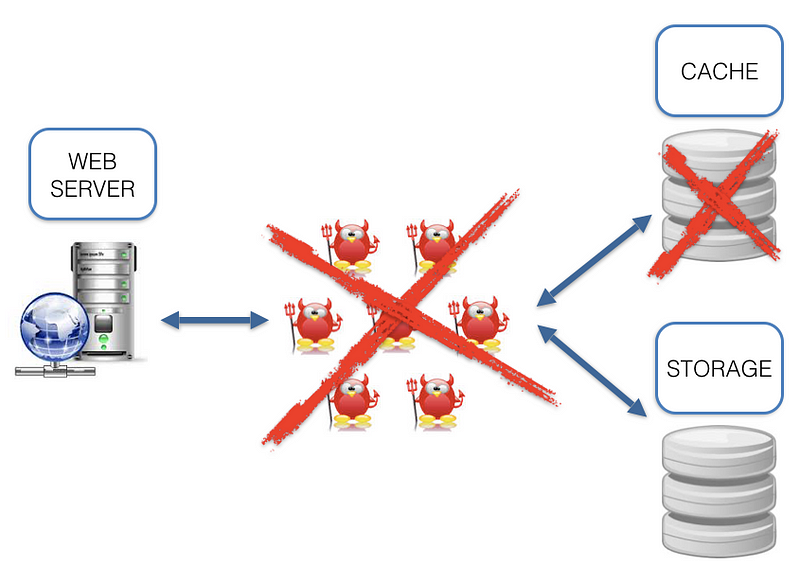
Tarantool has a number of interesting features. Tarantool isn’t just an efficient in-memory DB, but also a fully functional app server; applications are created on Lua (luajit), C, or C++, which means that any logic, no matter how complex, can be created and your fantasy is a limit. If the amount of data exceeds the memory limit, then it can be partially stored on disk using Sophia. Sophia is an optional feature so if you need to use something else then you can store the hot parts of data in-memory and the cold part of data in some other storage system. What are the benefits?
- No “third parties”. The hot data part is located on the same level with the code.
- Hot data in-memory
- Lua applications are simple and easily updated
- Safe and production ready - Tarantool supports transactions, replication, and sharding
Improving web-server
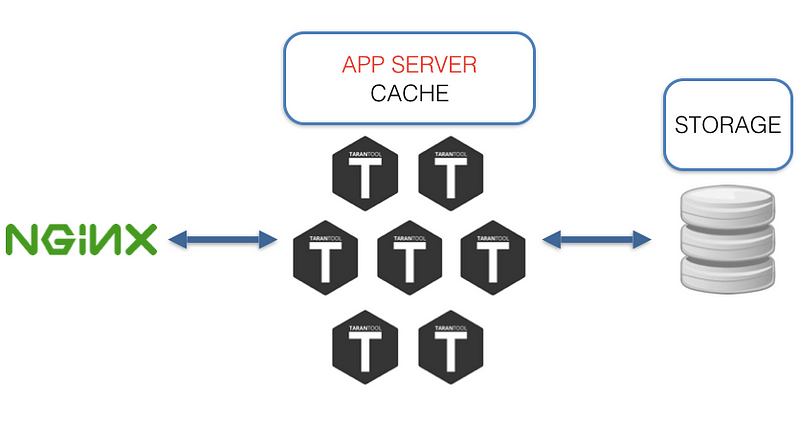
The ultimate data consumer is your user. Usually the user receives data from app server via nginx as a balancer/proxy. The option of creating a daemon capable of communicating with both Tarantool and HTTP wouldn’t work, as it brings us back to the first image where we started. So let’s try to look at this situation from a different angle and ask ourselves another question: “How to get rid of the third party between the data and the user?” The answer to this question was our implementation of the Tarantool nginx upstream module.
