How Facebook's Safety Check Works
I noticed on Facebook during this horrible tragedy in Paris that there was some worry because not everyone had checked in using Safety Check (video). So I thought people might want to know a little more about how Safety Check works.
If a friend or family member hasn't checked-in yet it doesn't mean anything bad has happened to them. Please keep that in mind. Safety Check is a good system, but not a perfect system, so keep your hopes up.
This is a really short version, there's a longer article if you are interested.
When is Safety Check Triggered?
-
Before the Paris attack Safety Check was only activated for natural disasters. Paris was the first time it was activated for human disasters and they will be doing it more in the future. As a sign of this policy change, Safety Check has been activated for the recent bombing in Nigeria.
How Does Safety Check Work?
-
If you are in an area impacted by a disaster Facebook will send you a push notification asking if you are OK.
-
Tapping the “I’m Safe” button marks that your are safe.
-
All your friends are notified that you are safe.
-
Friends can also see a list of all the people impacted by the disaster and how they are doing.
How is the impacted area selected?
-
Since Facebook only has city-level location for most users, declaring the area isn't as hard as drawing on a map. Facebook usually selects a number of cities, regions, states, or countries that are affected by the crisis.
-
Facebook always allows people to declare themselves into the crisis (or out) in case the geolocation prediction is inaccurate. This means Facebook can be a bit more selective with the geographic area, since they want a pretty high signal with the notifications. Notification click-through and conversion rates are used as downstream signals on how well a launch went.
-
For something like Paris, Facebook selected the whole city and launched. Especially with the media reporting "Paris terror attacks," this seemed like a good fit.
How do you build the pool of people impacted by a disaster in a certain area?
-
Building a geoindex is the obvious solution, but it has weaknesses.
-
People are constantly moving so the index will be stale.
-
A geoindex of 1.5 billion people is huge and would take a lot of resources they didn’t have. Remember, this is a small team without a lot of resources trying to implement a solution.
-
Instead of keeping a data pipeline that’s rarely used active all of the time, the solution should work only when there is an incident. This requires being able to make a query that is dynamic and instant.
-
Facebook does not have GPS-level location information for the majority of its user base (only those that turn on the nearby friends feature), so they use the same IP2Geo prediction algorithms that Google and other web companies use -- essentially determining city level location based on IP address.
The solution leveraged the shape of the social graph and its properties:
-
When there’s a disaster, say an earthquake in Nepal, a hook for Safety Check is turned on in every single news feed load.
-
When people check their news feed the hook executes. If the person checking their news feed is not in Nepal then nothing happens.
-
When someone in Nepal checks their news feed is when the magic happens.
-
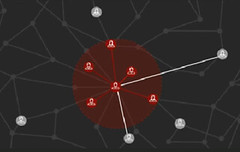
Safety Check fans out to all their friends on their social graph. If a friend is in the same area then a push notification is sent asking if they are OK.
-
The process keeps repeating recursively. For every friend found in the disaster area a job is spawned to check their friends. Notifications are sent as needed.
In Practice this Solution Was Very Effective
-
At the end of the day it's really just DFS (Depth First Search) with seen state and selective exploration.
-
The product experience feels live and instant because the algorithm is so fast at finding people. Everyone in the same room, for example, will appear to get their notifications at the same time. Why?
-
Using the news feed gives a random sampling of users that is biased towards the most active users with the most friends. And it filters out inactive users, which is billions of rows of computation which need not be performed.
-
The graph is dense and interconnected. Six Degrees of Kevin Bacon is wrong, at least on Facebook. The average distance between any two of Facebook’s 1.5 billion users is 4.74 edges. Sorry Kevin. With 1.5 billion users the whole graph can be explored within 5 hops. Most people can be efficiently reached by following the social graph.
-
There’s a lot of parallelism for free using a social graph approach. Friends can be assigned to different machines and processed in parallel. As can their friends, and so on.
-
Isn't it possible to use something like Hadoop/Hive/Presto to simply get a list of all users in Paris on demand? Hive and Hadoop are offline. It can take ~45 minutes to execute a query on Facebook's entire user table (even longer if it involves joins) and certain times of the day its slower (during work hours usually). Not only that, but once the query executes some engineer has to go copy and paste into a script that would likely run on one machine. Doing this in a distributed async job fashion allowed for a lot more flexibility. Even better, it's possible to change the geographic area as the algorithm runs and those changes are reflected immediately.
-
The cost of searching for the users in the area directly correlates with the size of the crisis (geographically). A smaller crises ends up being fairly cheap, whereas larger crises end up checking on a larger and larger portion of the userbase until 100% of the user base is reached. For Nepal, a big disaster, ~1B profiles were checked. For some smaller launches only ~100k profiles were checked. Had an index been used, or an offline job that did joins and filters, the cost would be constant, no matter how small the crisis.
 HighScalability Team
HighScalability Team