













Friday
Sep292017
Stuff The Internet Says On Scalability For September 29th, 2017
Hey, it's HighScalability time:
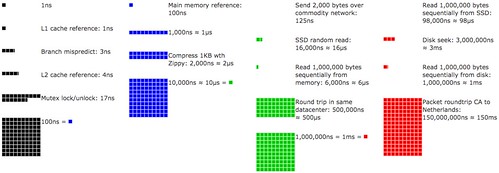
Latency Numbers Every Programmer Should Know plotted over time. Click on and move the slider to see changes. There were a lot more blocks in 1990.
If you like this sort of Stuff then please support me on Patreon.
- 1040: undergrads enrolled in Stanford's machine learning class; 39: minutes to travel from New York to Shanghai on Elon's rocket ride; $625,000: in stolen electronic-grade polysilicon; 160: terabits of data per second for Microsoft's new Trans-Atlantic Subsea Cable; 8K: people in Microsoft's AI group; 110%: increase in ICS/SCADA attacks from 2016 to 2017; 2 million: advertisers on Instagram; ~70%: savings using new Spot instance checkpointing; 10,000: nuts a year stored by a fox squirrel; $22.1 billion: IaaS market in 2016;
- Quotable Quotes:
- @patio11: Wife: "Hold hands when crossing the street." *2 year old grabs own hands* "OK Mommy." Me: "Oh you're going to be so good at programming."
- Charlie Demerjian: Intel’s “new” 8th Gen CPUs are a stopgap OEM placation to cover for a failed process, but they do bring some advances. As SemiAccurate sees it, Intel took .023 steps forward with the hardware and their messaging took three steps back.
- Richard Dawkins: If AI Ran the World, Maybe it Would Be a Better Place
- @swardley: No-one should be in any doubt that AWS is gunning for entire software stack (all of it) over next decade. Lambda, one code to rule them all.
- @mstine: "you are as reliable as the weakest component in your stack...and people are a really weak component." @adrianco #CloudNativeLondon
- @swardley: The vertical depth play will be found wanting as Amazon uses ecosystems to chew up horizonal components and move up the value chain.
- @swardley: I assume Goldmans is bricking itself that Amazon might come into its industry and with good reason. The fattened slug wouldn't last long.
- reacweb: I have a baremetal server and 99% of my admin task is apt-get update, apt-get upgrade. I have a diary where I write all the other admin tasks (the most complex one was configuring apache). When I buy a new server, I reread my notes to do some copy/paste. The freedom of a bare server is priceless ;-)
- tedu: if you’re going to retry automatically, be damn sure the operation either failed or is idempotent. Or next week you can be the lucky author of the blog post about what happens when your billing database reverts to readonly mode, preventing any transactions from being marked paid, sending the payment service into a loop where it charges customers their monthly bill every 10 minutes for ten hours.
- Jeff Barr: You can now resume workloads on spot instances and fleets. As long as they checkpoint to disk, workloads that aren’t time sensitive just got a whole heck of a lot cheaper for you.
- Jamie Condiffe: The experiment uses drones to shuttle parcels of up to 4 pounds from a distribution center to vans—at least, when they’re parked at one of four rendezvous points around the city, anyway. The vans have a special landing zone on their roof, which allows the drone to set down and and drop off its payload. The driver of the vehicle is then tasked with actually delivering the package to a customer.
- @codinghorror: Absolutely monstrous http://browserbench.org/Speedometer/ numbers for iPhone 8. That is over 1.4x the iPhone 7
- @EdSwArchitect: "Logstash is not going to go to 500,000 log entries / second". Kafka does. #StrataData - Streams & Containers talk
- endymi0n: Managing financial matters on AWS is such a royal PITA, I'm so glad we switched 90% of our stack to Google.
- shub: Good luck finding anything public about graph processing on a dataset too large to fit on a single machine. I can launch an AWS instance with 128 cores and 4 TB RAM--how many triples is too many for that monster? Tens of billions? Hundreds of billions?
