













Friday
Sep202019
Stuff The Internet Says On Scalability For September 20th, 2019
Wake up! It's HighScalability time:
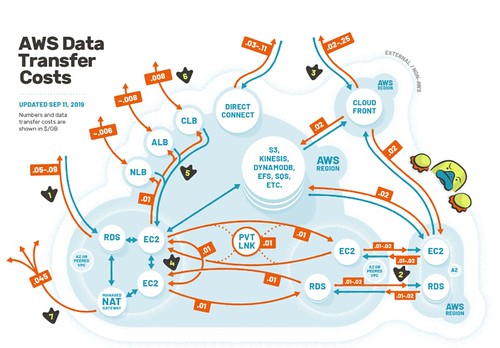
What could be simpler? (duckbillgroup)
Do you like this sort of Stuff? I'd love your support on Patreon. I wrote Explain the Cloud Like I'm 10 for people who need to understand the cloud. And who doesn't these days? On Amazon it has 54 mostly 5 star reviews (125 on Goodreads). They'll learn a lot and likely add you to their will.
Number Stuff:
- 30 mbits/second: telemetry sent by all F1 cars at all times during a race.
- ~9 inches: Cerebras Systems' new chip that completely rethinks the form factor for datacenter computing.
- 85%: browsers support WebAssembly.
- $75bn: market value created by enterprise-focused companies this year.
- 20TB: Western Digital hard drive designed primarily for write once read many (WORM) applications.
- 80%: music industry revenue ($4.3 billion) provided by streaming.
- $10 million: Facebook funding to create a deep fake detection
- 1.2 trillion: transistors on a single die (46,225 mm2), for machine learning accelerator chip, the first time in human history.
- 58%: increase in spending on China's cloud infrastructure o $2.295bn.
- 46 days: generative adversarial networks and reinforcement learning examined research and patents to create a potential drug.
- $15,000: cost of a drone used to knock out half of Saudi Arabia’s oil supply.
- 30%: certs for web domains are made by Let's Encrypt.
- 70%: users wrongly identify what a safe URL should look like.
- 3-4x: faster, on what is effectively a memory bound problem, by interleaving 32 binary searches together.
- $18,000: cost of 1.5TB of RAM.
- 130 meters: material was deposited in a day from the asteroid that killed the dinos.
- 80,000: seeds hidden by Mountain Chickadees to survive winter.
- 2nd: place Netflix now holds in the great who uses the most internet bandwidth race. HTTP media streaming is number one.
- 3,100: entities to who the Wisconson DMV sold personal data.
- 1/3rd: podcast advertising business size compared to those ads you see before a movie.
- 400km/second: speed particles travel in space.
Quotable Stuff:
- Vint Cerf: Four decades ago, when Bob Kahn and I were creating the TCP/IP networking protocol for the internet, we did not know that we were laying the tracks for what would become the digital superhighway that powers everything in society from modern business to interpersonal relationships. By that same token, we also didn’t envision that people would intentionally take advantage of the network to commit theft and fraud.
- apenwarr: Absolute scale corrupts absolutely. The pattern is: the cheaper interactions become, the more intensely a system is corrupted. The faster interactions become, the faster the corruption spreads.
- @cdespinos: For comparison, *two* iPhone 11 Pro phone processors contain more transistors than we shipped in all the 6502s in all the Apple IIs we ever made.
- @aallan: "People no longer think about their destination being 10km away or 10 stops on the tube. They think about it being 50% of their battery away…" people have always navigated by pubs in Britain, or gas stations in the States. They divide space into concepts.
- digitalcommerce: With 58% of its $232.9 billion revenue coming from its marketplace, Amazon is the largest online U.S. marketplace. Last year alone, over 25,000 sellers worldwide sold more than $1 million on Amazon, with the average U.S. marketplace merchant selling more than $90,000 on the site.
- Brenon Daly: Paper may be pricy these days, but it still has value as an M&A currency. So far this year, US public companies have been using their own shares at a near-record rate to pay for the tech deals they are doing.
- @QuinnyPig: I'm staring at a client bill of ~$120K a month of cross-AZ transfer. Not sold. Not sold at all.
- mscs: Many people I’ve met who are now saying “I want to put my app in AWS” were saying “I want to put my app in Hadoop” a few years ago with an equal understanding of what it means: zero. The excitement over the shininess of the technology is completely overwhelming the practicality of using it. A key part of my job is to show people how the sausage is made, and give them the slightly more polite version of this talk.
