The Story of Batching to Streaming Analytics at Optimizely
Our mission at Optimizely is to help decision makers turn data into action. This requires us to move data with speed and reliability. We track billions of user events, such as page views, clicks and custom events, on a daily basis. To provide our customers with immediate access to key business insights about their users has always been our top most priority. Because of this, we are constantly innovating on our data ingestion pipeline.
In this article we will introduce how we transformed our data ingestion pipeline from batching to streaming to provide our customers with real-time session metrics.
Motivations
Unification. Previously, we maintained two data stores for different use cases - HBase is used for computing Experimentation metrics, whereas Druid is used for calculating Personalization results. These two systems were developed with distinctive requirements in mind:
|
Experimentation |
Personalization |
|
Instant event ingestion |
Delayed event ingestion ok |
|
Query latency in seconds |
Query latency in subseconds |
|
Visitor level metrics |
Session level metrics |
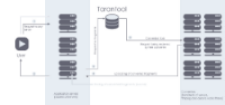
As our business requirements evolve, however, things quickly became difficult to scale. Maintaining a Druid + HBase Lambda architecture (see below) to satisfy these business needs became a technical burden for the engineering team. We need a solution that reduces backend complexity and increases development productivity. More importantly, a unified counting infrastructure creates a generic platform for many of our future product needs.
Consistency. As mentioned above, the two counting infrastructures provide different metrics and computational guarantees. For example, Experimentation results show you the number of visitors visited your landing page whereas Personalization shows you the number of sessions instead. We want to bring consistent metrics to our customers and support both type of statistics across our products.
Real-time results. Our session based results are computed using MR jobs, which can be delayed up to hours after the events are received. A real-time solution will provide our customers with more up-to-date view of their data.
Druid + HBase
In our earlier posts, we introduced our backend ingestion pipeline and how we use Druid and MR to store transactional stats based on user sessions. One biggest benefit we get from Druid is the low latency results at query time. However, it does come with its own set of drawbacks. For example, since segment files are immutable, it is impossible to incrementally update the indexes. As a result, we are forced to reprocess user events within a given time window if we need to fix certain data issues such as out of order events. In addition, we had difficulty scaling the number of dimensions and dimension cardinality, and queries expanding long period of time became expensive.
On the other hand, we also use HBase for our visitor based computation. We write each event into an HBase cell, which gave us maximum flexibility in terms of supporting the kind of queries we can run. When a customer needs to find out “how many unique visitors have triggered an add-to-cart conversion”, for example, we do a scan over the range of dataset for that experimentation. Since events are pushed into HBase (through Kafka) near real-time, data generally reflect the current state of the world. However, our current table schema does not aggregate any metadata associated with each event. These metadata include generic set of information such as browser types and geolocation details, as well as customer specific tags used for customized data segmentation. The redundancy of these data prevents us from supporting large number of custom segmentations, as it increases our storage cost and query scan time.
 Vignesh Sukumar
Vignesh Sukumar