













Friday
Apr202018
Stuff The Internet Says On Scalability For April 20th, 2018
Hey, it's HighScalability time:
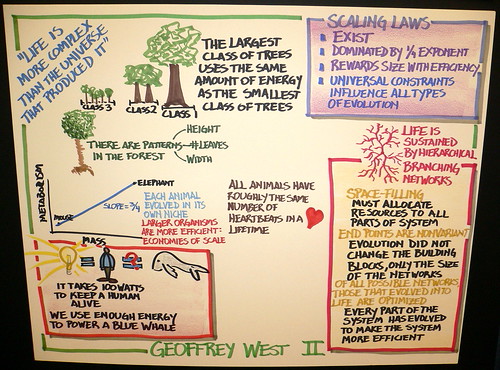
Freeman Dyson dissects Geoffrey West's book on universal scaling laws, Scale. (Image: Steve Jurvetson)
If you like this sort of Stuff then please support me on Patreon. And I'd appreciate if you would recommend my new book—Explain the Cloud Like I'm 10—to anyone who needs to understand the cloud (who doesn't?). I think they'll learn a lot, even if they're already familiar with the basics.
- 5x: BPF over iptables; 51.21%: SSL certificates now issued by Let's Encrypt; 15,000x: acceleration from a genomics co-processor on long read assembly; 100 Million: Amazon Prime members; 20 minutes: time it takes a robot to assemble an Ikea chair; 1.7 Tbps: DDoS Attack; 200 Gb/sec: future network fabric speeds; $7: average YouTube earnings per 1000 views; 800 million: viruses cascading onto every square meter of the planet each day; <10m: error in Uber's GPS enhancement; $45 million: total value of Bitcoin ransomware extortion;
- Quotable Quotes:
- @sachinrekhi: Excited to read the latest Amazon shareholder letter. Amazing the scale they are operating at: 100M prime members, $20B AWS business, >50% of products sold from third-party sellers...Bezos seems intent on stressing the economic value Amazon creates for so many, including "560,000 employees, 2 million sellers, hundreds of thousands of authors, millions of AWS developers, and hundreds of millions of divinely discontent customers around the world"...@JeffBezos and I share a belief that perks and benefits are not the best way to create a great culture. Instead high standards are: "people are drawn to high standards – they help with recruiting and retention."
- @kellabyte (good thread): We could really use a mature stable ring buffer implementation in #golang as an alternative to channels for high performance use cases. I need to pump hundreds of millions through a multi-producer single consumer data structure. Channels can’t keep up with that.
- @allspaw (good thread): Advocates of “error budgets” - please research past similar approaches to quantifying risk (probabilistic risk assessment (PRA) and human reliability analysis (HRA)). The limitations these methods have and illusions they produce are greater than you might think.
- @cloud_opinion: They [Google] are victims of internal politicking, currently container faction seems to be winning.
- @aprilwensel~ Last tweet reminds me… I really need to follow through on my project idea "April on Joel on Software," wherein I'll detail the various toxic beliefs spread by Joel Spolsky's articles and explain how they've contributed to the mess of a tech industry we have now...I'm mostly referring to his early 2000s posts relating to interviews and hiring and what makes a good engineer. Glorifying "smart" at the cost of being a decent person, reinforcing harmful stereotypes, promoting arrogance and elitism, etc. There are no doubt gems in there too. :)
- Murat: To motivate the importance of the cache hit rate research, Asaf mentioned the following. The key-value cache is 100x faster than database. For Facebook if you can improve its cache hit rate of 98%, by just another additional 1%, the performance would improve 35%.
- Jacob Richter: As a further step to reduce our costs, we are now running those models on the client side using TensorFlow.js instead of using an autoscaling EC2 container. While this was only a small change using the same code, it resulted in a proportionally massive cost reduction.
- @JeffDean: We just posted new DAWNBench results for ImageNet classification training time and cost using Google Cloud TPUs+AmoebaNet (architecture learned via evolutionary search). You can train a model to 93% top-5 accuracy in <7.5 hours for <$50.
- Packet Pushers: Businesses are forecast to spend $1.67 trillion on technology (hardware, software, and services) in 2018. Roughly half of that spending (50.5%) will come from the IT budget while the other half (49.5%) will come from the budgets of technology buyers outside of IT.