- Zach_the_Lizard: Not Google, but another Big Tech company. Visibility is very important to getting a promotion at a large company. Selling your work is important. To move up, you must be playing the "choose a good project or team" game for at least 6 months before you try to get promoted. Preferably for a year or more to hit the right checkboxes for multiple cycles. If you fail to do so, you can do absolutely amazing work but rigid processes and evaluation criteria will conspire to defeat you in a promotion committee setting
- Corey: ConvertKit may want to take a look at what regions they’re in. If they can get by with us-east-1 and us-east-2 as their two regions, cross-region data transfer is half-price between them, as even data wants to get the hell out of Ohio. Capitalize on that.
- cmcaine: Loop unrolling doesn’t always give you this benefit. This technique is about rewriting an algorithm to be branchless and to separate memory accesses that are dependent on each other with independent work (here by interleaving iterations). Doing both allows the processor to request lots of memory locations in parallel. Unrolling reduces the number of branches but doesn’t necessarily interleave independent memory accesses.
- @davidgerard: "The difference between BTC and ETH is that BTC has a vaporware second layer scaling solution, while ETH has a vaporware first layer scaling solution." - SirBender
- Rasmus Lerdorf: I had absolutely no idea… At every point along the way, I figured there were about six months of life left in PHP. Because that’s about the amount of time I thought it would take for somebody to write something real that could replace it, that also would work for me. And I kept waiting… And nothing did.
- @sarahmei: 1,000,000% this. If a senior engineer can’t explain it to you in a way you understand - even if you are a lot less experienced - that’s THEIR deficiency. Not yours. When this happens, it means THEY actually don’t understand it well enough.
- @mjpt777: You are never sure a design is good until it has been tested by many. Be prepared and eager to learn then adapt. You can never know everything in advance.
- @davidgerard: The key dumbassery in Facebook's Libra is:* they spent two years working out their blockchain plan and philosophy; * they spent 0 of this time talking to the financial regulators who could yea or nay their financial product.
- @channingwalton: “Your team is one of the best performing in the organisation, I will come and see what you’re doing.” “I’ve observed and I’m not happy. You aren’t using the official scrum story format or using Jira. You must do those things properly.”
- @adrianco: The Netflix zone aware microservices architecture did’t cross zones - 8 years ago. Not sure why people think its a good idea. After LB picks a zone stay there.
- @taotetek: I've complained about config.sys, dot files, ini files, sendmail macros, xml, json, yml, etc throughout my career - name a config format and I've complained about it - and what the complaints really were was "configuring this thing is tedious and hard".
- @iamdevloper: employee: I want growth in my role company: *installs ping pong table* employee: autonomy? company: *creates fully-stocked snack room* employee: fulfilment. company: *employs a live DJ in the office* employee: *quits* company: some people just aren't a good culture fit.
- Taylor Clauson: Recently, when I opened the AWS Console, I had a moment of deja vu that called back to a 2010 post by Andrew Parker, then of Spark Capital, that focused on the startup opportunities of unbundling Craigslist. And it shifted a long-simmering feeling into focus for me: I am really excited about startups that are unbundling AWS. There are obvious differences between Craigslist and AWS. The most important is that Craigslist (and each of the category spawn) is a marketplace, and so has the powerful advantage of network effects. Another distinction is that AWS has relative cost advantages over its unbundlers when it comes to the fundamental components of infrastructure (compute, bandwidth, storage, etc.), and I can’t see a parallel to Craigslist. So it’s not a perfect analogy, but the premise of unbundling certain categories still holds.
- Mikhail Aleksandrovich Bakunin: In antiquity, slaves were, in all honesty, called slaves. In the middle ages, they took the name of serfs. Nowadays they are called users.
- dannypgh: I spent 9 years at Google, just left at the end of July. The biggest thing I grew to appreciate was that for iterating large scale production systems, rollout plans are as important as anything else. A very large change may be cost or risk prohibitive to release at once, but with thought you can subdivide the release into easier to rollout and verify subcomponents, you can usually perform the same work as a series of lower risk well understood rollouts. That's critical enough where it's worth planning for this from the design phases: much as how you may write software differently to allow for good unit tests, you may want to develop systems differently to allow for good release strategies.
