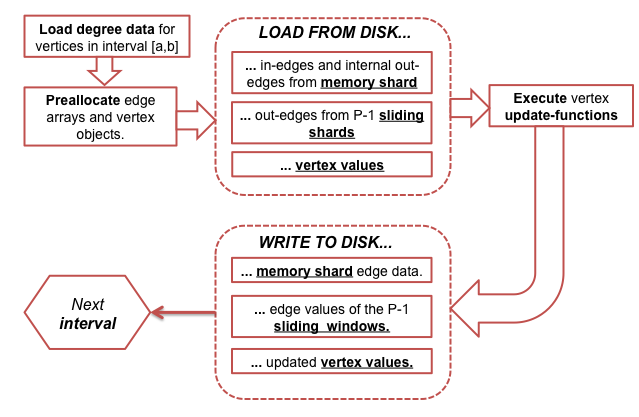
When all the Program's a Graph - Prismatic's Plumbing Library

At some point as a programmer you might have the insight/fear that all programming is just doing stuff to other stuff.
Then you may observe after coding the same stuff over again that stuff in a program often takes the form of interacting patterns of flows.
Then you may think hey, a program isn't only useful for coding datastructures, but a program is a kind of datastructure and that with a meta level jump you could program a program in terms of flows over data and flow over other flows.
That's the kind of stuff Prismatic is making available in the Graph extension to their plumbing package (code examples), which is described in an excellent post: Graph: Abstractions for Structured Computation.
You may remember Prismatic from previous profile we did on HighScalability: Prismatic Architecture - Using Machine Learning On Social Networks To Figure Out What You Should Read On The Web. We learned how Prismatic, an interest driven content suggestion service, builds programs in terms of graph stuff:
 HighScalability Team
HighScalability Team