













Hypertable Routs HBase in Performance Test -- HBase Overwhelmed by Garbage Collection
![]()
This is a guest post by Doug Judd, original creator of Hypertable and the CEO of Hypertable, Inc.
Hypertable delivers 2X better throughput in most tests -- HBase fails 41 and 167 billion record insert tests, overwhelmed by garbage collection -- Both systems deliver similar results for random read uniform test
We recently conducted a test comparing the performance of Hypertable (@hypertable) version 0.9.5.5 to that of HBase (@HBase) version 0.90.4 (CDH3u2) running Zookeeper 3.3.4. In this post, we summarize the results and offer explanations for the discrepancies. For the full test report, see Hypertable vs. HBase II.
Introduction
Hypertable and HBase are both open source, scalable databases modeled after Google's proprietary Bigtable database. The primary difference between the two systems is that Hypertable is written in C++, while HBase is written in Java. We modeled this test after the one described in section 7 of the Bigtable paper and tuned both systems for maximum performance. The test was run on a total of sixteen machines connected together with gigabit Ethernet. The machines had the following configuration:
OS: CentOS 6.1 CPU: 2X AMD C32 Six Core Model 4170 HE 2.1Ghz RAM: 24GB 1333 MHz DDR3 disk: 4X 2TB SATA Western Digital RE4-GP WD2002FYPS
The HDFS NameNode and Hypertable and HBase master was run on test01. The DataNodes were run on test04..test15 and the RangeServer and RegionServers were run on the same set of machines and were configured to use all available RAM. Three Zookeeper and Hyperspace replicas were run on test01..test03. The tables used in the test were configured to use Snappy compression (using native Snappy libraries for HBase) and Bloom filters loaded with row keys. We made every effort to tune HBase for maximum performance and details of the configuration we settled on can be found in the full test report Hypertable vs. HBase II. Instructions on how to setup and run this test can be found in Test Setup. The Java client API was used for both systems.
Random Write
In this test we wrote 5TB of data into both Hypertable and HBase in four different runs, using value sizes 10000, 1000, 100, and 10. The key was fixed at 20 bytes and was formatted as a zero-padded, random integer in the range [0..number_of_keys_submitted*10). The data for the value was a random snippet taken from a 200MB sample of the english Wikipedia XML pages. The following chart summarizes the results:
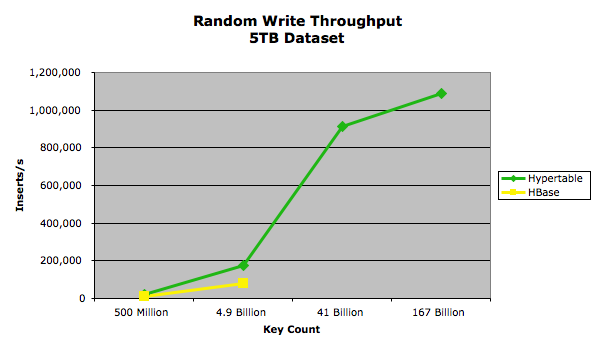 The exact performance measurements are provided in the following table.
The exact performance measurements are provided in the following table.
| Value Size | Key Count | Hypertable Throughput MB/s |
HBase Throughput MB/s |
| 10,000 | 500,041,347 | 188 | 93.5 |
| 1,000 | 4,912,173,058 | 183 | 84 |
| 100 | 41,753,471,955 | 113 | |
| 10 | 167,013,888,782 | 34 |
The lack of data points for the HBase 41 billion and 167 billion key tests are due to the HBase RegionServers throwing Concurrent mode failure exceptions. This failure occurs, regardless of the configuration, when the RegionServer generates garbage at a rate that overwhelms the Java garbage collector (see Avoiding Full GCs in HBase with MemStore-Local Allocation Buffers for more details on this error). We believe that while it is possible to construct a garbage collection scheme to overcome these problems, it would come at a heavy cost in runtime performance. The paper Quantifying the Performance of Garbage Collection vs. Explicit Memory Management, by Matthew Hertz and Emery D. Berger, presented at OOPSLA 2005, provides research that supports this belief.
Random Read
In this test we measured the query throughput for a set of random read requests. Two tests were run on each system, one following a Zipfian distribution (modeling realistic workload) and another that followed a uniform distribution. Each inserted key/value pair had a fixed key size of 20 bytes and a fixed value size of 1KB. We ran two tests on each system, one in which we loaded the database with 5TB and another in which we loaded 0.5TB. This allowed us to measure the performance of each system under both high and low RAM-to-disk ratios. In the 5TB test, 4,901,960,784 key/value pairs were loaded and in the 0.5TB test 490,196,078 keys were loaded. The keys were ASCII integers in the range [0..total_keys) so that every query resulted in a match, returning exactly one key/value pair. Each test client machine ran 128 test client processes for a total of 512, and each test client issued queries in series so there was a maximum of 512 queries outstanding at any given time. A total of 100 million queries were issued for each test.