- jorawebdev: Other than having “Google” on my resume there is nothing special or applicable outside of Google. Most tools are internal, isolated and the choices are restrictive. Management is shitty - micro-management is in full bloom, display lack of management knowledge, skills and there’s plenty of abuse of power. They don’t show their appreciation to what we do. All developers are very competitive. My entire time of over a year in 2 different teams is spent in isolation and self learning without much help or directions. I’m currently actively interviewing outside.
- mharroun: We spend ~900$ a month on fargate to run our of our dev, stage, qa, and prod environments as well as some other services and sqs consumers. After the recent price decrease we looked at how much reserve instance would save us and the few hundred in savings would not make sense vs the over provisioning and need to dedicate resources to scaling and new tools to monitor individual containers.
- Laura Nolan: There could be large-scale accidents because these things will start to behave in unexpected ways. Which is why any advanced weapons systems should be subject to meaningful human control, otherwise they have to be banned because they are far too unpredictable and dangerous.
- bt848: The most important thing I learned there was that you hire and promote people not so management can tell them what to do, but so they can tell management what to do. I didn’t even realize it at the time but the first post-Google job I had there was some clueless manager trying to set the roadmap and I was like “LOL what is this guy’s problem?” That when I started noticing the reasons that Google succeeds.
- redact207: It's sad to see this approach being pushed so hard these days. I believe AWS recommends these things so your app becomes so deeply entrenched in all of their services that you've locked yourself into them forever. Unfortunately I see a lot of mid and senior devs try to propose these architectures during interviews and when asked questions on integration testing, local environment testing, enforcing contracts, breaking changes, logical refactoring a lot of it falls apart. There's a lot of pressure for those guys to deliver these sort of highly complex systems and all the DevOps that surround it when they enter a new company or project. Rarely is the project scope or team size considered and huge amounts of time are wasted implementing the bones since they skip the whole monolith stage. Precious few companies are at the size where they can keep an entire Dev team working on a shopping cart component in perpetuity. For most it's just something that gets worked on for a sprint or two. AWS made a fundamental assumption in this that monoliths and big balls of mud are the same thing. Monoliths can and should be architected with internal logical separation of concerns and loose coupling. Domain driven design helps achieve that. The other assumption that microservices is a fix to this isn't, because the same poor design can be written but now with a network in between everything.
- usticezyx: Here a summary of my understanding: * Relentlessly hire the best, train them and give space for them to grow and shine. This is the basis. It's not that a less quality engineer cannot grow, it's just too costly to do that at large scale. * Build the infrastructure to support large scale engineering. The best example is the idea of "warehouse scale computer" that is the data center, embodied in systems like Borg Spanner etc. * Relentless consistency at global scale. Example would be the Google C++ style guide. It's opinionated at its time, but is crucial to ensure a large C++ code base to grow to big size. * Engineering oriented front line management. L6-L8 managers are mostly engineering focused. That's necessary. * Give the super star the super star treatment. Google's engineers are rewarded as strategic asset of the company. Numerous example are made public.
- BAHAR GHOLIPOUR: This would not imply, as Libet had thought, that people’s brains “decide” to move their fingers before they know it. Hardly. Rather, it would mean that the noisy activity in people’s brains sometimes happens to tip the scale if there’s nothing else to base a choice on, saving us from endless indecision when faced with an arbitrary task. The Bereitschaftspotential would be the rising part of the brain fluctuations that tend to coincide with the decisions. This is a highly specific situation, not a general case for all, or even many, choices.
- Hope Reese: Cavanagh argues that, like bees, humans swarm in sync and change course en masse. She points to the legalization of marijuana, or support for gay marriage, as examples of those tipping points. Public support was “slowly building, but then seemed to, all of a sudden, flip,” she tells OneZero.
- Mike Isaac: I will say, and I try to get at this point in the book, that a lot of forces came together at the same time to make it possible for something like Uber to exist. And so one could argue that someone else would have done it if not Travis, and to be sure, there were a bunch of competitors at the time. But he did it the biggest out of the many that tried. So you have to give him credit for that.
- Spotify: At Spotify, one of our engineering strategies is the creation and promotion of the use of “Golden Paths.” Golden Paths are a blessed way to build products at Spotify. They consist of a set of APIs, application frameworks, best practices, and runtime environments that allow Spotify engineers to develop and deploy code safely, securely, and at scale. We complement these with opt-in programs that help increase quality. From our bug bounty program reports, we’ve found that the more that development adheres to a Golden Path, the less likely there is to be a vulnerability reported to us.
