













Performance and Scaling in Enterprise Systems
This is a guest post from Vlad Mihalcea the author of the High-Performance Java Persistence book, on the notion of performance and scalability in enterprise systems.
An enterprise application needs to store and retrieve as much data and as fast as possible. In application performance management, the two most important metrics are response time and throughput.
The lower the response time, the more responsive an application becomes. Response time is, therefore, the measure of performance. Scaling is about maintaining low response times while increasing system load, so throughput is the measure of scalability.
Response time and throughput
The transaction response time is measured as the time it takes to complete a transaction, and so it encompasses the following time segments:
- the database connection acquisition time
- the time it takes to send all database statements over the wire
- the execution time for all incoming statements
- the time it takes for sending the result sets back to the database client
- the time the transaction is idle due to application-level computations prior to releasing the database connection.
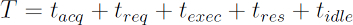
Throughput is defined as the rate of completing incoming load. In a database context, throughput can be calculated as the number of transactions executed within a given time interval.
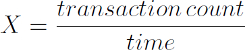
From this definition, we can conclude that by lowering the time it takes to execute a transaction, the system can accommodate more requests.
Lowering response time allows a database connection to be released sonner, therefore accommodating more transactions per second. However, response time alone is not sufficient in a highly concurrent environment. To maintain a fixed upper bound response time, the system capacity must increase relative to the incoming request throughput. Adding more resources can improve scalability up to a certain point, beyond which the capacity gain starts dropping.
Capacity planning is a feedback-driven mechanism, and it requires constant application monitoring, and so, any optimization must be reinforced by application performance metrics.
Scaling up and scaling out
Scaling is the effect of increasing capacity by adding more resources. Scaling vertically (scaling up) means adding resources to a single machine. Increasing the number of available machines is called horizontal scaling (scaling out).
Traditionally, adding more hardware resources to a database server has been the preferred way of increasing database capacity. Relational databases have emerged in the late seventies, and, for two and a half decades, the database vendors took advantage of the hardware advancements following the trends in Moore's Law.
Distributed systems are much more complex to manage than centralized ones, and that is why horizontal scaling is more challenging than scaling vertically. On the other hand, for the same price of a dedicated high-performance server, one could buy multiple commodity machines whose sum of available resources (CPU, Memory, Disk Storage) is greater than of the single dedicated server. When deciding which scaling method is better suited for a given enterprise system, one must take into account both the price (hardware and licenses) and the inherent developing and operational costs.
Being built on top of many open source projects (e.g. PHP, MySQL), Facebook uses a horizontal scaling architecture to accommodate its massive amounts of traffic.
StackOverflow is the best example of a vertical scaling architecture. In one of his blog posts, Jeff Atwood explained that the price of Windows and SQL Server licenses was one of the reasons for not choosing a horizontal scaling approach.
No matter how powerful it might be, one dedicated server is still a single point of failure, and throughput drops to zero if the system is no longer available. Database replication is therefore mandatory in most enterprise systems.
Master-Slave replication
For enterprise systems where the read/write ratio is high, a Master-Slave replication scheme is suitable for increasing availability.
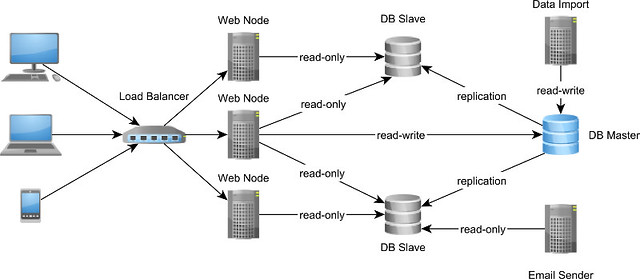
The Master is the system of record and the only node accepting writes. All changes recorded by the Master node are replayed onto Slaves as well. A binary replication uses the Master node WAL (Write Ahead Log) while a statement-based replication replays on the Slave machines the exact statements executed on Master.
Asynchronous replication is very common, especially when there are more Slave nodes to update. The Slave nodes are eventual consistent as they might lag behind the Master. In case the Master node crashes, a cluster-wide voting process must elect the new Master (usually the node with the most recent update record) from the list of all available Slaves.
The asynchronous replication topology is also referred as warm standby because the election process does not happen instantaneously.
Most database systems allow one synchronous Slave node, at the price of increasing transaction response time (the Master has to block waiting for the synchronous Slave node to acknowledge the update). In case of Master node failure, the automatic failover mechanism can promote the synchronous Slave node to become the new Master.
Having one synchronous Slave allows the system to ensure data consistency in case of Master node failures since the synchronous Slave is an exact copy of the Master. The synchronous Master-Slave replication is also called a hot standby topology because the synchronous Slave is readily available for replacing the Master node.
When only asynchronous Slave are available, the new elected Slave node might lag behind the failed Master, in which case consistency and durability are traded for lower latencies and higher throughput.
Aside from eliminating the single point of failure, database replication can also increase transaction throughput. In a Master-Slave topology, the Slave nodes can accept read-only transactions, therefore routing read traffic away from the Master node.
The Slave nodes increase the available read-only connections and reduce Master node resource contention, which, in turn, can also lower read-write transaction response time. If the Master node can no longer keep up with the ever-increasing read-write traffic, a Multi-Master replication might be a better alternative.
Multi-Master replication
In a Multi-Master replication scheme, all nodes are equal and can accept both read-only and read-write transactions. Splitting the load among multiple nodes can only increase transaction throughput and reduce response time as well.
