













Neo4j - a Graph Database that Kicks Buttox
Update: Social networks in the database: using a graph database. A nice post on representing, traversing, and performing other common social network operations using a graph database.
If you are Digg or LinkedIn you can build your own speedy graph database to represent your complex social network relationships. For those of more modest means Neo4j, a graph database, is a good alternative.
A graph is a collection nodes (things) and edges (relationships) that connect pairs of nodes. Slap properties (key-value pairs) on nodes and relationships and you have a surprisingly powerful way to represent most anything you can think of. In a graph database "relationships are first-class citizens. They connect two nodes and both nodes and relationships can hold an arbitrary amount of key-value pairs. So you can look at a graph database as a key-value store, with full support for relationships."
A graph looks something like: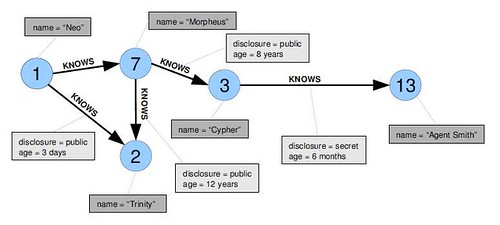
For more lovely examples take a look at the Graph Image Gallery.
Here's a good summary by Emil Eifrem, founder of the Neo4j, making the case for why graph databases rule:
Most applications today handle data that is deeply associative, i.e. structured as graphs (networks). The most obvious example of this is social networking sites, but even tagging systems, content management systems and wikis deal with inherently hierarchical or graph-shaped data.
This turns out to be a problem because it’s difficult to deal with recursive data structures in traditional relational databases. In essence, each traversal along a link in a graph is a join, and joins are known to be very expensive. Furthermore, with user-driven content, it is difficult to pre-conceive the exact schema of the data that will be handled. Unfortunately, the relational model requires upfront schemas and makes it difficult to fit this more dynamic and ad-hoc data.
A graph database uses nodes, relationships between nodes and key-value properties instead of tables to represent information. This model is typically substantially faster for associative data sets and uses a schema-less, bottoms-up model that is ideal for capturing ad-hoc and rapidly changing data.
So relational database can't handle complex relationships. Graph systems are opaque, unmaintainable, and inflexible. OO databases loose flexibility by combining logic and data. Key-value stores require the programmer to maintain all relationships. There, everybody sucks :-)
Neo4j's Key Characteristics
Neo4j vs Hadoop
This post makes an illuminating comparison between Neo4j vs Hadoop:
In principle, Hadoop and other Key-Value stores are mostly concerned with relatively flat data structures. That is, they are extremely fast and scalable regarding retrieval of simple objects, like values, documents or even objects.
However, if you want to do deeper traversal of e.g. a graph, you will have to retrieve the nodes for every traversal step (very fast) and then match them yourself in some manner (e.g. in Java or so) - slow.
Neo4j in contrast is build around the concept of "deep" data structures. This gives you almost unlimited flexibility regarding the layout of your data and domain object graph and very fast deep
traversals (hops over several nodes) since they are handled natively by the Neo4j engine down to the storage layer and not your client code. The drawback is that for huge data amounts (>1Billion nodes) the clustering and partitioning of the graph becomes non-trivial, which is one of the areas we are working on.
Then of course there are differences in the transaction models, consistency and others, but I hope this gives you a very short philosophical answer :)
It would have never occurred to me to compare the two, but the comparison shows why we need multiple complementary views of data. Hadoop scales the data grid and the compute grid and is more flexible in how data are queried and combined. Neo4j has far lower latencies for complex navigation problems. It's not a zero-sum game.
 Todd Hoff
Todd Hoff
Reader Comments (18)
Um yeah, there is a reason CODASYL didn't survive and RDBMSes did.
The relational model, and relational databases, are a superset of the graph, network and hierarchical models (and obviously of key value stores). Anything you can express with a graph or a hierarchy can be expressed relationally. An ad-hoc schema really indicates poor initial design, also schema updates are not hard nor do they lock whole tables in modern RDBMSes (also some RDBMSes such as PostgreSQL have a indexable hash type which would fit into a 'key-value' or 'schemaless' "design"). Joins are only expensive when you don't index on the joined fields, and nothing gets around the fact that traversal of graph nodes still requires file (or memory) access, which is not free in any system. As for recursive queries, the SQL standard has support for them, which hasn't, unfortunately, translated into their wide adoption (Oracle, MSSQL and the next release of PostgreSQL being the only major ones with that supoort AFAIR), but where it isn't available, UDFs and stored procedure fill the gap.
RDBMSes also have the flexibility to combine key-value stores, hierarchical data, graphs and traditional relational data into the same schema, an ability the other models lack, which is one of the reasons that the numerous attempts to replace the relational model have failed.
Your comment talks about "a REST layer up front." Does neo4j come with such a thing at the moment? I can't find one anywhere.
Hi Michael,
This actually just came up on the Neo4j user list. See:
http://www.mail-archive.com/user@lists.neo4j.org/msg01312.html
Does that answer your question?