- Steve Cheney: Much breath is wasted over 5G, which is largely a mirage… The real innovation in wireless is happening at the localization and perception levels of the stack. Ultra Wideband gives a 100x increase in fidelity for localization. By using standard handshaking at the physical layer of the 802.15.4z standard, novel properties have emerged for not only localization of devices, but also permission, access control and commerce. In fact, UWB will replace Bluetooth (10x the throughput) and subsume NFC—both transferring of high bandwidth data (phone to glasses) and short range payments will standardize around UWB.
- DSHR: The conclusion is that Google's monopoly is bad for society, but none of the proposed anti-trust remedies address the main reason that it is bad, which is that it is funded by advertising. Even if by anti-trust magic we ended up with three search engines each with 30% of the market, if all three were funded by advertising we'd still be looking at the same advertiser-friendly results. What we need is an anti-trust ruling that says, for example, no search engine with more than 10% market share of US Web search may run any kind of "for pay" content in its result pages, because to do so is a conflict of interest.
- @rbranson: The thing that nobody talks about with the whole sidecar pattern is how much CPU it burns. If you're moving a lot of data in/out through the proxies it can be non-trivial. Adding 10-15% to your compute budget is a serious ask.
- Julian Barbour: People have the idea that the universe started in a special, ordered state, and it's been getting disordered ever since then. We're suggesting it's completely the other way around. The universe, in our view, starts in the most disordered way possible and, at least up to now, it's been getting ever more interesting.
- Tony Albrecht: The dashboards are built with Tableau. The data is fed in from various other sources. We [Riot Games] do track lots of other performance metrics; memory, peak memory, load times, frame spikes, HDD/CPU/GPU specs, and many others. This article is the result of distilling out the data which has no (or very little) impact on performance. We're regularly adding to that and refining what we have. The filtering by passmark already removes the diurnal effect.
- tetha: And that's IMO where the orchestration solutions and containers come in. Ops should provide build chains, the orchestration system and the internal consulting to (responsibly) hand off 80% of that work to developers who know their applications. Orchestration systems like K8, Nomad or Mesos make this much, much easier than classical configuration management solutions. They come with a host of other issues, especially if you have to self-host like we do, no question. Persistence is a bitch, and security the devil. Sure. But I have an entire engineering year already available to setup the right 20% for my 20 applications, and that will easily scale to another 40 - 100 applications as well with some management and care. That's why we as the ops-team are actually pushing container orchestrations and possibly self-hosted FaaS at my current place.
- shantly: - If it doesn't have very different scaling needs from the rest of the application, probably don't make it a microservice. - If it isn't something you could plausibly imagine using as a 3rd party service (emailer/sms/push messages, authentication/authorization, payments, image processing, et c.) probably don't make it a microservice. - If you don't have at least two applications at least in development that need the same service/functionality, probably don't make a microservice. - If the rest of your app will completely fall over if this service fails, probably don't make it a microservice. - Do write anything that resembles the above, but that you don't actually need to make a microservice yet, as a library with totally decoupled deps from the rest of your program.
- Gojko Adzic: there is an emerging pattern with Lambda functions to move from a traditional three-tier deployment architecture to a more thick-client approach, even with browsers. In usual three-tier applications, the middle layer deals the business logic, but also with security, workflow orchestration and sessions. Lambda functions are not really suited to session management and long-running orchestration. Business logic stays in Lambda functions, but the other concerns need to go somewhere else. With the AWS platform providing security, a relatively good choice for session management and workflows is to push them to the client completely. So client code is getting thicker and smarter. It’s too early to talk about best practices, because the platform is still rapidly evolving, but I definitely think that this is an interesting trend that needs closer examination. Moving workflow orchestration and sessions to client code from the middle-tier and servers means that application operators do not need to pay for idle work, and wait on background tasks. With a traditional three-tier application, for example, letting a client device write directly to a database, or access background file storage directly is a recipe for disaster and a security nightmare. But because the AWS platform decoupled security from processing, we find ourselves more and more letting client devices talk to traditional back-end resources directly, and set up Lambda functions to just act on events triggered by back-end resources.
Useful Stuff:
- #326: A chat with Adrian Cockcroft. What happens after chaos engineering becomes the norm?
- Chaos engineering won't be seen as extreme, it will become how you run resilient systems. It will be continuous, productized, and it will be expected for anyone running a highly reliable and highly available system.
