A Journey Through How Zapier Automates Billions of Workflow Automation Tasks
This is a guest repost by Bryan Helmig, Co-founder & CTO at Zapier, who makes it easy to automate tasks between web apps.

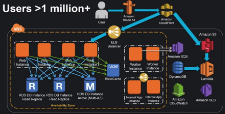
Zapier is a web service that automates data flow between over 500 web apps, including MailChimp, Salesforce, GitHub, Trello and many more.
Imagine building a workflow (or a "Zap" as we call it) that triggers when a user fills out your Typeform form, then automatically creates an event on your Google Calendar, sends a Slack notification and finishes up by adding a row to a Google Sheets spreadsheet. That's Zapier. Building Zaps like this is very easy, even for non-technical users, and is infinitely customizable.
As CTO and co-founder, I built much of the original core system, and today lead the engineering team. I'd like to take you on a journey through our stack, how we built it and how we're still improving it today!
The Teams Behind the Curtains
It takes a lot to make Zapier tick, so we have four distinct teams in engineering:
- The frontend team, which works on the very powerful workflow editor.
- The full stack team, which is cross-functional but focuses on the workflow engine.
- The devops team, which keeps the engine humming.
- The platform team, which helps with QA, and onboards partners to our developer platform.
All told, this involves about 15 engineers (and is growing!).
 HighScalability Team
HighScalability Team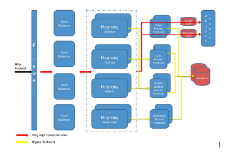
 Patreon recently snagged
Patreon recently snagged