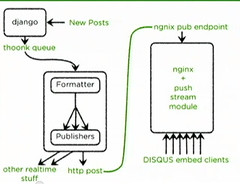
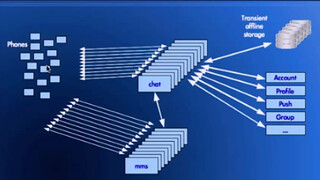
The folks at Stack Overflow remain incredibly open about what they are doing and why. So it’s time for another update. What has Stack Overflow been up to?
The network of sites that make up StackExchange, which includes StackOverflow, is now ranked 54th for traffic in the world; they have 110 sites and are growing at a rate of 3 or 4 a month; 4 million users; 40 million answers; and 560 million pageviews a month.
This is with just 25 servers. For everything. That’s high availability, load balancing, caching, databases, searching, and utility functions. All with a relative handful of employees. Now that’s quality engineering.
This update is based on The architecture of StackOverflow (video) by Marco Cecconi and What it takes to run Stack Overflow (post) by Nick Craver. In addition, I’ve merged in comments from various sources. No doubt some of the details are out of date as I meant to write this article long ago, but it should still be representative.
Stack Overflow still uses Microsoft products. Microsoft infrastructure works and is cheap enough, so there’s no compelling reason to change. Yet SO is pragmatic. They use Linux where it makes sense. There’s no purity push to make everything Linux or keep everything Microsoft. That wouldn’t be efficient.
Stack Overflow still uses a scale-up strategy. No clouds in site. With their SQL Servers loaded with 384 GB of RAM and 2TB of SSD, AWS would cost a fortune. The cloud would also slow them down, making it harder to optimize and troubleshoot system issues. Plus, SO doesn’t need a horizontal scaling strategy. Large peak loads, where scaling out makes sense, hasn’t been a problem because they’ve been quite successful at sizing their system correctly.
So it appears Jeff Atwood’s quote: "Hardware is Cheap, Programmers are Expensive", still seems to be living lore at the company.
Marco Ceccon in his talk says when talking about architecture you need to answer this question first: what kind of problem is being solved?
First the easy part. What does StackExchange do? It takes topics, creates communities around them, and creates awesome question and answer sites.
The second part relates to scale. As we’ll see next StackExchange is growing quite fast and handles a lot of traffic. How does it do that? Let’s take a look and see….
Stats
Click to read more ...















 HighScalability Team
HighScalability Team