- Large global companies like Netflix, Uber, Lyft running in a cloud native environment don't have any scheduled down time. It's expected they'll always be available. These architectures are active-active to keep everything up and running all the time. Airlines and finance companies were usually built around a traditional active-passive disaster recovery model approach. They are now looking to shut down all their datacenters, so they're looking at how to failover into the cloud when something fails.
- The US financial industry has regulations and audit requirements stemming from two sources: 9/11 where backup datacenters were on a different floor in the same building and the 2008 financial crisis. The result of these two events causes a whole series of regulations to be created. Some of the larger banks and financial institutions are regulated as strategically important financial institutions (SIFIs). They're regulated as a group because they are dependent and if they stop bad things would happen to the US and/or world economy. There's coordinated testing at least once a year where the companies get together and practice failovers between banks. It's not just one bank testing one application. It's like a game day at an industry level. As these industries are moving into the cloud AWS has to figure out how to support them.
- It's more about consistency than availability. When someone says something happened it really must have happened. When you say $150 million transferred between banks both banks must agree it happened. It's ok to say we didn't do it, try again, as long as they agree.
- In a large scale active-active system you don't want any down time, nobody can see it stopping. In that case a little inconsistency is OK. Showing the wrong movies on Netflix doesn't matter that much.
- In the financial industry, where consistency is key, you need a budget of time to determine if an operation is consistent. Typically that's 30 seconds. If something is completely broken that triggers disaster recovery failover to another site. It should take no more than 2 hours to get everything completely back up again. The entire set of applications must be shutdown and restarted properly. You can take 2 hours of down time to failover.
- Two ideas are recovery point objective and recovery time objective. Here's an example of an old style backup/restore type recovery. If you take tape backups every 24 hours and ship them offsite then your recover point is every 24 hours. If you have a disaster and you need to pull the tapes to the recovery site and get everything running that might take 3 days of recovery time.
- With online services there's typically a 30 second recovery point so you can recover to 30 seconds ago and it should take 2 hours to recover at another site.
- You must be able to recover from the loss of a site. The US has three power regions: eastern, western, and southern. These are three independent power grids. There have been cases where a power grid has done down across a whole region. At the two locations where you recover a work load there can be no employees in common. It shouldn't be possible to commute from one location to another. Preferably sites should be in different parts of the country. In the US you can run resilient loads between the east and west coast. AWS is trying to workout regions in the rest of the world.
- AWS Outpost can be used as internally allocated region for failing over. With Outpost it's more complex because you have to figure out the control and data planes.
- You have 30 seconds to make sure data in is both sites. Traditionally this is done at the storage tier by block level replication across regions. It's all very custom, flakey, expensive, and hard to test. They often don't work well. You have to have these sites for disaster recovery but they aren't giving you more availability because failing over is so fragile.
- The next level up is the database (DynamoDB and Aurora). AWS is hardening these services for financial applications. 30 seconds sounds like a long time, but it's actually hard to get everything done in that time. You also need to protect against long tail latency so operations complete with the 30 seconds. This is what they are really focussing on as the way to ship data to other locations.
- The next level up is the application level. Split traffic into two streams and send it to both sites to be processes in parallel. You have a complete copy that's fast to switch over too. But it's expensive and difficult to keep in sync.
- It's very hard to keep datacenters in sync. The cloud is easier because it's much more programmatic. It's still too hard, but in the cloud you can make sure both sites are in sync. AWS will productize these disaster recovery patterns as they can.
- Goal is to be able to test disaster recovery in real-time by setting up multiple regions and continually injecting the failure modes a system should be able to survive and showing it can run in 2 out of 3 zones, testing region failover so you know exactly what it looks like, how it happens, and how to train everybody so once you hit the emergency you know exactly what to do. The best analogy is fire escapes. In case of fire use the fire escape. Buildings have fire drills. It's a universal training process. We don't have the equivalent in the cloud and datacenter world to handle emergencies.
- Tracing, auditing, and logging feed into disaster recovery because you can have a tamper proof log of everything that happened. All the config. The exact sequence of API calls that created a site. You know the exact versions of everything. And when you failover you can recreate the site using that information and verify everything is exactly the same before failing over. You can prove a system has undergone regular tests by looking at the logs.
- Videos from always awesome Strange Loop conference are now available.
- Videos from Chaos Communication Camp 2019 are now available. You might like Fully Open, Fully Sovereign mobile devices which talks about "MEGAphone, which is not only a mobile phone, but also includes UHF packet radio and a modular expansion scheme, that can allow allow the incorporation of satellite and other communications."