- @pzfreo: @adrianco #CloudNativeLondon By the time you've decided on your container orch'n system, you could have the whole thing done in #Serverless
- @danielbryantuk: "The easy win to get started with chaos engineering is to run a game day with what you currently have" @adrianco #CloudNativeLondon
- @Tulio_de_Souza: CloudNative principle: "pay for what you used last month and not what what you guess you will need next year" #cloudnativelondon @adrianco
- Yasmin Anwar: fox squirrels apparently organize their stashes of nuts by variety, quality and possibly even preference
- @kopertop: Unfortunately @randybias, the most important thing @awscloud did cant be replicated by *any* Software. Marketing, innovation, and support.
- Sarty: I guess the argument [for using Filecoin] is that I should trust a single behemoth like Amazon less than I should trust an arbitrary number of nameless, faceless on-the-cheap suppliers on the premise that a nebulous algorithm that I (the average user) don't totally understand will stochastically cause those suppliers to lose their contract if they lose too much data, but that's okay because a different nebulous algorithm I don't totally understand can reconstruct the data as long as most of those nameless, faceless suppliers are on the up-and-up, all on the fly and completely decentralized? Yeah, sure, sign me up. What could possibly go wrong?
- danudey: The biggest change for us was SSDs coming down in price. Whereas before I might need four read slaves to ensure that at peak load I'm handling all my transactions within X ms, now I can guarantee it on one server. More importantly, in our industry where we're vastly more write-constrained than read-constrained and we're faced with e.g. MySQL not being able to easily spread writes over multiple servers simply, the appeal of something like MongoDB or Cassandra with built-in sharding and rebalancing to spread out both reads and writes sounds very appealing. And again, I can move from a giant complicated, expensive, heat-producing multi-disk raid10 to a pair of SSDs in RAID1 (or better) and easily meet my iops requirements. Without being able to upgrade to SSDs I think we would have been looking into other systems like Cassandra a lot sooner, but right now we can pretty easily throw some money at the problem and it goes away.
- LibertarianLlama: Perhaps millennia from now we will be building Dyson Spheres around stars to use the energy to mine bitcoin.
- happymellon: I work with satellite imagery processing which is quite large in it raw data format, and after a decade we are not dealing with petabytes of active data, hundreds of gigs for a full earth coverage. Before that I have held positions in finance, dealing with realtime transaction processing. We did not work in petabytes. If you are working in petabytes you are storing crap in your production database, and 99% of that data is wasted.
- @karpathy: Kaggle competitions need some kind of complexity/compute penalty. I imagine I must be at least the millionth person who has said this.
- unclebucknasty: I think I'm one of those graybeards. I see it in so many things tech. It's a pattern, and once you've seen it repeat a half-dozen times and also gain a depth of experience over that time, you can actually recognize when something represents genuine progress vs yet another passing fad. Spoiler alert: those that are most rabidly promoted are often the latter. But, if you try to raise the point in the midst of the latest fad, you generally get shouted down. So, you wait until the less-jaded figure it out...again. It was plainly obvious for NoSQl, just as it now is for SPAs (or at least our current approach). Don't believe me? Wait 5 years.
- CBobRobison: Outsourcing Attacks are prevented by implementing Proof-of-Spacetime (PoST). With PoST a node is required to put a deposit down based on the amount of storage it's providing. It then has to continuously hash the stored data against public nonces and occasionally upload it's solution to the network to prove the data was there the whole time. If it doesn't actually have the data, it doesn't hash correctly, and it fails to provide PoST. As a negative consequences, the node forfeits its deposit.
- Antonio Garcia-Martinez: Zuckerberg’s proposes, shockingly, a solution that involves total transparency. Per his video, Facebook pages will now show each and every post, including dark ones (!), that they’ve published in whatever form, either organic or paid. It’s not entirely clear if Zuckerberg intends this for any type of ad or just those from political campaigns, but it’s mindboggling either way. Given how Facebook currently works, it would mean that a visitor to a candidate’s page—the Trump campaign, for instance, once ran 175,000 variations on its ads in a single day—would see an almost endless series of similar content.
- We have another entrant into the edge computing game, one with over 117 locations. Introducing Cloudflare Workers: Run Javascript Service Workers at the Edge. Javascript and V8 JavaScript engine were chosen because it's secure. The Service Worker API was chosen because it fits with how they see it being used, as an endpoint, as an event handler which receives requests and responds to those requests, as something that can modify the original request and made its own requests. Here's how it works: "Your Service Worker will intercept all HTTP requests destined for your domain, and can return any valid HTTP response. Your worker can make outgoing HTTP requests to any server on the public internet." This seems inline with what AWS is doing on the edge. We still don't have a complex stateful model of how applications work at the edge. What does it mean for an application to work in hundreds of locations simultaneously? How is state handled? How are mobile clients passed around?
