













Give Meaning to 100 billion Events a Day - The Analytics Pipeline at Teads
This is a guest post by Alban Perillat-Merceroz, Software Engineer at Teads.tv.
In this article, we describe how we orchestrate Kafka, Dataflow and BigQuery together to ingest and transform a large stream of events. When adding scale and latency constraints, reconciling and reordering them becomes a challenge, here is how we tackle it.
In digital advertising, day-to-day operations generate a lot of events we need to track in order to transparently report campaign’s performances. These events come from:
- Users’ interactions with the ads, sent by the browser. These events are called tracking events and can be standard (start, complete, pause, resume, etc.) or custom events coming from interactive creatives built with Teads Studio. We receive about 10 billion tracking events a day.
- Events coming from our back-ends, regarding ad auctions’ details for the most part (real-time bidding processes). We generate more than 60 billion of these events daily, before sampling, and should double this number in 2018.
In the article we focus on tracking events as they are on the most critical path of our business.
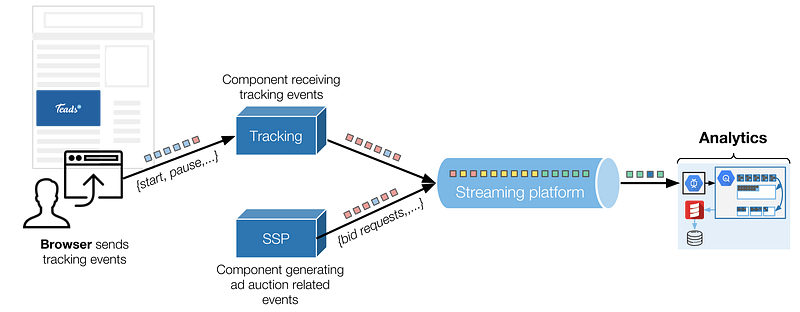
Tracking events are sent by the browser over HTTP to a dedicated component that, amongst other things, enqueues them in a Kafka topic. Analytics is one of the consumers of these events (more on that below).
We have an Analytics team whose mission is to take care of these events and is defined as follows:
We ingest the growing amount of logs,
We transform them into business-oriented data,
Which we serve efficiently and tailored for each audience.
To fulfill this mission, we build and maintain a set of processing tools and pipelines. Due to the organic growth of the company and new products requirements, we regularly challenge our architecture.
Why we moved to BigQuery
 HighScalability Team
HighScalability TeamHow ipdata serves 25M API calls from 10 infinitely scalable global endpoints for $150 a month

This is a guest post by Jonathan Kosgei, founder of ipdata, an IP Geolocation API.
I woke up on Black Friday last year to a barrage of emails from users reporting 503 errors from the ipdata API.
Our users typically call our API on each page request on their websites to geolocate their users and localize their content. So this particular failure was directly impacting our users’ websites on the biggest sales day of the year.
I only lost one user that day but I came close to losing many more.
This sequence of events and their inexplicable nature — cpu, mem and i/o were nowhere near capacity. As well as concerns on how well (if at all) we would scale, given our outage, were a big wake up call to rethink our existing infrastructure.
Our Tech stack at the time
Netflix: What Happens When You Press Play?