- Data ghost stories are the scariest. And it's not even Halloween! Google Has My Dead Grandpa’s Data And He Never Used The Internet.
- If you're a Claude Shannon fan you'll probably like this information theory approach to aging. #70 - David Sinclair, Ph.D.: How cellular reprogramming could slow our aging clock. Humans have about 200 different cell types. As embryos all our cells are the same type. Each cell has a full copy of DNA which contains the genes which are used to produce proteins. Cells differentiate because certain genes are turned on and off. You can consider that pattern of gene expression as a program. Over time our cells lose the program of which genes should be turned on and off. Cells lose their identity. The idea is to reset the system to reinstall the cellular software that turns the right genes off and on. You can reprogram cells to regain their youth and identity. Technology used to generate stem cells is used to partially reprogram cells to turn on the youthful pattern of genes that we once had. As we get older our cells do not turn on the genes they did when we were younger. Genes that were on when we were young get switched off. Reprogramming resets that pattern. Genes that were once tightly bundled up by SIR proteins and methelated DNA come unwound as we get older. Reprogramming tells the cell that that region of the genome package that up again and get that gene to switch on or off again, depending on the cell type. The cell keeps its original configuration around. We haven't lost the genes due to mutation. The information is still there we just don't access it because the cells don't know to spool up the DNA and hide it or to expose it to turn on the right genes.
- Excellent deck on Taking Serverless to the Next Level.
- For communication to be effective it must have structure. Emails are often a waste of time because they lack intent. Here's how to fix that. BLUF: The Military Standard That Can Make Your Writing More Powerful. And that's also why Slack can suck. A thread doesn't replace the hard work of crafting a clear and precise message.
- Great question. Are we safer on-prem or in the cloud? Cloud Risk Surface Report: Cloud consolidation is a thing; the top 5 clouds alone host assets from 75% of organizations. Overall, organizations are over twice as likely to have high or critical exposures in high-value assets hosted in the cloud vs. on-prem. BUT clouds with the lowest exposure rates do twice as well as on-prem. Smokey the Bear was right—only you can prevent cloud fires. Even though we discovered an average 12X difference between clouds with highest and lowest exposure rates, this says more about users than providers. Security in the cloud isn’t on the cloud; it’s on you.
- Cuckoo Hashing: A new element is always inserted in the first hash table. Should a collision occurr, the existing element is kicked out and inserted in the second hash table. Should that in turn cause a collision, the second existing element will be kicked out and inserted in the first hash table, and so on. This continues until an empty bucket is found.
- So many ops these days. GitOps. DevOps. NoOps. AiOps. CloudOps. ITOps. SecOps. DevSecOps. It's all just sys admin to me.
- Want to learn about distributed systems? Murat has provided a really long reading list.
- Turns out caching energy has a lot in common with caching data. Ramez Naam on Renewable Energy and an Optimistic Future. Predicts we'll have a 50/50 split with batteries at a centralized location (solar farm/wind plant) and at the edge. One reason is at the edge (home, office building, mall) if there's a power outage the power at the edge keeps the power running. Another is your power lines are probably at capacity during peak usage time (4pm - 8pm), but empty at midnight, so batteries can be filled up at midnight and drain down during the day.
- Keynote speeches from Scratch Conference (Raspberry Pi) Europe 2019 are now available.
- A career in data science you may not have considered is Data Fabricator. Apparently companies in the generic drug industry pay people to fake data to fool regulators. It's hard to imagine they are the only ones. I bet it pays well.
- For the Azure curious Moving from Lambda ƛ to Azure Functions provides a clear look at what it's like build functions Azure. Different than Lambda for sure, but not so different. Using HTTP triggers instead of API gateway is a plus. Also, An Introduction to Azure Functions. Also also, My learnings from running the Azure Functions Updates Twitterbot for half a year.
- 15 things I’ve learned doing serverless for a year and a half: Use the Serverless Framework; You can build almost anything; You can cache and use connection pooling; You need to be careful using connection pooling; Lambdas can be very performant if optimized; Converge on one language (JavaScript); Consider services as a collection of lambdas (and other Aws services); Integration test your whole serverless architecture; it is ~1000x cheaper; Iterative deployments make for nice development; Event-driven architecture has some nice advantages; Some things don’t play nice with cloud formation (dns and kms); Use parameter store/secrets manager; Use private packages; Standardize your responses.