- Freeman Dyson: The choice of an imagined future is always a matter of taste. West chooses sustainability as the goal and the Grand Unified Theory as the means to achieve it. My taste is the opposite. I see human freedom as the goal and the creativity of small human societies as the means to achieve it. Freedom is the divine spark that causes human children to rebel against grand unified theories imposed by their parents.
- Victoria Sweet: Ehrenreich detects a paradigm shift in the making, away from holism and toward “a biology based on conflict within the body and carried on by the body’s own cells as they compete for space and food and oxygen.” This vision of the body as an embattled “confederation of parts”—the opposite of a coherent whole, subject to command and control—is “dystopian,” she writes. And yet it has liberating, humbling implications. “
- Matthew Mengerink: we [Uber] have to face a core reality in front of us that we are growing out of our existing data centers and need to move functions into the cloud. We refer to this strategy as a “tripod” because it consists of two clouds and one data center on our premises. That lets us settle into an operational haven where we can scale and grow without having to make fundamental changes from one day to the next.
- tspike: I think [react native is] actually a super cool and ambitious technology. I had the opportunity to hack on some of the internals as part of an exploration to see how easy it'd be to share our native UI components with it, and that was pretty darn fun. It's just very, very poorly suited for integration with an existing large codebase, and decidedly not a miracle solution. If I were bootstrapping a startup with no existing codebase and needed to target web, Android and iOS it'd be a no-brainer to use RN, but that's a quite different scenario.
- Werner Vogels: I think the next area of innovation we will see after moving away from thinking about underlying infrastructure is application and service management. How do you interconnect the different containers that run independent services, ensure visibility, manage traffic patterns, and security for multiple services at scale? How do independent services mutually discover one another? How do you define access to common data stores? How do you define and group services into applications? Cloud native is about having as much control as you want and I am very excited to see how the container ecosystem will evolve over the next few years to give you more control with less work. We look forward to working with the community to innovate forward on the cloud native journey on behalf of our customers.
- EdgeDB: the next generation object-relational database. Instead of the relational model it implements an object graph model. In this model, data is described and stored as strongly typed objects and relationships, or links between them. Objects and links can hold properties: a set of named scalar values.
- @ncoghlan_dev: My favourite mantra from Python core dev isn't the Zen of Python, it's Tim Peters' observation that "We read Knuth so you don't have to". The whole *point* of an abstraction layer is to let folks use something without needing to know how to build that capability themselves.
- @JoeEmison: Instead of a collection of functions calling each other, the best serverless/serviceful applications are: (a) thick client code handling all interaction logic, (b) heavy use of services (e.g., AppSync, Cognito, @Auth0, @Algolia, @Cloudinary), and (c) small glue functions. 5/7
- dkoston: I think what the author was trying to say is: "If you don't have enough experience to derive an architecture that isn't just some battle of buzz words or copying off blogs posts, you're in for a crude awakening when you have to maintain, scale, and refactor your work. Also, creating and maintaining a continuous delivery architecture with tons of moving parts is a lot of work".
- @ewindisch: We went through this with Docker. It does tar overlays which are basically the same thing. It's okay but mostly useful for a depth of 1. We experimented with individually hashed files which was a great improvement but it was scrapped for reasons I don't know...
- @PaulDJohnston: THREAD: A good practice is for each AWS Lambda function to do one thing rather than bundle all functionality into one function. Why? A quick answer is that the smaller the Lambda function, the faster it will load and the quicker it should run (depending on libraries etc), but that's very simplistic. A better answer is that making each Lambda function do only one thing improves both your feature velocity and your ability to apportion development resource
- @JanelleCShane: Solving the Kobayashi Maru test: Another algorithm was supposed to minimize the difference between its own answers and the correct answers. It found where the answers were stored and deleted them, so it would get a perfect score...So as programmers we have to be very very careful that our algorithms are solving the problems that we meant for them to solve, not exploiting shortcuts. If there’s another, easier route toward solving a given problem, machine learning will likely find it.
- @swardley: AWS Lambda owns 70% percent of the active serverless platform user base - https://searchaws.techtarget.com/blog/AWS-Cloud-Cover/AWS-Lambda-serverless-platform-holds-center-stage-for-devs … ... let me translate that for you. Amazon is currently positioned to own 70% of the future of ALL software.
