
Pinterest has been riding an exponential growth curve, doubling every month and half. They’ve gone from 0 to 10s of billions of page views a month in two years, from 2 founders and one engineer to over 40 engineers, from one little MySQL server to 180 Web Engines, 240 API Engines, 88 MySQL DBs (cc2.8xlarge) + 1 slave each, 110 Redis Instances, and 200 Memcache Instances.
Stunning growth. So what’s Pinterest's story? To tell their story we have our bards, Pinterest’s Yashwanth Nelapati and Marty Weiner, who tell the dramatic story of Pinterest’s architecture evolution in a talk titled Scaling Pinterest. This is the talk they would have liked to hear a year and half ago when they were scaling fast and there were a lot of options to choose from. And they made a lot of incorrect choices.
This is a great talk. It’s full of amazing details. It’s also very practical, down to earth, and it contains strategies adoptable by nearly anyone. Highly recommended.
Two of my favorite lessons from the talk:
- Architecture is doing the right thing when growth can be handled by adding more of the same stuff. You want to be able to scale by throwing money at a problem which means throwing more boxes at a problem as you need them. If you are architecture can do that, then you’re golden.
- When you push something to the limit all technologies fail in their own special way. This lead them to evaluate tool choices with a preference for tools that are: mature; really good and simple; well known and liked; well supported; consistently good performers; failure free as possible; free. Using these criteria they selected: MySQL, Solr, Memcache, and Redis. Cassandra and Mongo were dropped.
These two lessons are interrelated. Tools following the principles in (2) can scale by adding more boxes. And as load increases mature products should have fewer problems. When you do hit problems you’ll at least have a community to help fix them. It’s when your tools are too tricky and too finicky that you hit walls so high you can’t climb over.
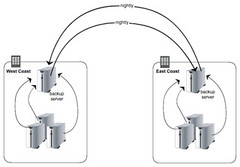
It’s in what I think is the best part of the entire talk, the discussion of why sharding is better than clustering, that you see the themes of growing by adding resources, few failure modes, mature, simple, and good support, come into full fruition. Notice all the tools they chose grow by adding shards, not through clustering. The discussion of why they prefer sharding and how they shard is truly interesting and will probably cover ground you’ve never considered before.
Now, let’s see how Pinterest scales:
Click to read more ...















 HighScalability Team
HighScalability Team In
In 

 This is an interview with
This is an interview with 
 This is a guest post by
This is a guest post by 