- It's painful to be an early adopter. You're constantly in technical debt as you must continually change to the new greatest way of doing things. Neosperience Cloud journey from monolith to serverless microservices with Amazon Web Services: Neosperience Cloud evolved through years from a monolithic architecture to a heterogeneous set of smaller modern applications. Today, our platform counts 17 different business domains, with a total of 5 to 10 microservice each of them, glued by a dozen of support services. Neosperience cloud is multi-tenant, deployed on several AWS accounts, to be able to reserve and partition AWS for each organization (a Neosperience customer). Every deployment includes more than 200 functions and uses more than 400 AWS resources through CloudFormation. Each business domain creates its resources at deploy-time, thus managing their lifecycle through releases. This evolution improved our fitness function under every aspect: from scalability and lifecycle to time to market that shifted from months down to weeks (even days for critical hotfixes). Infrastructure costs shrunk by orders of magnitude. Developers have full control and responsibility for delivery, and innovation is encouraged because failure impacts only a small portion of the codebase.
- A case study about compression and binary formats for a REST service. Surprise, JSON+LZMA2 is just a touch slower than Protobuf+LZMA2 (though Gzip worked better in production). So maybe you can just "keep it simple stupid."
- When you are managed by an algorithm as eventually will happen, what are likely to be your complaints? What People Hate About Being Managed by Algorithms, According to a Study of Uber Drivers. You won't like being constantly surveilled. Clearly for an algorithm to function it must have a 360 degree view of your every thought and action. That might be get old. You may chaffe at the lack of transparency. While the algorithm is always looking at you there's no way for you to look back at the algorithm. It makes decisions, you obey. It's rule by fiat. Something we purport to hate when a government does it, but accept with glee when a company created algorithm does it. You might feel isolated and alone has you more and more interact via a device instead of through other biomorphs. The future is so bright you might want to buy algorithm mediated shades.
- In the same way we spend all our time trying optimize garbage collected languages because we think managing memory is too difficult we spend all our time adding back type checking because we think using a typed language is just too hard. Our (Dropbox) journey to type checking 4 million lines of Python.
- Some ApacheCon 2019 videos are now available.
- Google's global scale engineering: Google treats global-scale engineering as one of its core business value, if not the single most critical one...Google is almost only interested in global scale products. Google has been willing to invest heavily on some of world’s most challenging technical problems...Google's global scape engineering capacity is reflected in several key areas:
- People management:global-scale engineering demands a global-scale engineering team. Google has more than 40k world-class software engineers, and an equal number of non-technical people
- Technology: Technology is the foundation, they provide tools for people to collaborate, optimize operations, create new business opportunities, and enable many other innovations. A global engineering organization cannot rely on third party providers.
- Operations: How to make the technical infrastructure be utilized fully? How to correctly address short-term and long-term engineering goals and risks? Google pioneered SRE.
- Business development: Combining these together, the capability needs to reflect in products that bring actual business value.
- Excellent architecture evolution story. Use Serverless AWS step functions to reduce VPC costs: We separated one huge Lambda invocation which operated at the maximum call length (15 mins) into parallel processing. Lambas are paid by the 100 ms so naturally a split of one to five separate Lambdas costs potentially almost an additional 400 ms per invocation. However, each workload can now be downsized to exactly the right resource utilisation in terms of memory and time. Every smaller run is also a tad more reliable in terms of duration (smaller variation) and your memory is quite consistent between runs, which makes for easier tuning. Our biggest payoff was that we could lose the NAT gateway. Which alone accommodates for 500 million Lambda requests of processing (100 ms, 512 mb).
- Why we chose Flink: To understand why we chose Flink and the features that turned Flink into an absolute breakthrough for us, let’s first discuss our legacy systems and operations. Firstly, before migrating to Flink, the team was heavily reliant on Amazon SQS as a queue processing mechanism. Amazon SQS does not support state so the team had to work off a fragile, in-house-built state that could not support our use case. With the use of Flink’s stateful computations we could easily retain in Flink state the past (arrival) ping, necessary to successfully run the clustering algorithm — something hard to accomplish with the previous technology. Secondly, Flink provides low latency and high throughput computation, something that is a must-have for our application. Prior to the migration, the team was operating on an abstraction layer on top of SQS, executed with Python. Due to Python’s global interpreter lock, concurrency and parallelism are very limited. We tried to increment the processing instances, but having so many instances meant it was very hard to find resources by our container management system PaaSTA that made our deployments take hours to complete. Flink’s low latency, high throughput architecture is a great fit for the time-sensitive and real-time elements of our product. Finally, Amazon SQS provides at-least-once guarantees that is incompatible with our use case since having duplicate pushes in the output stream could lead to duplicate push notifications to the user resulting in negative user experience. Flink’s exactly-once semantics guarantee that our use case leads to superior user experience as each notification will only be sent once to the user.
