
A giant step into the fully distributed future has been taken by the Google App Engine team with the release of their High Replication Datastore. The HRD is targeted at mission critical applications that require data replicated to at least three datacenters, full ACID semantics for entity groups, and lower consistency guarantees across entity groups.
This is a major accomplishment. Few organizations can implement a true multi-datacenter datastore. Other than SimpleDB, how many other publicly accessible database services can operate out of multiple datacenters? Now that capability can be had by anyone. But there is a price, literally and otherwise. Because the HRD uses three times the resources as Google App Engine's Master/Slave datastatore, it will cost three times as much. And because it is a distributed database, with all that implies in the CAP sense, developers will have to be very careful in how they architect their applications because as costs increased, reliability increased, complexity has increased, and performance has decreased. This is why HRD is targeted ay mission critical applications, you gotta want it, otherwise the Master/Slave datastore makes a lot more sense.
The technical details behind the HRD are described in this paper, Megastore: Providing Scalable, Highly Available Storage for Interactive Services. This is a wonderfully written and accessible paper, chocked full of useful and interesting details. James Hamilton wrote an excellent summary of the paper in Google Megastore: The Data Engine Behind GAE. There are also a few useful threads in Google Groups that go into some more details about how it works, costs, and performance (the original announcement, performance comparison).
Some Megastore highlights:
Click to read more ...















 HighScalability Team
HighScalability Team


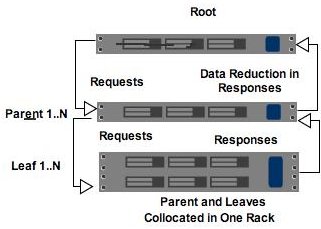

 If you could harness the
If you could harness the 