ESPN's Architecture at Scale - Operating at 100,000 Duh Nuh Nuhs Per Second

ESPN went on air in 1978. In those 30+ years think of the wonders we’ve seen! When I think of ESPN I think of a world wide brand that is the very definition of prime time. And it shows in their stats. ESPN.com peaks at 100,000 requests per second. Their peak event is, not surprisingly, the World Cup. But would you be surprised to learn ESPN is powered by only a few hundred servers and a couple of dozen engineers? I was.
And would you be surprised to learn ESPN is undergoing a fundamental transition from an Enterprise architecture to one capable of handling web scale loads driven by increasing mobile usage, personalization, and a service orientation? Again, thinking ESPN was just about watching sports on TV, I was surprised. ESPN is becoming much more than that. ESPN is becoming a sports platform.
How does ESPN handle all of this complexity, responsibility, change, and load? Unlike most every other profile on HighScalability. The fascinating story of ESPN’s architecture is told by Manny Pelarinos, Senior Director, Engineering at ESPN in the InfoQ presentation Architecture at Scale at ESPN. Information from Max Protect: Scalability and Caching at ESPN.com has also been folded in.
Starting in a pre-personal computer era ESPN developed an innovative cable and satellite TV sports empire. From an initial 30 minute program reviewing the day’s sports, they went on to make deals with the NBA, USFL, NHL, and what would become the big fish of all sports in the US, the National Football League.
Sport by sport deals were made to bring sports data in from all possible sources so ESPN could report scores, play film clips, and generally become one stop shopping for all things sports on TV and later the web.
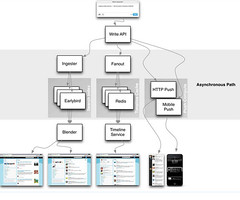
It’s a complex system to understand. They have a lot going on with Television & Broadcasting, live scoring, editing and publishing, Digital Media, giving sports scores, web and mobile, personalization, fantasy games, and they also want to expand API access to 3rd party developers. Unlike most every profile on HighScalability ESPN has an enterprise heritage. It’s a Java Enterprise stack, so you’ll see Oracle databases, JMS brokers, Java Beans, and Hibernate.
Some of the most important lessons we’ll learn about:
-
Platform changes everything. ESPN sees themselves as a content provider. These days content is accessed through multiple paths. It can be on TV, or on ESPN.com, or on mobile, but content is also being consumed by more and more internal applications, like Fantasy Games. And they also want to provide an external API so developers can build on ESPN resources. ESPN wants to become a walled garden built on a sports content platform that centralizes access to their prime advantage over everyone else, which is unprecedented access to sports related content and data. The walled garden approach that Facebook has made work for social, Apple has made work for apps, and Google has made work for AI, is what ESPN wants to do for sports. The problem is transitioning from an enterprise architecture to a platform based on APIs and services is a tough change to make. They can do it. They are doing it. But it will be hard.
-
Web scale changes everything. Many web properties today use Java as their standard backend development environment, but ESPN.com, which grew up in the Java Enterprise era, went all in for the canonical Enterprise architecture. And it has worked quite well. Until there was a sort of phase transition from enterprise class loads experienced by a relatively predictable ESPN.com to a world dominated by high mobile traffic, mass customization, and platform concerns. Many of the architecture choices we see in native web properties must now be used by ESPN.com.
-
Personalization changes everything. The cache that once saved your database is now much less useful when all content becomes dynamically constructed for each user and must follow you on every mode of access (.com, mobile, TV).
-
Mobile changes everything. It puts pressure everywhere on your architecture. When there was just the web architecture didn’t matter as much because there were fewer users and fewer servers. In the mobile age with so many more users and servers these kind of architecture decisions make a huge difference.
-
Partnerships are power. ESPN can create a walled garden because over the years they have developed partnerships that gives them special access to data that nobody else has. It’s good to be firstest with the mostest. That individual sports like the NFL and MLB seeking to capture this value with their own network lessens this advantage somewhat, but the forces are such that everyone needs to get along, which puts ESPN in the middle of a powerful platform play, if they can execute.
Lights. Camera. Action. Let’s learn how ESPN scales...
 HighScalability Team
HighScalability Team