













Top Redis Use Cases by Core Data Structure Types

Redis, short for Remote Dictionary Server, is a BSD-licensed, open-source in-memory key-value data structure store written in C language by Salvatore Sanfillipo and was first released on May 10, 2009. Depending on how it is configured, Redis can act like a database, a cache or a message broker. It’s important to note that Redis is a NoSQL database system. This implies that unlike SQL (Structured Query Language) driven database systems like MySQL, PostgreSQL, and Oracle, Redis does not store data in well-defined database schemas which constitute tables, rows, and columns. Instead, Redis stores data in data structures which makes it very flexible to use. In this blog, we outline the top Redis use cases by the different core data structure types.
Data Structures in Redis
 C, C++, Caching, Clustering, Database, DevOps, Redis, Redis Cluster, administrator, cache, data management, databases, in-memory, key-value store, open source, queue Tweet
C, C++, Caching, Clustering, Database, DevOps, Redis, Redis Cluster, administrator, cache, data management, databases, in-memory, key-value store, open source, queue Tweet 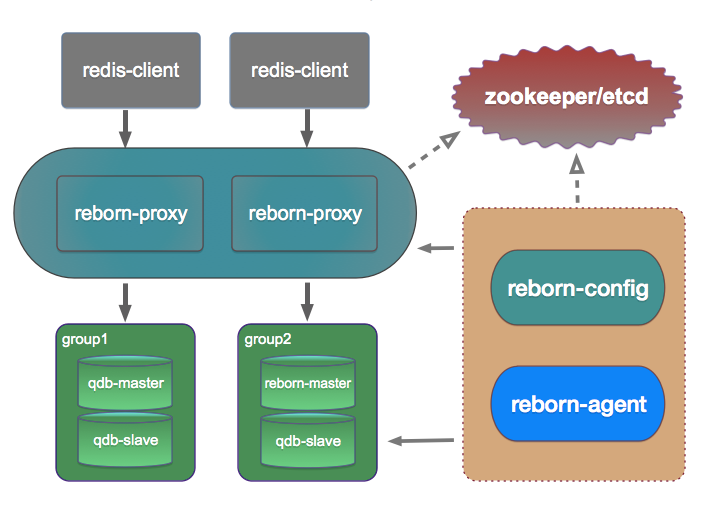 There are many key-value stores in the world and they are widely used in many systems. E.g, we can use a Memcached to store a MySQL query result for later same query, use MongoDB to store documents for better searching, etc.
There are many key-value stores in the world and they are widely used in many systems. E.g, we can use a Memcached to store a MySQL query result for later same query, use MongoDB to store documents for better searching, etc.