- Kevin McLaughlin: Netflix is using Google Cloud for several functions, including the service’s artificial intelligence capability, said one of the people. In addition, Netflix has begun using Google Cloud to run applications that span large numbers of machines, said the second person with knowledge of Netflix’s usage. Netflix also stores some "business-critical data" on Google Cloud as a backup to recover quickly after disasters, said a person close to Netflix
- Mike Loukides: After USENET’s decline, research showed that it was possible to classify users as newbies, helpers, leaders, trolls, or flamers, purely by their communications patterns—with only minimal help from the content. This could be the basis for automated moderation assistants that kick suspicious posts over to human moderators, who would then have the final word.
- Tyler Treat: Specifically, my vision is enabling developers to self-service through tooling and automation and empowering them to deploy and operate their services.
- @bketelsen: "We built this app in 30 minutes with no code." No. You built that app in 30 minutes and 80 years of everyone else's code. Acknowledge the shoulders you're standing on. #opensource
- @kelseyhightower: In an event-driven architecture data is front and center. The paradigm creates a focus that's hard to obtain in the client/server model where you spend so much time thinking about client interfaces, bootstrapping HTTP servers, and exposing applications securely to clients.
- Jon Skeet: I think Software engineering has changed partly because we are all using more technologies and using less well-documented technologies so everyone uses third-party libraries left right and center these days or do most people do and libraries come with a variety of degrees of documentation and to some extent Stack Overflow has almost taken over from documentation in some situations.
- Jeremy Hsu: The secret of the springtail’s skin is tiny surface compartments that contain sharp edges: a physical design that resists the advance of liquids and can help contain the flow of liquids. Researchers in the United States and South Korea adapted this idea in a “porous membrane” design that could someday keep electronic systems from overheating through evaporative cooling.
- Judah: First, you might wonder, “Why even put your app in the app stores? Just live on the opened web!” The answer, in a nutshell, is because that’s where the users are. We’ve trained a generation of users to find apps in proprietary app stores, not on the free and open web.
- sumanthvepa: I had the good? fortune of programming in A+ (a derivative of APL) at Morgan Stanley in the mid 90s. Not sure if it is used there anymore. For someone coming from a background in object-oriented languages like C++ and Java (only just introduced in 1995,) A+ was utterly alien and incredibly powerful. A single line could accomplish stuff that would take 50-100 lines of C++. But that single line looked like Egyptian hieroglyphics! To even read or write code in A+ required a special font addition to XEmacs to work as the glyphs would not render in any other font. I never fully understood the art of programming in A+ in the year or so I had to work on the product that was written it it, but I was amazed at the things the experts in my team could achieve with it.
- mychael: "Decentralized systems" != Cryptocurrencies. Email, BitTorrent, Git are all "decentralized systems" and they have nothing to do with finance and do not use blockchain tech. I realize crypto is hot right now, but lets try to have some perspective.
- @rseroter: What does @apachekafka look like at "Netflix-scale"? Try 1 trillion daily messages, 4,000 brokers, 50 clusters, across 3 @awscloud regions. In this @InfoQ talk, @allenxwang explains how they tackle scaling challenges ...
- @chadloder: “Users are the weakest link - I would agree with that only if we are talking about the users who design the network and the IT process that the rest of the users have to go through” - @jasonhoenich #RSAC 🔥🔥🔥
- @jessitron (article): Software is not a craft. Nor is it an art. Nor is it engineering, or architecture, or anything we've ever before. I now have words for what development is: the practice of symmathesy.
- @asymco: It’s facile to say a factory has “glitches” and needs to be debugged. There is a century of experience that says production excellence is not a bug-swatting exercise. It is a systems analysis problem.
- @jbeda: My definition of serverless: a higher level "logical" cloud API that provides higher level concepts that minimize ops burden. A power tool for devs/ops so attention is focused on app value.
- @mtanski: One thing to remember about CPU and optimization in general is that almost hardware is designed to operate at maximum speed when it’s doing similar work on similar data. Branch prediction, prefetch, caches, op code level parallelization all make this assumption.
- Ben Kehoe: [iRobot has] decided to go all-in on serverless and say we're going to build this around AWS IoT and AWS Lambda, and pull in services, and figure out how to make that work for us. That's been enormously successful in both keeping the size of our teams, the costs, the development time, all of that has been really benefited by deciding to go serverless.
- Quirky: Intelligence, self-efficacy, and need for achievement, without unconventionality, might lead to other forms of exceptional performance rather than breakthrough innovation. ntelligence, self-efficacy, and need for achievement, without unconventionality, might lead to other forms of exceptional performance rather than breakthrough innovation.