However, because distributed systems are all about trade-offs, ensuring data consistency is challenging in a Multi-Master replication scheme because there is no longer a single source of truth. The same data can be modified concurrently on separate nodes, so there is a possibility of conflicting updates. The replication scheme can either avoid conflicts or it can detect them and apply an automatic conflict resolution algorithm.
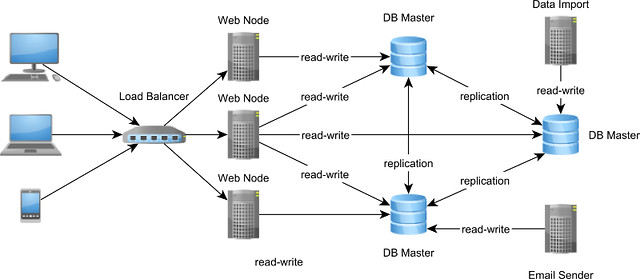
To avoid conflicts, the two-phase commit protocol can be used to enlist all participating nodes in one distributed transaction. This design allows all nodes to be in-sync at all time, at the cost of increasing transaction response time (by slowing down write operations).
If nodes are separated by a WAN (Wide Area Network), synchronization latencies may increase dramatically. If one node is no longer reachable, the synchronization will fail, and the transaction will roll back on all Masters.
Although avoiding conflicts is better from a data consistency perspective, synchronous replication might incur high transaction response times. Asynchronous replication can provide better throughput, at the price of having to resolve update conflicts. The asynchronous Multi-Master replication requires a conflict detection and an automatic conflict resolution algorithm. When a conflict is detected, the automatic resolution tries to merge the two conflicting branches, and, in case it fails, manual intervention is required.
Sharding
When data size grows beyond the overall capacity of a replicated multi-node environment, splitting data becomes unavoidable. Sharding means distributing data across multiple nodes so each instance contains only a subset of the overall data.
Traditionally, relational databases have offered horizontal partitioning to distribute data across multiple tables within the same database server. As opposed to horizontal partitioning, sharding requires a distributed system topology so that data is spread across multiple machines.
Each shard must be self-contained because a user transaction can only use data from within a single shard. Joining across shards is usually prohibited because the cost of distributed locking and the networking overhead would lead to long transaction response times.
By reducing data size per node, indexes also require less space, and they can better fit into main memory. With less data to query, the transaction response time can also get shorter too.
The typical sharding topology includes, at least, two separate data centers.
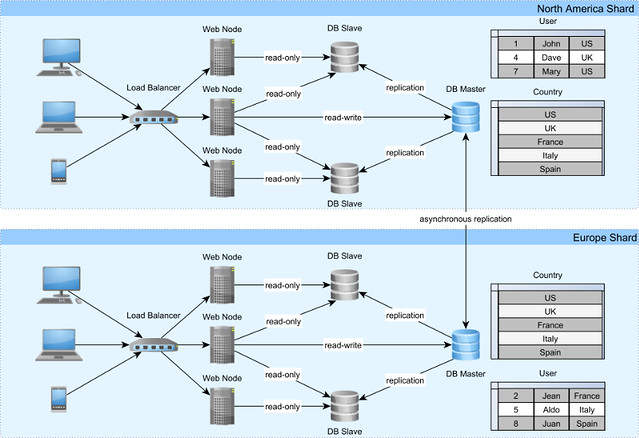
Each data center can serve a dedicated geographical region, so the load is balanced across geographical areas. Not all tables need to be partitioned across shards, smaller size ones being duplicated on each partition. To keep the shards in sync, an asynchronous replication mechanism can be employed.
In the previous diagram, the country table is mirrored from one data center to the other, and partitioning happens on the user table only. To eliminate the need for inter-shard data processing, each user along with all user-related data are contained in one data center only.
In the quest for increasing system capacity, sharding is usually a last resort strategy, employed after exhausting all other available options, such as:
- optimizing the data layer to deliver lower transaction response times
- scaling each replicated node to a cost-effective configuration
- adding more replicated nodes until synchronization latencies start dropping below an acceptable threshold.
This article is an excerpt from the High-Performance Java Persistence book, so, if you enjoyed reading it, I bet you are going to love the book as well.
 HighScalability Team
HighScalability Team
Reader Comments (4)
For the master slave replication, is it possible to provide strong consistency? The article mentions that you can write to only master, but you can read from slave. Since the replication strategy could be async, it would means that a client can write data to master and then read it immediately, where the system could attempt to read the data from a slave. In this case, if the async replication hasn't caught up, reader can get stale data.
Ankit,
In syncronous Master-Slave replication:
1) The client sends write request to master.
2) Master hasn't replicated the write to the slave yet, therefore hasn't replied to the user.
3) The client reads from the slave.
4) The master replicates the write to the slave and replies to the client that the write was successful.
The client reads "stale" data after he/she sends the write, but not before he/she receives the response. This behavior is expected though, even with only the master, since the client doesn't know which request got the database first.
@Ankit The Author mentioned that One syncronous slave can exist, so, you may use thsi synchronous slave for data consistancy, the other slaves can be asynchronous.
"Splitting the load among multiple nodes can only increase transaction throughput"
Multi-master replication does not increase throughput since the system is limited by the throughput of each master.
The advantages of multi-master replication are:
1) increased availability
2) Reduced latency since one of the masters can be located closer to the client.