













Design Of A Modern Cache—Part Deux

This is a guest post by Benjamin Manes, who did engineery things for Google and is now doing engineery things as CTO of Vector.
The previous article described the caching algorithms used by Caffeine, in particular the eviction and concurrency models. Since then we’ve made improvements to the eviction algorithm and explored a new approach towards expiration.
Eviction Policy
Window TinyLFU (W-TinyLFU) splits the policy into three parts: an admission window, a frequency filter, and the main region. By using a compact popularity sketch, the historic frequencies are cheap to retain and lookup. This allows for quickly discarding new arrivals that are unlikely to be used again, guarding the main region from cache pollution. The admission window provides a small region for recency bursts to avoid consecutive misses when an item is building up its popularity.
This structure works surprisingly well for many important workloads like database, search, and analytics. These cases are frequency-biased where a small admission window is desirable to filter aggressively. However, a small window is detrimental in recency-biased workloads, like job queues and event streams. In some systems the access pattern changes over time so that no static configuration is optimal, such as a cache serving user activity during the day and batch jobs at night.
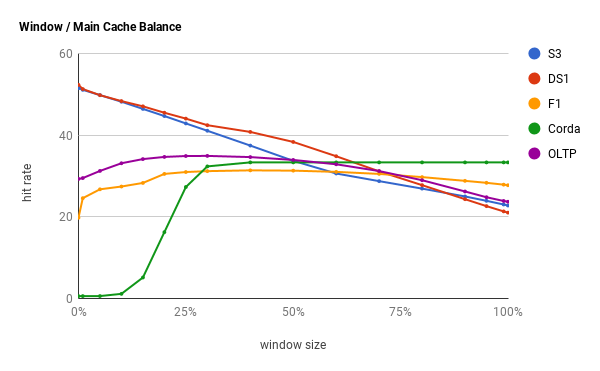
The hit rate curves show both the challenge of a heuristical setting and hint towards a solution. By using an optimization technique known as hill climbing, an adaptive cache can walk the curve to its peak. This is done by sampling the hit rate and choosing a direction to step towards. When the previous direction led to an increased hit rate then it continues to climb, otherwise it turns around. Eventually, the cache will oscillate around the best configuration, so gradually decaying the step size leads to converging to the optimal value. This process restarts whenever the hit rate shifts by a large percentage, indicating that the underlying workload changed.
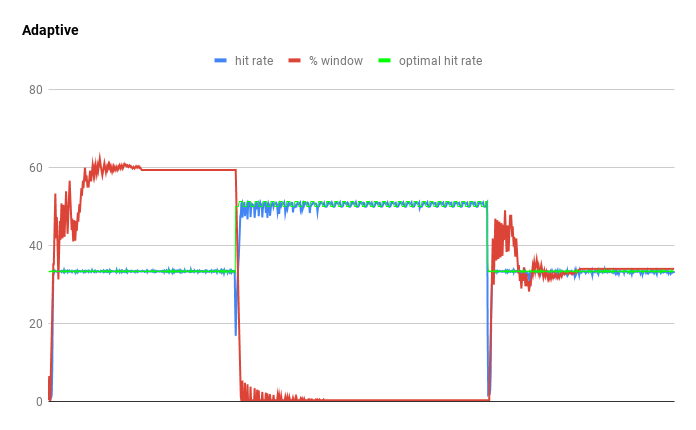
We can see this in action by chaining recency and frequency skewed traces (blockchain mining and an analytical loop). The cache starts in a frequency configuration with a window size of 1%. The recency trace causes the window size to ramp up and match LRU’s hit rate. When the frequency trace takes over, the hit rate crashes and the cache reacts by shrinking the admission window to zero. Eventually the recency trace begins, once again triggering an adaption. This results in an overall hit rate of 39.6%, just shy of the optimal 40.3%. All other policies tested were 20% or lower, including ARC, LIRS, and static W-TinyLFU.
Expiration Policy
Previously, expiration was only briefly mentioned due to more advanced support being in development. The typical approach is to either use an O(lg n) priority queue to maintain sorted order or to pollute the cache with dead entries and rely on the maximum size policy to eventually evict them. Caffeine uses only amortized O(1) algorithms, starting with a simpler fixed policy and adding a variable policy afterwards.
A fixed expiration policy is when every entry is treated identically, such as a ten-minute time-to-live setting. In this case, we can use a time-bounded LRU list, where the head is the oldest item and the tail is the youngest. When the item’s expiration time is reset then the entry is moved to the tail, which can be performed efficiently by embedding the list pointers onto it. When evicting we rely on the fact that everything after the head is younger, so items are polled as needed. This supports access and write order policies, but only if the duration is fixed.
A variable expiration policy is more challenging because every entry is evaluated differently. This usually occurs when the expiration policy is external to the cache, such as from http expiration headers for a third-party resource. This requires sorting, but thanks to the ingenuity of hierarchical timing wheels it can be done using hashing instead of by comparison.
A timing wheel is an array of doubly-linked lists, each representing a coarse time span. This way items are hashed to the corresponding bucket, putting it in a roughly sorted order. By using multiple wheels, a hierarchy can represent larger time frames such as days, hours, minutes, and seconds. When an upper-level wheel turns, the next bucket is flushed to the lower wheels and those items are rehashed and placed accordingly. When the lowest level wheel turns, the items in the previous bucket are evicted. Thanks to hashing and cascading, this policy is implemented in amortized O(1) time and offers great performance.
Conclusion
Caffeine is an open-source Java caching library. The techniques discussed here and previously can be applied to any language and are surprisingly straightforward to implement. In addition to those thanked in our last article, I’d like to highlight the thoughtful contributions by the following people,
Ohad Eytan, Julian Vassev, Viktor Szathmáry, Charles Allen, William Burns, Christian Sailer, Rick Parker, Branimir Lambov, Benedict Smith, Martin Grajcar, Kurt Kluever, Johno Crawford, Ken Dombeck, and James Baker
 HighScalability Team
HighScalability Team
Reader Comments