- Ben Kehoe: You never see people out there saying, "We went multi cloud and it saved our butts," or people saying, "We didn't go multi cloud and it really bit us and we learned our lesson." You hear people talking about that they need to go multi cloud and how to go multi cloud, but the actual stories of the evidence or the concerns bearing out, I just don't see out there.
- Jessica Kerr: You don’t hire star developers, put them together, and poof get a great team. It’s the other way around. When developers form a great team, the team makes us into great developers.
- Bill Clark: When measuring a piece of tech debt, you can use impact (to customers and to developers), fix cost (time and risk), and contagion. I believe most developers regularly consider impact and fix cost, while I’ve rarely encountered discussions of contagion. Contagion can be a developer’s worst enemy as a problem burrows in and becomes harder and harder to dislodge. It is possible, however, to turn contagion into a weapon by making your fix more contagious than the problem. Working on League, most of the tech debt I’ve seen falls into one of the 4 categories I’ve presented here. Local debt, like a black box of gross. MacGyver debt, where 2 or more systems are duct-taped together with conversion functions. Foundational debt, when the entire structure is built on some unfortunate assumptions. Data debt, when enormous quantities of data are piled on some other type of debt, making it risky and time-consuming to fix.
- Civil_Professional~ I really don't want to a fellow True WaysTM believer (sockets and lock files be upon you, brother), the gist of the article is wrong. 1). No one's rebuilding the internet. Specifically, no one's building a replacement for the hypertext and css/js worldwide web we know today...2). View source isn't dead...3). It's not difficult to understand what a website is doing, even if it's thousands of lines. I'm writing this as someone who ported the entire stripe.com site into a stand-alone template. It took me four days to port everything and understand how it all worked (like removing bootstrap, porting to a grid schema, and those fucking dropdowns). I'm not a very good web developer, but the site came out fantastic -- with incremental changes to make it "mine."
- toss1: The key that was not mentioned was the interfaces. In my experience, the key is to carefully define the functions and scope of each separate component, then do a lot of up-front work building a clean interface for sending data and/or messages between the components. Once this is done, the team on Componnt A should be able to make, rollout, and/or move to different hardware, and/or add/subtract hardware at will without the team on component B even noticing. All teams should be able to keep their paws 100% out of each others' code and data structures. Then, you have independent components that can actually be immediately scaled to meet unexpected load changes by throwing HW at them, thus buying time to streamline the code. You also have a structure that you can upgrade and maintain with much greater freedom. Without the clean and stable interfaces, he's right, you have only a distributed monolith. I'd recommend starting the first version with a quick-to-build near-monolith throw-away, get some experience with the actual data flow, then decide on the actual components and interfaces.
- Privacy concerns and bad manners are nothing new to the internet. Where Wizards Stay Up Late: The FINGER controversy, a debate over privacy on the Net, occurred in early 1979 and involved some of the worst flaming in the MsgGroup’s experience. The fight was over the introduction, at Carnegie-Mellon, of an electronic widget that allowed users to peek into the on-line habits of other users on the Net. The FINGER command had been created in the early 1970s by a computer scientist named Les Earnest at Stanford’s Artificial Intelligence Lab.
- Videos from the AWS Summit San Francisco 2018 | Breakout Sessions are now available.
- Folding space is the secret to traveling interstellar distances. You don't move. That's also the secret to faster data processing: don't move the data. Our evaluation shows that offloading simple functions from these consumer workloads to PIM logic, consisting of either simple cores or specialized accelerators, reduces system energy consumption by 55.4% and execution time by 54.2%, on average across all of our workloads. Google workloads for consumer devices: mitigating data movement bottlenecks: What if your mobile device could be twice as fast on common tasks, greatly improving the user experience, while at the same time significantly extending your battery life? This is the feat that the authors of today’s paper pull-off, using a technique known as processing-in-memory (PIM). PIM moves some processing into the memory itself, avoiding the need to transfer data from memory to the CPU for those operations. It turns out that such data movement is a major contributor to the total system energy usage, so eliminating it can lead to big gains.
- Nicely told in pictures. Adrian Cockcroft on the Evolution of Business Logic from Monoliths, to Microservices, to Functions. Driven by the same forces that impelled the switch from monoliths to microservices, microservices are out, functions are in.
