













Redis Cloud Gets Easier with Fully Managed Hosting on Azure

ScaleGrid, a rapidly growing leader in the Database-as-a-Service (DBaaS) space, has just launched their new fully managed Redis on Azure service. This Redis management solution allows startups up to enterprise-level organizations automate their Redis operations on Microsoft Azure dedicated cloud servers, alongside their other open source database deployments, including MongoDB, MySQL and PostgreSQL.
Redis, the #1 key-value store and top 10 database in the world, has grown by over 300% in popularity over that past 5 years, per the DB-Engines knowledge base. The demand for Redis is skyrocketing across dozens of use cases, particularly for cache, queues, geospatial data, and high speed transactions. This simple database management system makes it very easy to store and retrieve pairs of keys and values, and is commonly paired with other database types to increase the speed and performance of an application. According to the 2019 Open Source Database Report, a majority of Redis deployments are used in conjunction with MySQL, and over half of Redis deployments are used with either PostgreSQL, MongoDB, and Elasticsearch.
ScaleGrid’s Redis hosting service allows these organizations to automate all of their time-consuming management tasks, such as backups, upgrades, scaling, replication, sharding, monitoring, alerts, log rotations, and OS patching, so their DBAs, developers, and DevOps teams can focus on new product development and optimizing performance. Additionally, organizations can customize their Redis persistence and host through their own Azure account which allows them to leverage advanced cloud capabilities like Azure Virtual Networks (VNET), Security Groups, and Reserved Instances to reduce long-term hosting costs up to 60%.
“Cloud reliability has never been so important,” says Dharshan Rangegowda, Founder and CEO of ScaleGrid. “It’s crucial for organizations to properly configure their Redis deployments for high availability and disaster recovery, as a couple minutes of downtime can be detrimental to a company’s security and reputation.”
ScaleGrid is the only Redis cloud service that allows you to customize your master-slave and cross-datacenter configurations for 100% uptime and availability across 30 different Azure regions. They also allow you to keep full Redis admin access and SSH access to your machines, and you can learn more about their advantages over competitors Compose for Redis, RedisGreen, Redis Labs and Elasticache for Redis on their Compare Redis Providers page.
 Backup, Caching, Database, DevOps, Geo-distributed Clusters, Microsoft, Redis, Redis Cluster, administrator, automation, cache, cloud, cluster, database replication, database scalability, deployment, high availability, key-value store, nosql, performance monitor, public cloud, sharding Tweet
Backup, Caching, Database, DevOps, Geo-distributed Clusters, Microsoft, Redis, Redis Cluster, administrator, automation, cache, cloud, cluster, database replication, database scalability, deployment, high availability, key-value store, nosql, performance monitor, public cloud, sharding Tweet 



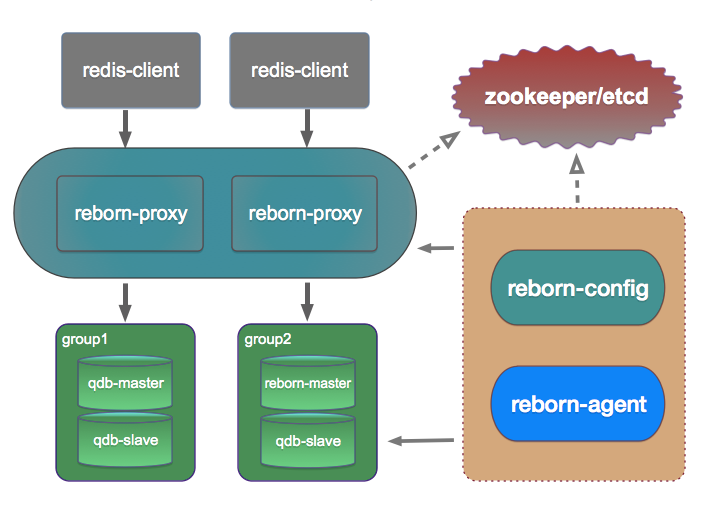 There are many key-value stores in the world and they are widely used in many systems. E.g, we can use a Memcached to store a MySQL query result for later same query, use MongoDB to store documents for better searching, etc.
There are many key-value stores in the world and they are widely used in many systems. E.g, we can use a Memcached to store a MySQL query result for later same query, use MongoDB to store documents for better searching, etc.