Zipfian
In this test, the set of keys queried followed a Zipfian distribution. We used an exponent value of 0.8, which means that 20% of the keys appeared 80% of the time. In this test, we configured Hypertable with a 2GB query cache. For the HBase test, we kept the block cache and memstore limits at their default values because that appeared to yield the best results. The results of this test are summarized in the following chart.
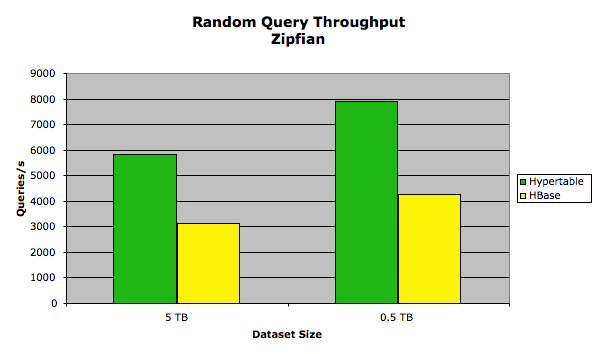 The exact performance measurements are provided in the following table.
The exact performance measurements are provided in the following table.
| Dataset size | Hypertable Queries/s |
HBase Queries/s |
Hypertable Latency (ms) |
HBase Latency (ms) |
| 0.5 TB | 7901.02 | 4254.81 | 64.764 | 120.299 |
| 5 TB | 5842.37 | 3113.95 | 87.532 | 164.366 |
The performance discrepancy is due to the benefit provided to Hypertable by its query cache, a subsystem that is not present in HBase. HBase could implement a query cache, but it is a subsystem that generates a lot of garbage (in the write path), so we believe that while it may improve performance for some HBase workloads, it will have a detrimental impact on others, especially write-heavy and mixed workloads with large cell counts. One interesting thing to note is that when we increased the size of the block cache in both systems, it had a detrimental effect on performance. We believe that this is due to the fact that the systems had plenty of spare CPU capacity to keep up with the decompression demand. By eliminating the block cache, which stores uncompressed blocks, and relying on the operating system file cache, which stores compressed blocks, better performance was achieved because more of the data set could fit in memory.
Uniform
In this test, the set of keys queried followed a uniform distribution. The following chart summarizes the results:
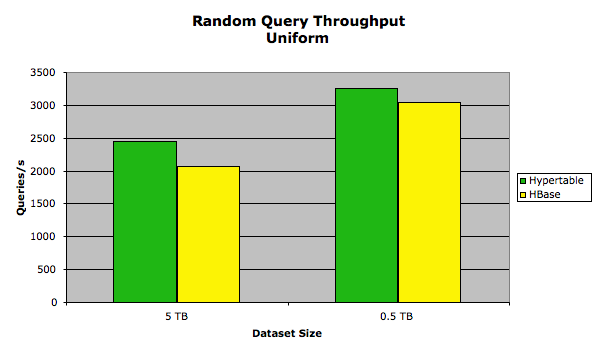 The exact performance measurements are provided in the following table.
The exact performance measurements are provided in the following table.
| Dataset size | Hypertable Queries/s |
HBase Queries/s |
Hypertable Latency (ms) |
HBase Latency (ms) |
| 0.5 TB | 3256.42 | 2969.52 | 157.221 | 172.351 |
| 5 TB | 2450.01 | 2066.52 | 208.972 | 247.680 |
In this test, the HBase performance was close to that of Hypertable. We attribute this to the bottleneck being disk I/O and the minimal amount of garbage generated during the test.
Conclusion
The Hypertable community has been working hard over the past five years to build Hypertable into the winning high performance, scalable database solution for big data applications. We're excited by these results and continue to propel the project forward with new features and performance improvements. Hypertable is 100% open source software and we encourage you to join us and become a member of our community by clicking on the "Community" tab of the Hypertable website, www.hypertable.com.
 Doug Judd
Doug Judd
Reader Comments (16)
I understand writing the GUI/client/middleware of a datastore in Java, but when it comes to performing optimised datastore lookups or tabulations or aggregations (i.e. core datastore functionality), it seems insanity to write them in Java. Garbage Collection and GC pauses are known bottlenecks and danger points and really don't belong in Datastores, they are Java's achilles heel, and they are most dangerous in applications like datastores, that are supposed to be not only rock solid but highly predictable in terms of performance.