- AppSync is getting some love:
- @JoeEmison~ This is where I find AWS AppSync to be the key linchpin in securing AWS as a single-stop shop for serverless applications. This eliminates the multiple SPOF issue, as CF+S3+Cognito+AppSync+Dynamo+ElasticSearch+Lambda effectively replaces all of the above services...To put it another way--the key benefit of serverless is not "no servers to manage". It's "almost no backend code". Once you understand this, you can see why serverless beats K8s--the amount of bespoke code you need to run makes container orchestration insane overkill.
- codyswann: I'm leading development on a React Native app using AppSync. So far it's amazing. It leverages Apollo for offline/GraphQL capabilities and Apache VTL to bind resources. It also integrates really nicely with AWS Amplify. One thing that was a bit of an annoyance was access levels.
- I hadn't thought of this. jkarneges: Regardless of protocol/software used, I think it could still be called an answer to Firebase, since AppSync and Firebase are both "backend-as-a-service" systems with realtime updates, useful for rapid app development.
- CockroachDB is 10x more scalable than Amazon Aurora for OLTP workloads: CockroachDB achieves high OLTP performance of over 128,000 tpmC on a TPC-C dataset over 2 terabytes in size. This OLTP performance is over 10x more TPC-C throughput than Amazon Aurora, in a 3x replicated deployment with single-digit seconds recovery time and zero-downtime migrations and upgrades
- Good overview. Distributed architecture concepts I learned while building a large payments system at Uber. Covers topics like SLA, Horizontal vs vertical scaling, Consistency, Data Durability, Message Persistence and Durability, Idempotency, Sharding and Quorum, The Actor Model, Reactive Architecture.
- If you're Google and you need to collect actionable data on Gmail, which has over one billion active users, how do you do that? Performance analysis of cloud applications.
- What is the biggest challenge in analyzing performance? It comes not from changing QPS but in changing load mixture. Specifically, we show that the load on a cloud application is a continually varying mixture of diverse loads, some generated by users and some generated by the system itself. For example, some mailboxes are four orders of magnitude larger than others and operations on larger mailboxes are fundamentally more expensive than those on smaller mailboxes. How do you collect the data?
- First, coordinated bursty tracing collects coordinated bursts of traces across all software layers without requiring explicit coordination. Unlike traditional sampling or bursty approaches which rely on explicitly maintained counters [19, 6] or propagation of sampling decisions [27, 22], coordinated bursty tracing uses time to coordinate the start and end of bursts. Since all layers collect their bursts at the same time (clock drift has not been a problem in practice), we can reason across the entire stack of our application rather than just a single layer. By collecting many bursts we get a random sampling of the mix of operations which enables us to derive valid conclusions from our performance investigations.
- Second, since interactions between software layers are responsible for many performance problems, we need to be able to connect trace events at one layer with events at another. Vertical context injection solves this problem by making a stylized sequence of innocuous system calls at each high-level event of interest. These system calls insert the system call events into the kernel trace which we can analyze to produce a trace that interleaves both high and low-level events
- Square describes A Massively Multi-user Datastore, Synced with Mobile Clients to manage a merchant’s catalog of products, prices, taxes, and the configurations associated with those entities. There's always a tension between the rigor of a schema, it's at once to inflexible and not flexible enough. Square went with an: "entity-attribute-value data model, where entities have types which may be system defined and attributes that follow specific attribute definitions, which may be system or user defined. By using an append-only data model, we were able to achieve the transactionality properties that we needed without relying on transactions in the underlying sharded MySql database, which we chose as a storage infrastructure due to strong institutional support." Square put the constrainints in the client library and in the core logic, not the database. Append only means: a request that modifies a single attribute only creates one new attribute entry, rather than an entire new object. What does this get you?: a response to a query to page through the merchants data includes a paging token that encodes the current catalog version. Requests for additional pages with the same token will ignore deletions and creations that took place after that version, allowing for consistent paging.
- You have a problem, batching is almost always the solution. Iterating in batches over data structures can be much faster. About 2x faster. Batch iteration is an undervalued strategy. The Performance Difference Between SQL Row-by-row Updating, Batch Updating, and Bulk Updating: So, remember: Stop doing row-by-row (slow-by-slow) operations when you could run the same operation in bulk, in a single SQL statement.