This article is a chapter from my new book Explain the Cloud Like I'm 10. The first release was written specifically for cloud newbies. I've made some updates and added a few chapters—Netflix: What Happens When You Press Play? and What is Cloud Computing?—that level it up to a couple ticks past beginner. I think even fairly experienced people might get something out of it.
So if you are looking for a good introduction to the cloud or know someone who is, please take a look. I think you'll like it. I'm pretty proud of how it turned out.
I pulled this chapter together from dozens of sources that were at times somewhat contradictory. Facts on the ground change over time and depend who is telling the story and what audience they're addressing. I tried to create as coherent a narrative as I could. If there are any errors I'd be more than happy to fix them. Keep in mind this article is not a technical deep dive. It's a big picture type article. For example, I don't mention the word microservice even once :-)
Netflix seems so simple. Press play and video magically appears. Easy, right? Not so much.
Given our discussion in the What is Cloud Computing? chapter, you might expect Netflix to serve video using AWS. Press play in a Netflix application and video stored in S3 would be streamed from S3, over the internet, directly to your device.
A completely sensible approach…for a much smaller service.
But that’s not how Netflix works at all. It’s far more complicated and interesting than you might imagine.
To see why let’s look at some impressive Netflix statistics for 2017.
- Netflix has more than 110 million subscribers.
- Netflix operates in more than 200 countries.
- Netflix has nearly $3 billion in revenue per quarter.
- Netflix adds more than 5 million new subscribers per quarter.
- Netflix plays more than 1 billion hours of video each week. As a comparison, YouTube streams 1 billion hours of video every day while Facebook streams 110 million hours of video every day.
- Netflix played 250 million hours of video on a single day in 2017.
- Netflix accounts for over 37% of peak internet traffic in the United States.
- Netflix plans to spend $7 billion on new content in 2018.
What have we learned?
Netflix is huge. They’re global, they have a lot of members, they play a lot of videos, and they have a lot of money.
Another relevant factoid is Netflix is subscription based. Members pay Netflix monthly and can cancel at any time. When you press play to chill on Netflix, it had better work. Unhappy members unsubscribe.
Netflix operates in two clouds: AWS and Open Connect.
How does Netflix keep their members happy? With the cloud of course. Actually, Netflix uses two different clouds: AWS and Open Connect.
Both clouds must work together seamlessly to deliver endless hours of customer-pleasing video.
The three parts of Netflix: client, backend, CDN.
You can think of Netflix as being divided into three parts: the client, the backend, and the CDN.
The client is the user interface on any device used to browse and play Netflix videos. It could be an app on your iPhone, a website on your desktop computer, or even an app on your Smart TV. Netflix controls each and every client for each and every device.
Everything that happens before you hit play happens in the backend, which runs in AWS. That includes things like preparing all new incoming video and handling requests from all apps, websites, TVs, and other devices.
Everything that happens after you hit play is handled by Open Connect. Open Connect is Netflix’s custom global content delivery network (CDN). When you press play the video is served from Open Connect. Don’t worry; we’ll talk about what this means later.
Interestingly, at Netflix they don’t actually say hit play on video, they say clicking start on a title. Every industry has its own lingo.
By controlling all three areas—client, backend, CDN— Netflix has achieved complete vertical integration.
Netflix controls your video viewing experience from beginning to end. That’s why it just works when you click play from anywhere in the world. You reliably get the content you want to watch when you want to watch it.
Let’s see how Netflix makes that happen.
In 2008 Netflix Started Moving to AWS
ButterCMS Architecture: a Mission-Critical API Serving Millions of Requests per Month

This is a guest post by Jake Lumetta, co-founder and CEO of ButterCMS.
ButterCMS lets developers add a content management system to any website in minutes. Our business requires us to deliver near-100% uptime for our API, but after multiple outages that nearly crippled our business, we became obsessed with eliminating single points of failure. In this post, I’ll discuss how we use Fastly’s edge cloud platform and other strategies to make sure we keep our customers’ websites up and running.
At its core, ButterCMS offers:
-
A dashboard for content editors
-
A JSON API for fetching content
-
SDK’s for integrating ButterCMS into native code
ButterCMS Tech Stack
Why Morningstar Moved to the Cloud: 97% Cost Reduction

Enterprises won't move to the cloud. If they do, it's tantamount to admitting your IT group sucks. That has been the common wisdom. Morningstar, an investment research provider, is moving to the cloud and they're about as enterprisey as it gets. And they don't strike me as incompetent, they just don't want to worry about all the low level IT stuff anymore.
Mitch Shue, Morningstar's CTO, gave a short talk at AWS Summit Series 2017 on their move to AWS. It's not full of nitty gritty technical details. That's not the interesting part. The talk is more about their motivations, the process they used to make the move, and some of the results they've experienced. While that's more interesting, we've heard a lot of it before.
What I found most interesting was the idea of Morningstar as a canary test. If Morningstar succeeds, the damn might bust and we'll see a lot more adoption of the cloud by stodgy mainstream enterprises. It's a copy cat world. That sort of precedent gives other CTOs the cover they need to make the same decision.
The most important idea in the whole talk: the cost savings of moving to the cloud are nice, but what they were more interested in is "creating a frictionless development experience to spur innovation and creativity."
Software is eating the world. Morningstar is no doubt looking at the future and sees the winners will be those who can develop the best software, the fastest. They need to get better at developing software. Owning your own infrastructure is a form of technical debt. Time to pay down the debt and get to the real work of innovating, not plumbing.
Here's my gloss of the talk:
The AdStage Migration from Heroku to AWS