- The future of Apple's new LTE watch is the cloud. If you've ever programmed for the watch you know what a huge pain in the arse it was and still is. The watch tethered to the iPhone sucks as much as the original iPhone being tethered to a desktop. In both cases the cloud shall set them free. Hopefully it won't be long before you can download real standalone apps onto the watch and the iPhone can be nothing but a horrible memory. The problem for Apple is they don't have a compute function in their cloud. They really need some sort of serverless offering for future watch apps.
- Nice history of the rise, supposed fall, and resurrection of something recognizably SQLish. Why SQL is beating NoSQL, and what this means for the future of data. But I refuse to believe the power of SQL comes from midichlorians. Also, 10 Cool SQL Optimisations That do not Depend on the Cost Model.
- Damn, this is straight out of Person of Interest (the TV show). Chinese surveillance system.
- Carl Cook with a cool look at a high performance trading system written in C++, with helpful code examples. When a Microsecond Is an Eternity. Safety first. If anything appears to be wrong, pull all orders and start asking questions, a lot of bad can happen in a few seconds in an uncontrolled system. The hotpath is only exercised .01% of the time. C++ is chosen because it let's you have zero-cost abstractions. A very good minimum time (wire to wire) for a software-based trading system is 2.5 microseconds, less time than it takes light to travel from the top of Burj Khalifa to the ground. Low latency programming techniques. Remove slow path paths. Cascading if-thens are bad. Use templates to remove virtual functions and simple branches. If at compile time you know which function should be executed then prefer lambdas. Allocate using preallocated objects. Don't be afraid to use exceptions, they have zero cost if they don't throw. Prefer templates to branches. Avoid multi-threading in latency-sensitive code. Denormalized data is not a sin, pull all the data you need from the same cacheline. Keep the cache hot by frequently running a dummy path. Don't share L3, disable all but 1 core. Move noisy neighbors to a different physical CPU. Profiling is not necessarily benchmarking. Improvements in profiling results are not a guarantee your system is now faster.
- Per-second billing isn't all marketing. Researchers ran a topic modeling analysis using 1.1 million vCPUs on EC2 Spot Instances. Professor Apon said about the experiment: They used resources from AWS and Omnibond and developed a new software infrastructure to perform research at a scale and time-to-completion not possible with only campus resources. Per-second billing was a key enabler of these experiments.
- This article actually makes how to compress integers into a gripping story. Stream VByte: breaking new speed records for integer compression: So what we did was to reorder the data. Instead of interleaving the data bytes and the control bytes, Stream VByte stores the control bytes continuously, and the data bytes in a separate location. This means that you can decode more than one control byte at a time if needed. This helps keep the processor fully occupied.
- How do you save dying fields of study while making education affordable? Signum University is an example of the power of online learning. They do it a little different, they stream classes over the Internet rather than try to duplicate a traditional experience. Germanic philology, for example, is dying almost everywhere, schools are closing down throughout the world. But with an online school like Signum, you can collect all the people interested in Germanic Philology, from around the world, together in one place online. On a world wide basis there's enough scale, especially at a lower price point, to support schools teaching a lot of niche field of studies. How do you reduce tuition costs? You ditch the campus and invest in people. Sounds a lot like software development. Exploring The Hobbit and More: An Interview with Corey Olsen.
- Fabulous series. On Disk IO, Part 3: LSM Trees: Today we’re going to explore one of the types of storage often used in the databases...Keeping the data structure immutable favours the sequential writes: data is written on disk in a single pass, append-only...Another advantage of the immutable files is that data can be read from the disk without any segment locking between operations...LSM Trees allow immutable, mergeable files and the nature of the primary index for the table is a matter of implementation (therefore, even B-Trees can be used as index data structure here)...many modern LSM implementations in the database field have something in common: Sorted String Tables...Usually the SSTable has two parts: index and data blocks. Data block consists from the key/value pairs concatenated one after another. The index block contains primary keys and offsets, pointing to the offset in the data block...In LSM Trees, all the writes are performed against the mutable in-memory data structure (once again, often implemented using a data structure allowing logarithmic time lookups, such as a B-Tree or a SkipList)...It’s obvious that LSM Trees cause some write amplification: the data has to be written to the write-ahead log, then flushed on disk, where it will potentially get read and written again during the merge process...Many databases use SSTables: RocksDB and Cassandra, just to name a few.
