How Uber Manages a Million Writes Per Second Using Mesos and Cassandra Across Multiple Datacenters

If you are Uber and you need to store the location data that is sent out every 30 seconds by both driver and rider apps, what do you do? That’s a lot of real-time data that needs to be used in real-time.
Uber’s solution is comprehensive. They built their own system that runs Cassandra on top of Mesos. It’s all explained in a good talk by Abhishek Verma, Software Engineer at Uber: Cassandra on Mesos Across Multiple Datacenters at Uber (slides).
Is this something you should do too? That’s an interesting thought that comes to mind when listening to Abhishek’s talk.
Developers have a lot of difficult choices to make these days. Should we go all in on the cloud? Which one? Isn’t it too expensive? Do we worry about lock-in? Or should we try to have it both ways and craft brew a hybrid architecture? Or should we just do it all ourselves for fear of being cloud shamed by our board for not reaching 50 percent gross margins?
Uber decided to build their own. Or rather they decided to weld together their own system by fusing together two very capable open source components. What was needed was a way to make Cassandra and Mesos work together, and that’s what Uber built.
For Uber the decision is not all that hard. They are very well financed and have access to the top talent and resources needed to create, maintain, and update these kind of complex systems.
Since Uber’s goal is for transportation to have 99.99% availability for everyone, everywhere, it really makes sense to want to be able to control your costs as you scale to infinity and beyond.
But as you listen to the talk you realize the staggering effort that goes into making these kind of systems. Is this really something your average shop can do? No, not really. Keep this in mind if you are one of those cloud deniers who want everyone to build all their own code on top of the barest of bare metals.
Trading money for time is often a good deal. Trading money for skill is often absolutely necessary.
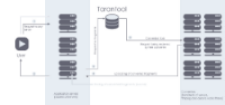
Given Uber’s goal of reliability, where out of 10,000 requests only one can fail, they need to run out of multiple datacenters. Since Cassandra is proven to handle huge loads and works across datacenters, it makes sense as the database choice.
And if you want to make transportation reliable for everyone, everywhere, you need to use your resources efficiently. That’s the idea behind using a datacenter OS like Mesos. By statistically multiplexing services on the same machines you need 30% fewer machines, which saves money. Mesos was chosen because at the time Mesos was the only product proven to work with cluster sizes of 10s of thousands of machines, which was an Uber requirement. Uber does things in the large.
What were some of the more interesting findings?
-
You can run stateful services in containers. Uber found there was hardly any difference, 5-10% overhead, between running Cassandra on bare metal versus running Cassandra in a container managed by Mesos.
-
Performance is good: mean read latency: 13 ms and write latency: 25 ms, and P99s look good.
-
For their largest clusters they are able to support more than a million writes/sec and ~100k reads/sec.
-
Agility is more important than performance. With this kind of architecture what Uber gets is agility. It’s very easy to create and run workloads across clusters.
Here’s my gloss of the talk:
 HighScalability Team
HighScalability Team