The end of Moore’s law is the best thing that’s happened to computing in the last 50 years. Moore’s law has been a tyranny of comfort. You were assured your chips would see a constant improvement. Everyone knew what was coming and when it was coming. The entire semiconductor industry was held captive to delivering on Moore’s law. There was no new invention allowed in the entire process. Just plod along on the treadmill and do what was expected. We are finally breaking free of these shackles and entering what is the most exciting age of computing that we’ve seen since the late 1940s. Finally we are in a stage where people can invent and those new things will be tried out and worked on and find their way into the market. We’re finally going to do things differently and smarter.
-- Stanley Williams (paraphrased)
HP has been working on a radically new type of computer, enigmatically called The Machine (not this machine). The Machine is perhaps the largest R&D project in the history of HP. It’s a complete rebuild of both hardware and software from the ground up. A massive effort. HP hopes to have a small version of their datacenter scale product up and running in two years.
The story began when we first met HP’s Stanley Williams about four years ago in How Will Memristors Change Everything? In the latest chapter of the memristor story, Mr. Williams gives another incredible talk: The Machine: The HP Memristor Solution for Computing Big Data, revealing more about how The Machine works.
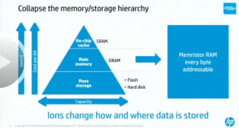
The goal of The Machine is to collapse the memory/storage hierarchy. Computation today is energy inefficient. Eighty percent of the energy and vast amounts of time are spent moving bits between hard disks, memory, processors, and multiple layers of cache. Customers end up spending more money on power bills than on the machines themselves. So the machine has no hard disks, DRAM, or flash. Data is held in power efficient memristors, an ion based nonvolatile memory, and data is moved over a photonic network, another very power efficient technology. When a bit of information leaves a core it leaves as a pulse of light.
On graph processing benchmarks The Machine reportedly performs 2-3 orders of magnitude better based on energy efficiency and one order of magnitude better based on time. There are no details on these benchmarks, but that’s the gist of it.
The Machine puts data first. The concept is to build a system around nonvolatile memory with processors sprinkled liberally throughout the memory. When you want to run a program you send the program to a processor near the memory, do the computation locally, and send the results back. Computation uses a wide range of heterogeneous multicore processors. By only transmitting the bits required for the program and the results the savings is enormous when compared to moving terabytes or petabytes of data around.
The Machine is not targeted at standard HPC workloads. It’s not a LINPACK buster. The problem HP is trying to solve for their customers is where a customer wants to perform a query and figure out the answer by searching through a gigantic pile of data. Problems that need to store lots of data and analyze in realtime as new data comes in
Why is a very different architecture needed for building a computer? Computer systems can’t not keep up with the flood of data that’s coming in. HP is hearing from their customers that they need the ability to handle ever greater amounts of data. The amount of bits that are being collected is growing exponentially faster than the rate at which transistors are being manufactured. It’s also the case that information collection is growing faster than the rate at which hard disks are being manufactured. HP estimates there are 250 trillion DVDs worth of data that people really want to do something with. Vast amount of data are being collected in the world are never even being looked at.
So something new is needed. That’s at least the bet HP is making. While it’s easy to get excited about the technology HP is developing, it won’t be for you and me, at least until the end of the decade. These will not be commercial products for quite a while. HP intends to use them for their own enterprise products, internally consuming everything that’s made. The idea is we are still very early in the tech cycle, so high cost systems are built first, then as volumes grow and processes improve, the technology will be ready for commercial deployment. Eventually costs will come down enough that smaller form factors can be sold.
What is interesting is HP is essentially building its own cloud infrastructure, but instead of leveraging commodity hardware and software, they are building their own best of breed custom hardware and software. A cloud typically makes available vast pools of memory, disk, and CPU, organized around instance types which are connected by fast networks. Recently there’s a move to treat these resource pools as independent of the underlying instances. So we are seeing high level scheduling software like Kubernetes and Mesos becoming bigger forces in the industry. HP has to build all this software themselves, solving many of the same problems, along with the opportunities provided by specialized chips. You can imagine programmers programming very specialized applications to eke out every ounce of performance from The Machine, but what is more likely is HP will have to create a very sophisticated scheduling system to optimize how programs run on top of The Machine. What's next in software is the evolution of a kind of Holographic Application Architecture, where function is fluid in both time and space, and identity arises at run-time from a two-dimensional structure. Schedule optimization is the next frontier being explored on the cloud.
The talk is organized in two broad sections: hardware and software. Two-thirds of the project is software, but Mr. Williams is a hardware guy, so hardware makes up the majority of the talk. The hardware section is based around the idea of optimizing the various functions around the physics that is available: electrons compute; ions store; photons communicate.
Here’s is my gloss on Mr. Williams talk. As usual with such a complex subject much can be missed. Also, Mr. Williams tosses huge interesting ideas around like pancakes, so viewing the talk is highly recommended. But until then, let’s see The Machine HP thinks will be the future of computing….
Click to read more ...















 HighScalability Team
HighScalability Team