I am not surprised that Hypertable stands up long after HBase does, based on the simple fact that Hypertable is in C++ and HBase in Java. Are there any exceptions to this rule? Is there any datastore written in Java, that would not benefit (performance wise) from a rewrite in C++?
I wouldn't conclude that you can't implement a performant predictable database in Java. If you make sure virtually nothing leaves eden you will get by just fine.
Pop in JNA and start doing your own memory management with ByteBuffers for long lived objects with variable lifetimes. You would end up doing the same thing in native code anyways in order to avoid heap fragmentation and to return unused pages to the OS.
I don't consider partially giving up GC as a reason to stop using Java. It is a shame that the Oracle/Sun JVM and Java have failed to treat native memory as a first class citizen while simultaneously failing to deliver on performant GC for many classes of application. It seems like C# has done a better job in that respect.
It would be interesting to see the test attempted with the G1 or Azul collector.
The version of HBase that we used in this test does its own memory management for Memstore object allocation with something called MemStore-Local Allocation Buffers (mslab). Hypertable uses an arena allocator for the same purpose. The reason that this works is that objects allocated in the Memstore (CellCache) are grouped together by Region (Range) and all the objects in each group get deallocated at the same time. So the numbers presented here do reflect the optimization that you refer to.
For the query cache, the arena or mslab-style solution would not work because there is no natural grouping of objects, so there is no way to merge smaller allocations into larger allocation blocks that can be managed more easily by the garbage collector. The query cache hit rate stabilized around 65% during the random read Zipfian test which gives you an idea of how important the query cache can be for real world access patterns.
No, it's not enabled by default in 0.90.x so it needs to be if you want to use it (I don't see that in your listed configurations)...
But that's minor compared to some other oversights. For example if the regions are set to split at 2GB but the memstores still flush at 64MB, you end up having to re-compact a lot of data in order to finally grow up to the split size. I bet the test starts really slowly.
Another oversight is that the test doesn't pre-split the table so all the clients will hammer the same region server in the beginning until it re-compacted enough to get up to 2GB. I don't know enough about how Hypertable manages this, but this is the first thing we recommend for HBase 2.8. The Important Configurations (see 2.8.2.7 in particular). This would also make the test better since until all the regions are distributed you're not benchmarking the whole cluster.
A third thing that probably affected memory usage in a bad way in this test is that 0.90.x doesn't put the store file indexes and bloom filters in the block cache (like it does in 0.92), it just keeps them all in memory, so with a max global memstore size of 80% you're running out of heap pretty quickly. I'm surprised it doesn't OOME more often than it spins just trying to GC data it cannot get rid of. The fat payloads coming from the clients (up to 50 handlers plus the IPC queue) doesn't help either. So a smaller memstore global size would actually be better.
If the authors did indeed get help from committers on the mailing list like it seems to claim ("Direct assistance from HBase committers on the HBase mailing list"), they would have been told that they're way off.
In the other hand this comparison is interesting for me, I didn't know Hypertable tweaks for write-heavy and read-heavy workloads automatically and that's something we could add in HBase to make it easier to configure. It also gives me a new benchmark to use with YCSB.
Doug, HBase has block cache which is more "short scan optimized" than a pure row-key cache. So it is not fare to measure only random look up operations. you have to add both long and short scans as well. But I agree with: HBase is typical garbage- soft: too much hype, too little value.
Doug,
ByteBuffers allow you to wrap native memory that the garbage collector is not aware of. Any on-heap representation has an equivalent off-heap representation using ByteBuffers.
I don't understand why a query cache can have an workable implementation in native memory but not when represented as a wrapper around native memory. ehcache is an example of a Java cache that uses off heap storage (http://www.terracotta.org/downloads/bigmemory).
Simple segregated storage is an alternative to SLAB allocation that doesn't suffer from fragmentation and can handle random de-allocation with minimal extra space usage.
I am not saying that it is the best solution (JNI is), but for pure Java projects it is a work around until readily available GC technology catches up.
In the 1st graph it's showing that Hypertable is performing 1.1M inserts/s at 167 billion key counts.
But the table right below it is showing only 34 inserts/s
There's a huge difference between the 2 numbers. Which one is correct?