- UPMEM Processor-in-Memory at HotChips Conference: What is PIM (Processing in Memory) all about? It’s an approach to improving processing speed by taking advantage of the extraordinary amount of bandwidth available within any memory chip. The concept behind PIM is to build processors right into the DRAM chip and tie them directly to all of those internal bit lines to harness the phenomenal internal bandwidth that a memory chip has to offer. This is not a new idea. I first heard of this concept in the 1980s when an inventor approached my then-employer, IDT, with the hopes that we would put a processor into one of our 4Kbit SRAMs! Even in those days a PIM architecture would have dramatically accelerated graphics processing, which was this inventor’s goal.
- Mind blowing stuff. Detailed and scary. Unless we rewrite everything in Rust we'll always be at risk from very clever people working very hard to do very bad things. A very deep dive into iOS Exploit chains found in the wild: Working with TAG, we discovered exploits for a total of fourteen vulnerabilities across the five exploit chains: seven for the iPhone’s web browser, five for the kernel and two separate sandbox escapes.
- What a Prehistoric Monument Reveals about the Value of Maintenance. The White Horse of Uffington is a 3000-year-old figure of a football field sized horse etched into a hillside. Without regular maintenance the figure would have faded long ago. People regularly show up to rechalk and maintain the horse. To maintain software systems over time we've essentially corporatized ritual, but the motivation is the same.
- Great list. Choose wisely. 7 mistakes when using Apache Cassandra: When Cassandra works the best? In append-only scenarios, like time-series data or Event Sourcing architecture (e.g. based on Akka Persistence). Be careful, it’s not a general-purpose database.
- Paper review. Gray Failure: The Achilles' Heel of Cloud-Scale Systems. Not sure I agree with this one. Observation of distributed system state always suffers from an inherent relativity problem. There's no such thing as now or 100% working. They also suffer from an emergent complexity problem. There are always paths through the system that can never be anticipated in advance. Kind of like a Godel number. The biological model is you can have skin cancer and the rest of the body keeps right on working.
Soft Stuff:
- appwrite/appwrite (article): a simple to use backend for frontend and mobile apps. Appwrite provides client side (and server) developers with a set of REST APIs to speed up their app development times.
- botslayer: an application that helps track and detect potential manipulation of information spreading on Twitter. The tool is developed by the Observatory on Social Media at Indiana University --- the same lab that brought to you Botometer and Hoaxy.
- Adapton/adapton.rust: A general-purpose Incremental Computation (IC) library for Rust.
- wepay/waltz (article): quorum-based distributed write-ahead log for replicating transactions.
Pub Stuff:
-
Amazon Web Services’ Approach to Operational Resilience in the Financial Sector & Beyond: The purpose of this paper is to describe how AWS and our customers in the financial services industry achieve operational resilience using AWS services. The primary audience of this paper is organizations with an interest in how AWS and our financial services customers can operate services in the face of constant change, ranging from minor weather events to cyber issues.
-
Running Serverless: Introduction to AWS Lambda and the Serverless Application Model: This book will help you get started with AWS Lambda and the Serverless Application Model (SAM). Lambda is Amazon's engine for running event-driven functions, and SAM is an open-source toolkit that greatly simplifies configuring and deploying Lambda services.
-
Data Transfer Project Overview and Fundamentals: The Data Transfer Project (DTP) extends data portability beyond a user’s ability to download a copy of their data from their service provider (“provider”), to providing the user the ability to initiate a direct transfer of their data into and out of any participating provider. The Data Transfer Project is an open source initiative to encourageparticipation of as many providers as possible.
-
Procella: unifying serving and analytical data at YouTube: The big hairy audacious goal of Procella was to “implement a superset of capabilities required to address all of the four use cases… with high scale and performance, in a single product” (aka HTAP1). That’s hard for many reasons, including the differing trade-offs between throughput and latency that need to be made across the use cases.
 HighScalability Team
HighScalability Team{kind=link}
Reader Comments (1)
Hey Todd,
Please fix the broken link in this line:
"Want to learn about distributed systems? Murat has provided a really long reading list"