This is a guest repost by G Gordon Worley III, Head of Site Reliability Engineering at AdStage.
When I joined AdStage in the Fall of 2013 we were already running on Heroku. It was the obvious choice: super easy to get started with, less expensive than full-sized virtual servers, and flexible enough to grow with our business. And grow we did. Heroku let us focus exclusively on building a compelling product without the distraction of managing infrastructure, so by late 2015 we were running thousands of dynos (containers) simultaneously to keep up with our customers.
We needed all those dynos because, on the backend, we look a lot like Segment, and like them many of our costs scale linearly with the number of users. At $25/dyno/month, our growth projections put us breaking $1 million in annual infrastructure expenses by mid-2016 when factored in with other technical costs, and that made up such a large proportion of COGS that it would take years to reach profitability. The situation was, to be frank, unsustainable. The engineering team met to discuss our options, and some quick calculations showed us we were paying more than $10,000 a month for the convenience of Heroku over what similar resources would cost directly on AWS. That was enough to justify an engineer working full-time on infrastructure if we migrated off Heroku, so I was tasked to become our first Head of Operations and spearhead our migration to AWS.
It was good timing, too, because Heroku had become our biggest constraint. Our engineering team had adopted a Kanban approach, so ideally we would have a constant flow of stories moving from conception to completion. At the time, though, we were generating lots of work-in-progress that routinely clogged our release pipeline. Work was slow to move through QA and often got sent back for bug fixes. Too often things “worked on my machine” but would fail when exposed to our staging environment. Because AdStage is a complex mix of interdependent services written on different tech stacks, it was hard for each developer to keep their workstation up-to-date with production, and this also made deploying to staging and production a slow process requiring lots of manual intervention. We had little choice in the matter, though, because we had to deploy each service as its own Heroku application, limiting our opportunities for automation. We desperately needed to find an alternative that would permit us to automate deployments and give developers earlier access to reliable test environments.
So in addition to cutting costs by moving off Heroku, we also needed to clear the QA constraint. I otherwise had free reign in designing our AWS deployment so long as it ran all our existing services with minimal code changes, but I added several desiderata:
Architecture of Probot - My Slack and Messenger Bot for Answering Questions

I programmed a thing. It’s called Probot. Probot is a quick and easy way to get high quality answers to your accounting and tax questions. Probot will find a real live expert to answer your question and handle all the details. You can get your questions answered over Facebook Messenger, Slack, or the web. Answers start at $10. That’s the pitch.
Seems like a natural in this new age of bots, doesn’t it? I thought so anyway. Not so much (so far), but more on that later.
I think Probot is interesting enough to cover because it’s a good example of how one programmer--me---can accomplish quite a lot using today’s infrastructure.
All this newfangled cloud/serverless/services stuff does in fact work. I was able to program a system spanning Messenger, Slack, and the web, in a way that is relatively scalabile, available, and affordable, while requiring minimal devops.
Gone are the days of worrying about VPS limits, driving down to a colo site to check on a sick server, or even worrying about auto-scaling clusters of containers/VMs. At least for many use cases.
Many years of programming experience and writing this blog is no protection against making mistakes. I made a lot of stupid stupid mistakes along the way, but I’m happy with what I came up with in the end.
Here’s how Probot works....
Platform
How Urban Airship Scaled to 2.5 Billion Notifications During the U.S. Election

This is a guest post by Urban Airship. Contributors: Adam Lowry, Sean Moran, Mike Herrick, Lisa Orr, Todd Johnson, Christine Ciandrini, Ashish Warty, Nick Adlard, Mele Sax-Barnett, Niall Kelly, Graham Forest, and Gavin McQuillan
Urban Airship is trusted by thousands of businesses looking to grow with mobile. Urban Airship is a seven year old SaaS company and has a freemium business model so you can try it for free. For more information, visit www.urbanairship.com. Urban Airship now averages more than one billion push notifications delivered daily. This post highlights Urban Airship notification usage for the 2016 U.S. election, exploring the architecture of the system--the Core Delivery Pipeline--that delivers billions of real-time notifications for news publishers.
2016 U.S. Election
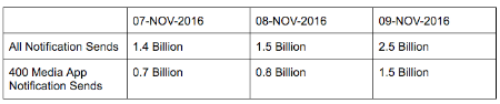
In the 24 hours surrounding Election Day, Urban Airship delivered 2.5 billion notifications—its highest daily volume ever. This is equivalent to 8 notification per person in the United States or 1 notification for every active smartphone in the world. While Urban Airship powers more than 45,000 apps across every industry vertical, analysis of the election usage data shows that more than 400 media apps were responsible for 60% of this record volume, sending 1.5 billion notifications in a single day as election results were tracked and reported.
Notification volume was steady and peaked when the presidential election concluded:
The QuickBooks Platform