About nginx upstream
Nginx upstream is a persistent connection via pipe/socket and backend referred to below as “proxying”. Nginx offers a variety of features for creating the upstream rules; the following possibilities become of key importance for HTTP proxying in Tarantool:
- Load balancing across many Tarantool instances via nginx upstream
- The possibility to have a backup
All these make it possible to:
- Distribute the load across Tarantool instances; for example, together with sharing you can build a cluster with an even load distribution between nodes
- Create a fault tolerance system with the help of Tarantool replication
- Using item 1 and 2 to get a fault tolerance cluster
An example of nginx configuration that partially illustrates the capabilities of Tarantool and nginx:
# Proxying settings in Tarantool
upstream tnt {
server 127.0.0.1:10001; # first server located on localhost
server node.com:10001; # second someplace else
server unix:/tmp/tnt; # third via unix socket
server node.backup.com backup; # here backup
}
# HTTP-server
server {
listen 8081 default;
location = /tnt/pass {
# Telling nginx that we need to use Tarantool upstream module
# and specify the name upstream
tnt_pass tnt;
}
}
More information on nginx upstream configuration can be found here: http://nginx.org/en/docs/http/ngx_http_upstream_module.html#upstream
About nginx Tarantool upstream module
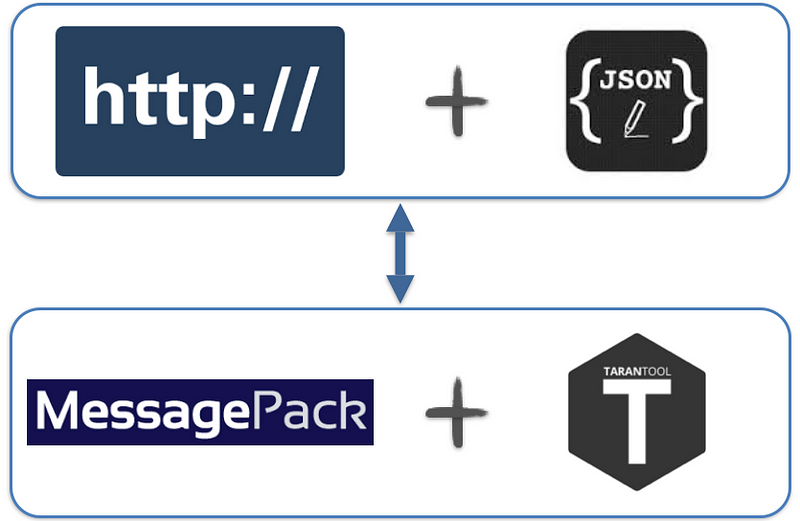
The main features
- The module is activated in nginx.conf by tnt_pass command
- Transform HTTP+JSON to Tarantool protocol
- Non-blocking I/O in both directions
- All nginx and nginx upstream features
- The module allows you invoke stored Tarantool procedures via a JSON-based Protocol
- The data is delivered through HTTP(S) POST, which is convenient for modern web-apps and not only for them
Input data
[ { “method”: STR, “params”:[arg0 … argN], “id”: UINT }, …N ]
“method”
The name of a stored procedure. The name should match the procedure name in Tarantool. For example, to invoke the lua-function do_something(a, b), we need: “method”: “do_something”
”params”
The arguments of a stored procedure. For example, to send the arguments to the lua-function do_something(a, b), we need: “params”: [ { “field1”: [ {“a”: ”b”} ], 2 ]
“id”
Numerical identifier; set up by a user
Output data
[ { “result”: JSON_RESULT_OBJECT, “id”:UINT, “error”: { “message”: STR, “code”: INT } }, …N ]
“result”
The data returned by a stored procedure. For example, lua-function do_something(a, b) brings back: return {1, 2} то “result”: [[1, 2]]
“id”
Numerical identifier; set up by a user
“error”
In case an error occurs, the information on what caused it will be shown here
Let’s try it
Starting up nginx
$ git clone https://github.com/tarantool/nginx_upstream_module.git
$ cd nginx_upstream_module
$ git submodule update -init -recursive
$ git clone https://github.com/nginx/nginx.git
$ cd nginx && git checkout release-1.9.7 && cd -
$ make build-all-debug
“build-all-debug” is a debug-version. We are aiming at less nginx configuration. For those who want to configure from scratch, there is a “build-all”.
$ cat test-root/conf/nginx.conf
http {
# Adds one Tarantool server as a backend
upstream echo {
server 127.0.0.1:10001;
}
server {
listen 8081 default; #goes to *:8081
server_name tnt_test;
location = /echo { # on *:8081/echo we send ‘echo’
tnt_pass echo;
}
}
}
$ ./nginx/obj/nginx # starting up nginx
Starting up Tarantool
Tarantool can be set up with packages or built.
-- hello-world.lua file
-- This is our stored procedure, it’s fairly simple and it doesn’t use Tarantool as a DB.
--All it does — is just returning its first argument.
function echo(a)
return {{a}}
end
box.cfg {
listen = 10001; -- Specifying the location of Tarantool
}
box.schema.user.grant('guest', 'read,write,execute') -- Give access
If you set up Tarantool with packages, you can start it up this way:
$ tarantool hello-world.lua # the first argument is the name of lua-script.
Invoking the stored procedure
Echo stored procedure can be invoked by any HTTP-connector; all you need to do — HTTP POST 127.0.0.1/echo and in the body there will be the following JSON (see Input Data)
{
"method": "echo", // Tarantool method name
"params": [
{"Hello world": "!"} // 1 method’s argument
],
"id": 1
}
I’ll invoke this procedure with wget
$ wget 127.0.0.1:8081/echo — post-data '{"method": "echo","params":[{"Hello world": "!"}],"id":1}'
$ cat echo
{"id":1,"result":[[{"hello world":"!"}]]}
Other examples:
- https://github.com/tarantool/nginx_upstream_module/blob/master/examples/echo.html
- https://github.com/tarantool/nginx_upstream_module/blob/master/test/client.py
Let’s sum it up
The pros of using Tarantool nginx upstream module
- No “third parties”; as a rule, the code and the data are on the same level
- Relatively simple configuration
- Load balancing on Tarantool nodes
- High performance speed, low latency
- JSON-based protocol instead of binary protocol; no need to search for Tarantool driver, JSON can be found anywhere
- Tarantool Sharing/Replication and nginx = cluster solution. But that’s the topic for another article
- The solution is used in production
The cons
- Overhead JSON instead of more compact and fast MsgPack
- It’s not a packaged solution. You need to configure it, to think how to deploy it
Plans
- OpenResty and nginScript support
- WebSocket and HTTP 2.0 support
The benchmark results - which are actually pretty cool- will be in a different article. Tarantool and Upstream Module is open source and welcoming to new users. If you wish to try it out, use it or share your ideas, go to GitHub, google group.
