Thursday
Oct312013
Paper: Everything You Always Wanted to Know About Synchronization but Were Afraid to Ask

Awesome paper on how particular synchronization mechanisms scale on multi-core architectures: Everything You Always Wanted to Know About Synchronization but Were Afraid to Ask.
The goal is to pick a locking approach that doesn't degrade as the number of cores increase. Like everything else in life, that doesn't appear to be generically possible:
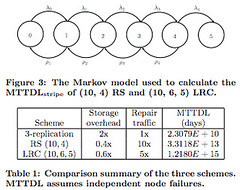
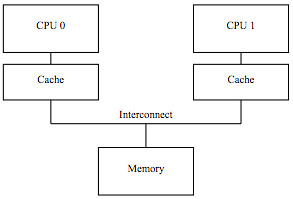
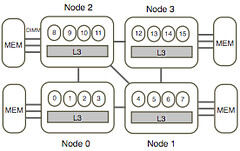
None of the nine locking schemes we consider consistently outperforms any other one, on all target architectures or workloads. Strictly speaking, to seek optimality, a lock algorithm should thus be selected based on the hardware platform and the expected workload.
Abstract:
 HighScalability Team
HighScalability Team