Famous computer scientist John Backus, he's the B in BNF(Backus-Naur form) and the creator of Fortran, gave a Turing Award Lecture titled Can programming be liberated from the von Neumann style?: a functional style and its algebra of programs, that has layed out a division in programming that lives long after it was published in 1977.
It's the now familiar argument for why functional programming is superior:
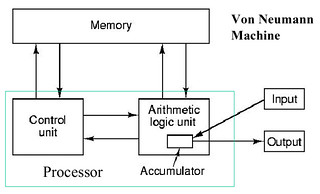
The assignment statement is the von Neumann bottleneck of programming languages and keeps us thinking in word-at-a-time terms in much the same way the computer's bottleneck does.
...
The second world of conventional programming languages is the world of statements. The primary statement in that world is the assignment statement itself. All the other statements of the language exist in order to make it possible to perform a computation that must be based on this primitive construct: the assignment statement.
Here's a response by Dijkstra A review of the 1977 Turing Award Levgure by John Backus. And here's an interview with Dijkstra.
Great discussion on a recent Hacker News thread and an older thread. Also on Lambda the Ultimate. Nice summary of the project by David Bolton.
There's nothing I can really add to the discussion as much smarter people than me have argued this endlessly. Personally, I'm more of a biology than a math and a languages are for communicating with people sort of programmer. So the argument from formal systems have never persuaded me greatly. Doing a proof of a bubble sort in school was quite enough for me. Its applicability to real complex systems has always been in doubt.
The problem of how to best utilize distributed cores is a compelling concern. Though the assumption that parallelism has to be solved at the language level and not how we've done it, at the system level, is not as compelling.
It's a passionate paper and the discussion is equally passionate. While nothing is really solved, if you haven't deep dived into this dialogue across the generations, it's well worth your time to do so.














 HighScalability Team
HighScalability Team