Links
Tarantool — GitHub, Google group
 Dmitriy Kalugin-Balashov
Dmitriy Kalugin-Balashov
Reader Comments (8)
I'm very familiar with Nginx but had never heard ot Tarantool...great info! I'll have to play around with Tarantool.
Is the sharding stable/production-ready ?
So the benchmarks were interesting. They beat redis (hands down) at 95% rewrite benchmarks?!?! No way!
So their config is on githib and they have this set:
no-appendfsync-on-rewrite no
So on every rewrite, it is forcing an fsync to the AOF write and causing huge request latency for rewrite latency and throwing the benchmark. I'm pretty sure their system isn't fsyncing on every single request or it wouldn't be outperforming redis by such a huge factor.
Looks like some really interesting technology, but I don't yet get how it is better than redis.
Sharding in Tarantool is stable but it does not have resharding. So if a node is down and you want to replace it or if you need to join a new node to a cluster then you need to do this with your own hands. We expect the complete sharding-resharding solution in the 1.7 version which is in active development right now.
About Redis and fsync and this kind of stuff. Tarantool doesn't fsync on each write by default (although you can turn it on) but it does call write/writev syscal on each update before a client gets an answer. Redis doesn't do that way because it writes to disk in all async mode. That is to say you never know if your update hits the disk or not with Redis. With Tarantool you know for sure that your update has gotten through the write/writev syscall if a client gets a response from Tarantool.
So Tarantool is a real transactional databases that writes each update on disk with additional possibility of turning on fsync. And even being a real databasee and getting everything through the write/writev syscall Tarantool is still faster than Redis.
@Dennis
Thanks for the reply. That is very useful information. I figured that particular benchmark wasn't entirely fair. I think it should be updated to show redis in a closer comparison, although it still isn't comparing apples to oranges and the performance of Tarantool is impressive.
Redis can be configured to fsync to the AOF before a result is returned to the client, however even then it is in batches so potentially hundreds of requests could fsync together in a high load server. Even so, it isn't the same thing as write/writev before returning success.
This is really interesting technology. I'm excited to learn more!
@Nick
Unique features of TNT compared to Redis, IMO, are built-in sharding/replication as well as the Sophia storage engine for larger databases that don't fit in memory.
Indexing is quite rudimentary, but more useful than e.g. RethinkDB. They have a project to integrate a fork of SQLite on top of TNT (a la http://www.actordb.com/docs-howitworks.html) which seems interesting though.
And of course unlike e.g. ArangoDB, stored procedures in TNT are in Lua and not Javascript which translates to smaller memory overhead.
On a side note, there is an openresty driver on github, I've been using it with the Lapis framework which runs inside nginx.
Hats off to the tarantool guys :)
@Nick
Another interesting fact about Tarantool is that its API is fully asynchronous. So you can send requests and read responses through one socket in parallel. This way Tarantool achieves fantastic throughput of 1 million transactions per second per CPU core. Which is possible because async API helps to pack many requests into a single TCP segment and again to get many responses in a single TCP segment. Of course you know that one of the main bottlenecks of database systems is context switching between threads and context switching at system calls. You can apply changes to the hash table or other in-memory structure tens million times per sec, but unfortunately you need to do lots of syscalls until you reach these fast in-memory structures. So with Tarantool using an async client you minimize overhead of syscalls and context switching. Which is very close to proprietary in-memory DBMS solutions.
Speaking of proprietary in-memory solutions, you can run programs inside Tarantool using Lua language or C language. Which should be as fast as your own specific solution and even faster. Lua/C stored procedures increase already great throughput. And again Lua/C programs inside Tarantool are fully asynchronous and fully non-blocking. Say, if one Lua script is blocking on a network operation another Lua script can do some math on the same CPU core. As the icing on the cake each Lua script is performed in a "all-or-nothing" manner. Firstly it performs all the changes in memory in a temporary area then commits them to disk and if a commit is successful then it immediately makes that temporary changes visible to all other transactions.
Saying Transactions I mean the real transactions that are ACID and that hit the disk at least via write/writev syscall. I'm gonna shot a quick video demo how to setup a test and how to setup Tarantool on AWS micro instance. You can like our Facebook group here: https://www.facebook.com/TarantoolDatabase/ and follow all the news and demos.
It's 2020.. is there any news regarding http 2.0?