Jean-Daniel -
Thanks for the reply. I just took a look at the HBase source code for CDH3u2 and you are correct, mslab is disabled by default. I think what threw me off is that the Apache HBase book is published for a version of HBase that hasn't yet been released. I will re-run these tests with
hbase.hregion.memstore.mslab.enabledset to true and publish the results as an addendum.Your second two points, I do not agree impacted the test much. While HBase was slow to start up in the load tests, the performance stabilized after 10% and the first 10% was maybe 50% slower than the rest. So while it did affect the performance slightly, the impact was nominal. As far as pre-splitting goes, that doesn't make sense to me. How do you know what your data set looks like a-priori so that you can choose a reasonable set of split points? The way Hypertable handles this is by assigning the first range in a table a soft split limit which is a small fraction of the configured hard split limit and the soft limit controls when the Range will split. Each time the range splits, this soft limit is doubled until the soft split limit hits the configured hard split limit.
At the time we started the test, Cloudera's CDH3 seemed like the best, most stable choice. HBase 0.92 was released three months into the test, so we couldn't feasibly start over.
We would be very happy to do a Hypertable vs. HBase performance test in which each side is given the opportunity to tune their system optimally. Would you be willing to join me in such a test and manage HBase tuning?
My reaction after reading the post: Boy, Doug Judd sure hates garbage collection. ;)
I'm wondering why he compares HyperTable to HBASE, instead of, perhaps, Cassandra?
I've got quite a few years of Java behind me, and one thing I've learned is that large heaps rarely solve problems. Cassandra documentation notes that it's a very good idea to let the operating system have most of the memory, in most cases -- it'll do a good job of figuring out what the keep and what to cache. "give it more memory so it will be faster" does NOT always hold true in Java, and doesn't hold true for a C program either.
There are a few architectural issues here; HBASE's Key class holds byte arrays. That's probably not an optimal structure to use at scale. ByteBuffers aren't just for direct memory. If you want to simulate TLAB, create a big ByteBuffer wrapping a byte[]. Then parcel out chunks of it to hold key-value-information; track each key by offset and length, and hold at least one reference to the large ByteBuffer while you still need it. This is the same kind of thing you'd do under C. Heap fragmentation is not a "feature" of Java programs; it's a result of a set of architectural decisions operating against a given load.
Effective and Efficient Entity Search in RDF Data describes the indexing of over a billion quads of RDF, for complex searching, within the mg4j framework (which is brilliant, by the way). I've worked with the libraries this group (and Sebastiano Vigna in particular) produces, and if you look at the architectural decisions being made, you can see that they are very careful about managing the amounts of miscellaneous heap memory being allocated during heavy processing.
Log-structured-files (like bigtable and hypertable) are based on a push-down of information from memory into immutable table form, followed by a series of scheduled merges to keep the immutable "tablets" reasonably up to date.
With Vigna's utilities on my simple workstation I can index over 800,000 de-duplicated search terms per second, on a single-threaded basis, into an immutable map. A tiny in-memory index is used to achieve single-cluster read for a query. Compression is about 40 to 1, and the in-memory portion occupies perhaps 0.2% of the original data. It's worth noting that during the construction of a 10,000,000 term index memory heap size never rises above 20MB.
In any case, I would recommend studying Sebastiano Vigna's software. You'll learn a lot,and there are some really well-engineered components there.
Andy - The heading on the table was wrong, it is MB/s. I just corrected it.
One other advantage Java has over C++ in such applications is its well-defined memory model. It allows for fine control over memory fences (with volatiles, and in Java 8 even finer control with the Fences API) and has a good CAS API. All in all, it has great low-level concurrency primitives. Achieving this with C/C++ would require targeting specific compilers and hardware architectures.
The inattention to proper HBase configuration (MSLAB and flush sizes) renders these results meaningless.
See Addendum to Hypertable vs. HBase Performance Test which shows the results of the Random Write test with an additional third HBase test with
hbase.hregion.memstore.mslab.enabledset to true. Synopsis: Enabling mslab slowed performance on the 10KB and 1KB tests and the 100 byte and 10 byte tests still failed with Concurrent mode failureSee Addendum to Hypertable vs. HBase Performance Test which shows the results of the Random Write test with an additional third HBase test with
hbase.hregion.memstore.mslab.enabledset to true. Synopsis: Enabling mslab slowed performance on the 10KB and 1KB tests and the 100 byte and 10 byte tests still failed with Concurrent mode failurethe future of Hypertable may not only lie in its alleged performance over HBase, but also in an robust ecosystem. maybe including Hypertable in CDH clould help vault Hypertable into the Hadoop Stack ecosystem and boost its popularity.
Any further responses from Hbase community on this? Can't HBase run the same performance tests as Hypertable to clarify?