- Google responds. Extending per second billing in Google Cloud. Great thread on HackerNews, mostly people complaining about how AWS billing is full of suck.
- Just say no. That's key to network automation. SHOW 82: SELF-DRIVING NETWORKS WITH KIREETI KOMPELLA. Building snowflake, artisanal, networks, prevents automation. Standardization is required to scale anything. If you aren't in a greenfield situation, and you can't just say no, then create a restricted number of buckets and nudge people into one of those buckets. Over time, remove those buckets.
- Here's Everything You Need to Know About Java 9: The crown jewel: Project Jigsaw, this project aims to make Java modular, and break the JRE to interoperable components; Java and REPL (JShell); an update of Concurrency and Stack Walking API; HTTP 2.0; process API; debugging in production; support for Reactive Streams; G1 will be the default garbage collector, server-style garbage collector, designed for multi-processor machines with large memories; a new JDK Enhancement Proposal (aka JEP 11) that introduces playground incubator modules; a new release every six months, and update releases every quarter;
- Code != coin. Storing code in a blockchain goes against every good programming practice ever invented. Complicated code that runs forever that you can't update is a very, very bad idea. These are dumb contracts. A hacker stole $31M of Ether—how it happened and what it means for Ethereum: In blockchain, code is intrinsically unrevertible. Once you deploy a bad smart contract, anyone is free to attack it as long and hard as they can, and there’s no way to take it back if they get to it first. Unless you build intelligent security mechanisms into your contracts, if there’s a bug or successful attack, there’s no way to shut off your servers and fix the mistake. Being on Ethereum by definition means everyone owns your server.
- Some videos for CppCon 2017 are now available.
- Facebook on Migrating a database from InnoDB to MyRocks: We carefully planned and implemented the migration from InnoDB to MyRocks for our UDB tier, which manages data about Facebook’s social graph...With pure Flash, UDB was space-bound. Even though we used InnoDB compression and there was excess CPU and random I/O capacity, it was unlikely that we could enhance InnoDB to use less space...This was one of the motivations for creating MyRocks – a RocksDB storage engine for MySQL...
Clustered index, Transaction (Atomicity, Row locks, MVCC, Repeatable Read/Read Committed, 2PC across binlog and RocksDB), Crash-safe slave/master, SingleDelete (Efficient deletions for secondary indexes), Fast data loading, fast index creation, and fast drop table... experiments showed that space usage with MyRocks was cut in half compared with compressed InnoDB, without significantly increasing CPU and I/O utilization.
- Cliff Click has an excellent programmer's podcast—Programming and Performance—where he does a deep dive on various technical topics. You won't find another gloss of Apple product announcements here. Recent topics include: Debugging Data Races, Java vs C/C++, Of Bugs and Coding Styles, Programming and Performance Intro.
- AI is the new electricity. - Andrew Ng~ Where is value being created in AI today? Supervised learning. What's after it? Transfer learning. For example, take what you learn in object identification and transfer it to cancer detection. Unsupervised learning. Reinforcement learning. Requires huge amounts of data. Good for playing infinite video games. Anything where you can build a simulator and play an infinite amount of time. Not much value generated yet.
- Nice series of 6 articles. Building Blockchain in Go. Part 1: Basic Prototype.
- COST in the land of databases. A summary of three papers: Scalable Distributed Subgraph Enumeration, All-in-One: Graph Processing in RDBMSs Revisited, and Incremental Graph Computations: Doable and Undoable. dswalter: For anyone who is just passing by, the article attempts to verify some claims from recent VLDB and SIGMOD papers that claim decent* performance on graph algorithms in RDBMs. It's worth reading not only for the technical merits of the discussion, but also because the style of the article is ...feisty.
- Videos from @Scale 2017 are now available. Lots and lots of videos.