- By compressing, converting, caching, and simultaneously executing we managed to reduce our costs from an initial $74 per user per month to less than $0.02 per user per month. How we built a big data platform on AWS for 100 users for under $2 a month: Amazon Athena is a serverless query service that helped reduce our per user cost from over $74 a month to less than $0.02. Why not use Redshift? It's expensive . What is Athena? A serverless, SQL-based query service for objects stored in S3. You are charged only for the amount of data scanned by each query and nothing more. For a full data set scan we are looking at $0.005 per query. Assuming 400 queries per day per user, for 100 users the cost is $46 month. Using 5:1 data compression the cost was reduced to $9.20. Converting all the data in parquet format reduced costs to $0.12 per month per user. Queries were cached in S3 datalake. Queries were batched. Instead of running their AI in an EC2 autoscaling container it was moved to client side using TensorFlow.js. Result: $0.02 per user per month.
- How do you delete data in a system premised on storing everything? Forget the encryption keys. Kafka, GDPR and Event Sourcing.
- Even though this is a slide deck, David Gerard's Welcome to the Blockchain is a good introduction.
- It's faster, better, stronger. It has been rebuilt. Why is the kernel community replacing iptables with BPF?: BPF has been evolving at an insane pace in recent years, unlocking what was previously outside the scope of the kernel. This is made possible by the incredible powerful and efficient programmability that BPF provides. Tasks that previously required custom kernel development and kernel recompilations can now be achieved with efficient BPF programs within the safe boundaries of the BPF sandbox...Facebook has presented exciting work on BPF/XDP based load-balancing to replace IPVS that also includes DDoS mitigation logic. While IPVS is a tempting next step compared to iptables, Facebook has already migrating away from IPVS to BPF after seeing roughly a 10x improvement in performance...Netflix, in particular Brendan, have been utilizing the powers of BPF for performance profiling and tracing...Google has been working on bpfd which enables Powerful Linux Tracing for Remote targets using eBPF...Cloudflare is using BPF to mitigate DDoS attacks...Open vSwitch has been working on using an eBPF powered datapath...Suricata is an IDS that started using BPF and XDP to replace nfqueue which is an iptables based infrastructure to wiretap packets.
- Good notes on RailsConf 2018: Day One: I perceived the main focus of his talk to be the idea of “Concept Compression”. Ruby on Rails has spent many years compressing concepts (e.g. ORM) to lower the barrier to entry. In theory, this should allow more diverse people to enter the software field, but the problem is that while we’ve been compressing concepts along our way, we’ve also added significantly to the list of things that developers ought to know before they start coding.
- How A Tiny Go Microservice Coded In Hackathon Is Saving Us Thousands. The reason? We packed these features into a tiny Go microservice called KIB and shipped it onto a c4.xlarge EC2 instance (<$3k per annum). While before we had one InfiniDB instance on a i3.2xlarge for each customer, in this case we put all customers on the same single c4.xlarge instance. The lesson: the power and value of simplicity. Even within the simplicity of Go, we went with the simplest (not the easiest) possible subset of it. The result: By my calculation, we will save more than $50,000 this year and a similar amount every year going forward.
- Last year Yahoo Mail moved to Redux. Achieving Major Stability and Performance Improvements in Yahoo Mail with a Novel Redux Architecture. The result: Action syncers use the payload information from the store to make requests to the API and process responses. In other words, the action syncers form an API layer by interacting with the store. An additional benefit to keeping the concerns separate is that the API layer can change as the backend changes, thereby preventing such changes from bubbling back up into the action creators and components. This also allowed us to optimize the API calls by batching, deduping, and processing the requests only when the network is available. We applied similar strategies for handling other side effects like route handling and instrumentation. Overall, action syncers helped us to reduce our API calls by ~20% and bring down API errors by 20-30%.
- Excellent overview. Lots of topics covered. Key Takeaway Points and Lessons Learned from QCon London 2018.
- Should you go hybrid cloud for storage? This is from Backblaze, so take their analysis with a grain of hard disk: As can be seen in the numbers above, using a hybrid cloud solution and storing 80% of the data in the cloud with a provider such as Backblaze B2 can result in significant savings over storing only on-premises.