--
Emil Eifrem
http://neo4j.org
http://twitter.com/emileifrem
As far as I remember there has been a neo4j post at dzone already (a few months ago)
Am I totally missing something? I've implement graphs in a relational db many times. The keys are small, the queries are fast, but the sql can be a biatch:
create table Node (
node_id numeric primary key,
label varchar(128) not null
)
create table Relationship (
rel_id numeric primary key,
from_id numeric not null,
to_id numeric not null
)
create table KeyValue (
keyvalue_id numeric primary key,
key varchar(64) not null,
value varchar(64) not null,
val_type varchar(16) not null,
);
create table Node_KeyValue (
node_id numeric not null,
keyvalue_id numeric not null
primary key (node_id, keyvalue_id)
)
create table Relationship_KeyValue (
rel_id numeric not null,
keyvalue_id numeric not null
primary key (rel_id, keyvalue_id)
)
I think thats the way that most people represent graphs too. I know that's certainly how I do it. And it works OK if you are only interested in 1st order relationships; is A friends with B? But as soon as you need to traverse multiple nodes (e.g., what is the shortest path between A and J), your queries are not only a pain to write but they can be really slow - even if you are well indexed. Even worse is if you want to compute some measures that require a larger view of node neighborhoods - such as centrality or whatnot.
In these cases the ugliness of the SQL is both a barrier to actually writing correct code but also a barrier for responsive execution. The simplest concepts can be very difficult for a seasoned SQL developer to express in SQL and difficult for the query planner to optimize. Even with optimal execution plans, the number of joins prohibits quick calculation.
I've yet to implement neo4j yet, but I have a few projects that I'm planning to switch over. And I'm looking forward to it.
Hi Mark
Traversal is the key, we're using Neo4j because it can do kick ass high speed traversals with (very) little effort (and we can build the graph at lightening speed). It fits extremely well with our processing model, whereas an RDBM wouldn't. I think there's a huge difference between 'conventional' business applications and those that have more demanding requirements.
With a conventional business application there is of course usually little sense in using a non-traditional method, i.e. the savings are outweighed by the retooling, relearning and operational concerns. But in high performance applications you have to use the tools that specifically fit your processing model, for example Hibernate is not suitable for batch processing and RDMS are not really suitable for graph processing (go on someone write a centricity algorithm in SQL and prove me wrong!!).
Another good reason to use Neo4j, potentially in conjunction with an RDMS, is the graph algorithms for doing graph based computation (like eccentricity, centrality, shortest paths etc.) which is pretty much out of the box with Neo4j. I certainly wouldn't exclude the possibility of using Neo4j in conjunction with an RDMS.
As always it's horses for courses, but if you spend a lot of time traversing graphs you want to seriously think about Neo4j as it is custom designed for this job and you don't need years of DBA experience and an Oracle database to kick buttox at graph traversal.
All the best
Neil
Also may be worth following: Bigdata Triplestore http://www.bigdata.com/blog/
Its an open source project with great scalability for deep data structures. Its still beta, but very promising
Does this support RDF/OWL with inferencing and or rule languages? If so how does it differ from Jena TDB, Sesame SAIL or Mulgara?
Check out our disease-drug relationship mapping application which builds an interactive graph of the relationships between drugs and diseases:
http://curehunter.com/public/dictionary.do
(for example, it finds a strong relationship between "obesity" and "exercise" therapy and "insulin")
There's a neo-rdf component on top of neo4j which makes it a triple store (or quad store). The implementation of that component doesn't support inferencing, but was built with such functionality in mind so adding it is a small amount of work. The interface was designed to resemble that of Sesame SAIL interface, but somewhat more clean.
It's AGPLv3 right? So only free to use in opensource projects? In all other uses (commercial or not, including as a backend for websites) you need a commercial license?
--andreas
Hi Andreas,
That's a correct description. If your software is open source, you can use Neo4j at no cost. In addition, our entry level commercial product "Neo Community Server" is free as in beer (i.e. $0) for use cases up to 1 million primitives. (A primitive in our lingo is either a node, or a relationship or a property.)
So if you want to use Neo4j in a proprietary setting or for whatever reason don't want to open up your source code and you have a dataset with less than 1 million primitives, you can contact us at http://neotechnology.com and get a commercial entry license for free.
Basically our thinking is something along these lines: if you write open source software, awesome, please use Neo4j at no cost. If you write proprietary software, you're not unlikely to be making money off of it and then we think it's fair to ask you to purchase a commercial license. It's not perfect but we believe it's a good approximation to fair and ethical as well as commercially viable.
--
Emil Eifrem
http://neo4j.org
http://twitter.com/emileifrem
Can you direct me (links) or explain to me how exactly graph is db applicable for tags and ratings?
i tested neo4j REST on my php app but it turn out much slower than mysql.
why so?
neo4j doesn't look cool as its advertising. Please write a demo performance in a huge graph ( 100M nodes , 10000M edges)
I'm a total noob to Neo4j but have some experience with a few NoSql solutions, like HBase and Cassandra and have some questions about the post:
1. You're saying that matching data on the client side in for example Java would be slow. Are you just talking about skipping multiple round trips to the server, since the matching should take as long on the server as on the client, no?
2. If that is the case could you solve the same problem by implementing a server side method, in for example HBase, that did something similar so you only would need one round trip?
3. For the billions of entries mentioned in the post, what kind of hardware are you guys using?
Thanks for a great post!
Interesting to see how it can be compared to hadoop.
We did spend a lot of time on neo4j for our recent project and realized that its really very stable and fast. However the only downside we observed is - it does NOT SCALE OUT.
The architecture of neo4j limits it to have Availability and Consistency therefore its not partition tolerant (per CAP theorem)
Though it can handle a large volume, it may happen that you may see performance degrade. There are ways to partially scale out using techniques like cache sharding , however they may not always scale linearly.
I think Neo4j and Hadoop can be used to compliment each other not as alternative. In a recent project we used hadoop to aggregate data and neo4j was used for realtime client response from those aggregates.