Snuggling Up to Papers We Love - What's Your Favorite Paper?

From a talk by @aysylu22 at QCon London on modern computer science applied to distributed systems in practice.
"CS research is timeless." Lessons learned are always pertinent. @aysylu22 #qconlondon
— Paula Walter (@paulacwalter) March 8, 2016
There has been a renaissance in the appreciation of computer science papers as a relevant source of wisdom for building today's complex systems. If you're having a problem there's likely some obscure paper written by a researcher twenty years ago that just might help. Which isn't to say there aren't problems with papers, but there's no doubt much of the technology we take for granted today had its start in a research paper. If you want to push the edge it helps to learn from primary research that has helped define the edge.
If you would like to share your love of papers, be proud, you are not alone:
- There's a very active Papers We Love Twitter account. And a Facebook group.
- There's a Papers We Love website that lists all the Papers We Love meetups from around the world. And there are lots of them. Here's the meetup for SF, New York, London, Bangalore, Singapore.
- Even better, many of those meetups are recorded and you can find the video on YouTube.
- There's a GitHub repository of Papers We Love.
- Papers have become so popular there's even a well developed black market. Sci-Hub Helps Science 'Pirates' to Download 100,000s of Papers Per Day. There's no truth to the rumor that papers are aphrodisiacs. Or Should All Research Papers be Free?
- Adrian Colyer is an indefatigable source of papers with his always illuminating the morning paper blog. You may also like References from Adrian Colyer's QCon London 2016 Keynote.
- Murat Demirbas will often cover important papers/research at an in-depth level in his excellent Metadata blog.
- Many companies have brown bag lunches or paper reading groups. You may want to start your own.
- Over the years I've also shared a few papers on HighScalability.
What's Your Favorite Paper?
If you ask your average person they'll have a favorite movie, book, song, or Marvel Universe character, but it's unlikely they'll have have a favorite paper. If you've made it this far that's probably not you.
My favorite paper of all time is without a doubt SEDA: An Architecture for Well-Conditioned, Scalable Internet Services. After programming real-time distributed systems for a long time I was looking to solve a complex work scheduling problem in a resource constrained embedded system. I stumbled upon this paper and it blew my mind. While I determined that the task scheduling latency of SEDA wouldn't be appropriate for my problem, the paper gave me a whole new way to look out how programs were structured and I used those insights on many later projects.
If you have another source of papers or a favorite paper please feel free to share.
 HighScalability Team
HighScalability Team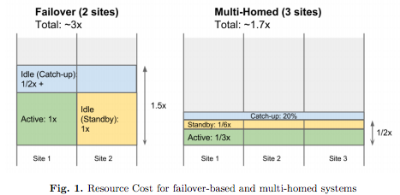
 Underutilization and segregation are the classic strategies for ensuring resources are available when work absolutely must get done. Keep a database on its own server so when the load spikes another VM or high priority thread can't interfere with RAM, power, disk, or CPU access. And when you really need fast and reliable networking you can't rely on QOS, you keep a dedicated line.
Underutilization and segregation are the classic strategies for ensuring resources are available when work absolutely must get done. Keep a database on its own server so when the load spikes another VM or high priority thread can't interfere with RAM, power, disk, or CPU access. And when you really need fast and reliable networking you can't rely on QOS, you keep a dedicated line.