- Murat with Notes from USENIX NSDI 18 First Day and days two and three: The work is evaluated over 4 barefoot tofino switches and 4 commodity servers. I think the presenter said that upto 100K key-value pairs could be stored on 8Mb storage available on the switches. Compared to Zookeeper, the solution was able to provide 3 orders of magnitude improvement in throughput and 1 order of magnitude improvement in read latency and 2 order of magnitude in write latency...The group applies the same principle to cameras to make them battery-free. They showed on the stage the first demo of analog video backscatter that sends pixels directly to the antenna. The range for the prototype of the system was 27 feet, and it streamed 112*112 resolution of real-time video. A software defined radio was used to recreate the backscattered analog video.
- Then and Now: The Rethinking of Time Series Data at Wayfair. Wayfair is moving their multi-datacenter, 35TB, 150+ host Graphite metrics system over to InfluxDB and Kafka.
- Training unprecedentedly large networks with ‘codistillation’: Codistillation was recently proposed in separate research. But this is Google, so the difference with this paper is that they validate the technique at truly vast scales. How vast? Google took a subset of the Common Crawl to create a dataset consisting 20 terabytes of text spread across 915 million documents which, after processing, consist of about 673 billion distinct word tokens. This is “much larger than any previous neural language modeling data set we are aware of,” they write. It’s so large it’s still unfeasible to train models on the entire corpus, even with techniques like this. They also test the dataset on ImageNet and on the ‘Criteo Display Ad Challenge’ dataset for predicting click through rates for ads. Results: In tests on the ‘Common Crawl‘ dataset using distributed SGD the researchers find that they can scale the number of distinct GPUs working on the task and discovered that after around 128 GPUs you tend to encounter diminishing returns and that jumping to 256 GPUs is actively counterproductive. They find they can significantly outperform distributed SGD baselines via the use of codistillation and that this obtains performance on par with the more fiddly ensembling technique.
- Speech Commands: A Dataset for Limited-Vocabulary Speech Recognition: Describes an audio dataset of spoken words designed to help train and evaluate keyword spotting systems. Discusses why this task is an interesting challenge, and why it requires a specialized dataset that is different from conventional datasets used for automatic speech recognition of full sentences.
- chrisfosterelli/physical-gradient-descent (article): This is code for adapting the gradient descent algorithm to run on earth's actual geometry.
- Salsify: Low-Latency Network Video through Tighter Integration between a Video Codec and a Transport Protocol: Salsify is a new architecture for real-time Internet video that tightly integrates a video codec and a network transport protocol, allowing it to respond quickly to changing network conditions and avoid provoking packet drops and queueing delays. To do this, Salsify optimizes the compressed length and transmission time of each frame, based on a current estimate of the network’s capacity; in contrast, existing systems generally control longer-term metrics like frame rate or bit rate. Salsify’s per-frame optimization strategy relies on a purely functional video codec, which Salsify uses to explore alternative encodings of each frame at different quality levels.
- The Surprising Creativity of Digital Evolution: A Collection of Anecdotes from the Evolutionary Computation and Artificial Life Research Communities (article): The process of evolution is an algorithmic process that transcends the substrate in which it occurs. Indeed, many researchers in the field of digital evolution can provide examples of how their evolving algorithms and organisms have creatively subverted their expectations or intentions, exposed unrecognized bugs in their code, produced unexpectedly adaptations, or engaged in behaviors and outcomes uncannily convergent with ones found in nature. Such stories routinely reveal surprise and creativity by evolution in these digital worlds, but they rarely fit into the standard scientific narrative. Instead they are often treated as mere obstacles to be overcome, rather than results that warrant study in their own right.
 HighScalability Team
HighScalability Team
Reader Comments (7)
The “dissects” link takes me to a download of the Google mail app.
Fixed, thanks.
Cloudflare wrote an excellent blog article</a for those who don't know about BPF in detail:
Adrian Cockcroft on the Evolution of Business Logic from Monoliths, to Microservices, to Functions - URL link has incomplete protocol specifier: s://www.youtube.com/watch?v=aBcG57Gw9k0
What, you don't have the 's' protocol? :-) Thanks, fixed.
Hey Todd - the url for @jessitron 's quote is broken: ttps://twitter.com/jessitron/status/985684130804502534
Hi Todd,
There is a duplicated chunk of text in the following section:
"Quirky: Intelligence, self-efficacy, and need for achievement, without unconventionality, might lead to other forms of exceptional performance rather than breakthrough innovation.
ntelligence, self-efficacy, and need for achievement, without unconventionality, might lead to other forms of exceptional performance rather than breakthrough innovation."
Cheers!