This is a guest post by Siddharth Ram – Chief Architect, Small Business. Siddharth_ram@intuit.com.
The QuickBooks ecosystem is the largest small business SaaS product. The QuickBooks Platform supports bookkeeping, payroll and payment solutions for small businesses, their customers and accountants worldwide. Since QuickBooks is also a compliance & tax filing platform, consistency in reporting is extremely important.. Financial reporting requires flexibility in queries – a given report may have dozens of different dimensions that can be tweaked. Collaboration requires multiple edits by employees, Accountants and Business owners at the same time, leading to potential conflicts. All this leads to solving interesting scaling problems at Intuit.
Solving for scalability requires thinking on multiple time horizons and axes. Scaling is not just about scaling software – it is also about people scalability, process scalability and culture scalability. All these axes are actively worked on at Intuit. Our goal with employees is to create an atmosphere that allows them to do the best work of their lives.
Background
Lessons Learned from Scaling Uber to 2000 Engineers, 1000 Services, and 8000 Git repositories
For a visual of the growth Uber is experiencing take a look at the first few seconds of the above video. It will start in the right place. It's from an amazing talk given by Matt Ranney, Chief Systems Architect at Uber and Co-founder of Voxer: What I Wish I Had Known Before Scaling Uber to 1000 Services (slides).
It shows a ceaseless, rhythmic, undulating traffic grid of growth occurring in a few Chinese cities. This same pattern of explosive growth is happening in cities all over the world. In fact, Uber is now in 400 cities and 70 countries. They have over 6000 employees, 2000 of whom are engineers. Only a year and half a go there were just 200 engineers. Those engineers have produced over 1000 microservices which are stored in over 8000 git repositories.
That's crazy 10x growth in a crazy short period of time. Who has experienced that? Not many. And as you might expect that sort of unique, compressed, fast paced, high stakes experience has to teach you something new, something deeper than you understood before.
Matt is not new to this game. He was co-founder of Voxer, which experienced its own rapid growth, but this is different. You can tell while watching the video Matt is trying to come to terms with what they've accomplished.
Matt is a thoughtful guy and that comes through. In a recent interview he says:
And a lot of architecture talks at QCon and other events left me feeling inadequate; like other people- like Google for example - had it all figured out but not me.
This talk is Matt stepping outside of the maelstrom for a bit, trying to make sense of an experience, trying to figure it all out. And he succeeds. Wildly.
It's part wisdom talk and part confessional. "Lots of mistakes have been made along the way," Matt says, and those are where the lessons come from.
The scaffolding of the talk hangs on WIWIK (What I Wish I Had Known) device, which has become something of an Internet meme. It's advice he would give his naive, one and half year younger self, though of course, like all of us, he certainly would not listen.
And he would not be alone. Lots of people have been critical of Uber (HackerNews, Reddit). After all, those numbers are really crazy. Two thousand engineers? Eight thousand repositories? One thousand services? Something must be seriously wrong, isn't it?
Maybe. Matt is surprisingly non-judgemental about the whole thing. His mode of inquiry is more questioning and searching than finding absolutes. He himself seems bemused over the number of repositories, but he gives the pros and cons of more repositories versus having fewer repositories, without saying which is better, because given Uber's circumstances: how do you define better?
Uber is engaged in a pitched world-wide battle to build a planetary scale system capable of capturing a winner-takes-all market. That's the business model. Be the last service standing. What does better mean in that context?
Winner-takes-all means you have to grow fast. You could go slow and appear more ordered, but if you go too slow you’ll lose. So you balance on the edge of chaos and dip your toes, or perhaps your whole body, into chaos, because that’s how you’ll scale to become the dominant world wide service. This isn’t a slow growth path. This a knock the gate down and take everything strategy. Think you could do better? Really?
Microservices are a perfect fit for what Uber is trying to accomplish. Plug your ears, but it's a Conway's Law thing, you get so many services because that's the only way so many people can be hired and become productive.
There's no technical reason for so many services. There's no technical reason for so many repositories. This is all about people. mranney sums it up nicely:
Scaling the traffic is not the issue. Scaling the team and the product feature release rate is the primary driver.
A consistent theme of the talk is this or that is great, but there are tradeoffs, often surprising tradeoffs that you really only experience at scale. Which leads to two of the biggest ideas I took from the talk:
- Microservices are a way of replacing human communication with API coordination. Rather than people talking and dealing with team politics it's easier for teams to simply write new code. It reminds me of a book I read long ago, don't remember the name, where people lived inside a Dyson Sphere and because there was so much space and so much free energy available within the sphere that when any group had a conflict with another group they could just splinter off and settle into a new part of the sphere. Is this better? I don't know, but it does let a lot of work get done in parallel while avoiding lots of people overhead.
- Pure carrots, no sticks. This is a deep point about the role of command and control is such a large diverse group. You'll be tempted to mandate policy. Thou shalt log this way, for example. If you don't there will be consequences. That's the stick. Matt says don't do that. Use carrots instead. Any time the sticks come out it's bad. So no mandates. The way you want to handle it is provide tools that are so obvious and easy to use that people wouldn’t do it any other way.
This is one of those talks you have to really watch to understand because a lot is being communicated along dimensions other than text. Though of course I still encourage you to read my gloss of the talk :-)