- Redundancy Does Not Result in Resiliency: Full redundancy doesn't prevent failures. When done correctly, it reduces the probability of a total failure. When done incorrectly, redundant solutions get less robust than non-redundant ones due to increased complexity...and you don’t know which one you’re facing until you stress-test your solution...It turns out that adding redundant components results in decreased availability under gray (or byzantine) failures...In reality, we keep heaping layers of leaky abstractions and ever-more-convoluted kludges on top of each other until the whole thing comes crashing down resulting in days of downtime.
- How do you scan large tables? The SQL I Love <3. Efficient pagination of a table with 100M records. Use paging, but instead of relying on the number of scanned records, use the user_id of the latest visited record as the offset. This approach was 1,000 times faster than the previous. EXPLAIN EXTENDED is used to see why. It uses a range join type, matches on primary key, a constant number of records are analysed, WHERE is used on the primary key.
- Serverless is cheaper, not simpler: there is no free lunch in a closed system: to gain a benefit something must be sacrificed. In technology, the most common currency to pay for benefits is “complexity”...When microservices replaced monoliths to gain the benefit of scale reliably under massive load, it was not a free lunch. Dealing with eventual consistency, handling asynchronicity, latency and fault tolerance, managing APIs and message schemas, load balancing, running rolling upgrades — we paid with a great deal of extra complexity for the gains...When Serverless replaces micro-services, it is not going to be free lunch either. We are paying by introducing more complexity, now for the benefit of massive cost savings.
- Here's a Machine Learning glossary to add to your collection.
- Open Sourcing Vespa, Yahoo’s Big Data Processing and Serving Engine: By releasing Vespa, we are making it easy for anyone to build applications that can compute responses to user requests, over large datasets, at real time and at internet scale...With over 1 billion users, we currently use Vespa across many different Oath brands – including Yahoo.com, Yahoo News, Yahoo Sports, Yahoo Finance, Yahoo Gemini, Flickr, and others – to process and serve billions of daily requests over billions of documents while responding to search queries, making recommendations, and providing personalized content and advertisements, to name just a few use cases. In fact, Vespa processes and serves content and ads almost 90,000 times every second with latencies in the tens of milliseconds. On Flickr alone, Vespa performs keyword and image searches on the scale of a few hundred queries per second on tens of billions of images.
- ronomon/direct-io: provides helpers and documentation for all the edge cases of doing cross-platform Direct IO with Node.js (O_DIRECT or F_NOCACHE, synchronous writes, buffer alignment, and volume locking to satisfy Windows' special restrictions on writing past the MBR on a block device).
- jaegertracing/jaeger: inspired by Dapper and OpenZipkin, is a distributed tracing system released as open source by Uber Technologies. It can be used for monitoring microservice-based architectures.
- openfaas/faas: a framework for building serverless functions with Docker which has first class support for metrics. Any process can be packaged as a function enabling you to consume a range of web events without repetitive boiler-plate coding.
- lemire/streamvbyte: a new integer compression technique that applies SIMD instructions (vectorization) to Google's Group Varint approach. The net result is faster than other byte-oriented compression techniques.
- danilop/serverless-chat: A serverless web chat built using AWS Lambda, AWS IoT (for WebSockets) and Amazon DynamoDB.
- pierricgimmig/orbitprofiler: next-gen standalone C/C++ profiler for Windows. Its main purpose is to help developers visualize the execution flow of a complex application. The key differentiator with many existing tools is that no alteration to the target process is necessary. Orbit does not require you to change a single line of code.
Hey, just letting you know I've written a new book: A Short Explanation of the Cloud that Will Make You Feel Smarter: Tech For Mature Adults. It's pretty much exactly what the title says it is. If you've ever tried to explain the cloud to someone, but had no idea what to say, send them this book.
I've also written a novella: The Strange Trial of Ciri: The First Sentient AI. It explores the idea of how a sentient AI might arise as ripped from the headlines deep learning techniques are applied to large social networks. Anyway, I like the story. If you do too please consider giving it a review on Amazon.
Thanks for your support!
 HighScalability Team
HighScalability Team
Reader Comments (2)
The hyperlink for "Building Blockchain in Go. Part 1: Basic Prototype" is invalid
Thanks. The correct URL is https://jeiwan.cc/posts/building-blockchain-in-go-part-1/