Auth0 Architecture - Running in Multiple Cloud Providers and Regions

This is a guest post by Jose Romaniello, Head of Engineering, at Auth0. There is a new version of this post! Check out Auth0 Architecture - Running In Multiple Cloud Providers And Regions (2018).
Auth0 provides authentication, authorization and single sign on services for apps of any type: mobile, web, native; on any stack.
Authentication is critical for the vast majority of apps. We designed Auth0 from the beginning with multipe levels of redundancy. One of this levels is hosting. Auth0 can run anywhere: our cloud, your cloud, or even your own servers. And when we run Auth0 we run it on multiple-cloud providers and in multiple regions simultaneously.
This article is a brief introduction of the infrastructure behind app.auth0.com and the strategies we use to keep it up and running with high availability.
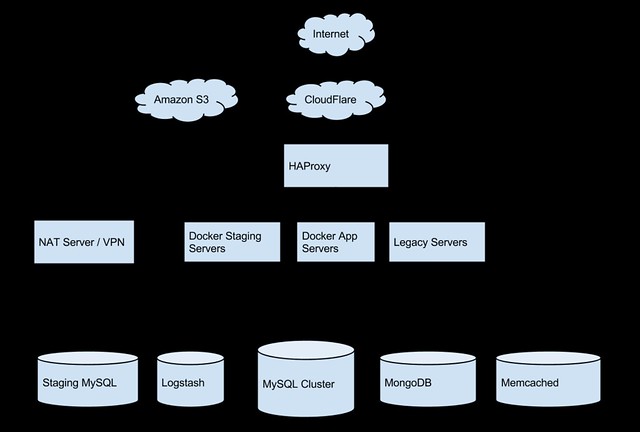
Core Service Architecture
The core service is relatively simple:
-
Front-end servers: these consist of several x-large VMs, running Ubuntu on Microsoft Azure.
-
Store: mongodb, running on dedicated memory optimized X-large VMs.
-
Intra-node service routing: nginx
All components of Auth0 (e.g. Dashboard, transaction server, docs) run on all nodes. All identical.
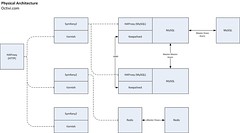
Multi-cloud / High Availability Multi cloud architecture
Multi cloud architecture

Last week, Azure suffered a global outage that lasted for hours. During that time our HA plan activated and we switched over to AWS
-
The services runs primarily on Microsoft Azure (IaaS). Secondary nodes on stand-by always ready on AWS.
-
We use Route53 with a failover routing policy. TTL at 60 secs. The Route53 health check detects using a probe against primary DC, if it fails (3 times, 10 seconds interval) it changes the DNS entry to point to secondary DC. So max downtime in case of primary failure is ~2 minutes.
-
We use puppet to deploy on every "push to master". Using puppet allows us to be cloud independent on the configuration/deployment process. Puppet Master runs on our build server (TeamCity currently).
-
MongoDB is replicated often to secondary DC and secondary DC is configured as read-only.
-
While running on the secondary DC, only runtime logins are allowed and the dashboard is set to "read-only mode".
-
We replicate all the configuration needed for a login to succeed (application info, secrets, connections, users, etc). We don’t replicate transactional data (tokens, logs).
-
In case of failover, there might might some logging records that are lost. We are planning to improve that by having a real-time replica across Azure and AWS.
-
We use our own version of chaos monkey to test the resiliency of our infrastructure https://github.com/auth0/chaos-mona

Automated Testing
-
We have 1000+ unit and integration tests.
-
We use saucelabs to run cross-browser (desktop/mobile) integration tests for Lock, our JavaScript login widget.
-
We use phantomjs/casper for integration tests. We test, for instance, that a full flow login with Google and other providers works fine.
-
All these run before every push to production.
CDN
Our use case is simple, we need to serve our JS library and its configuration (which providers are enabled, etc.). Assets and configuration data is uploaded to S3. It has to support TLS on our own custom domain (https://cdn.auth0.com). We ended up building our own CDN.
-
We tried 3 reputable CDN providers, but run into a whole variety of issues: The first one we tried when we didn't have our own domain for cdn. At some point we decided we needed our own domain over SSL/TLS. This cdn was too expensive if you want SSL and customer domain at that point (600/mo). We also had issues configuring it to work with gzip and S3. Since S3 cannot serve both version (zipped and not) of the same file and this CDN doesn't have content negotiation, some browsers (cough IE) don't play well with this. So we moved to another CDN which was much cheaper.
-
The second CDN, we had a handful of issues and we couldn't understand the root cause of them. Their support was on chat and it took time to get answers. Sometimes it seemed to be S3 issues, sometimes they had issues on routing, etc.
-
We decided to spend more money and we moved to a third CDN. Given that this CDN is being used by high load services like GitHub we thought it was going to be fine. However, our requirements were different from GitHub. If the CDN doesn't work for GitHub, you won't see an image on the README.md. In our case, our customers depends on the CDN to serve the Login Widget, which means that if it doesn't work, then their customers can't login.
-
We ended up building our own CDN using nginx, varnish and S3. It's hosted on every region on AWS and so far it has been working great (no downtime). We use Route53 latency based routing.
Sandbox (Used to run untrusted code)
One of the features we provide is the ability to run custom code as part of the login transaction. Customers can write these rules and we have a public repository for commonly used rules.
-
The sandbox is built on CoreOS, Docker and etcd.
-
There is a pool of Docker instances that gets assigned to a tenant on-demand.
-
Each tenant gets its own docker instance and there is a recycling policy based on idle time.
-
There is a controller doing the recycling policy and a proxy that routes the request to the right container.


More information about the sandbox is in this JSConf presentation Nov 2014: https://www.youtube.com/watch?feature=player_detailpage&v=I4VkZ5H9PE8#t=7015 and slides: http://tjanczuk.github.io/about/sandbox.html
Monitoring
Initially we used pingdom (we still use it), but we decided to develop our own health check system that can run arbitrary health checks based on node.js scripts. These run from all AWS regions.
-
It uses the same sandbox we developed for our service. We call the sandbox via an http API and send the node.js script to run as an HTTP POST.
-
We monitor all the components and we also do synthetic transactions against the service (e.g. a login transaction).


If a health check fails we get notified through Slack. We have two Slack channels #p1 and #p2. If the failure happens 1 time, it gets posted to #p2. If it happens 2 times in a row it gets posted to #p1 and all members of devops get an SMS (via Twilio).

For detailed performance counters and response times we use statsd and we send all the metrics to Librato. This is an example of a chart you can create.

We also setup alerts based on derivative metrics (i.e. how much something grows or shrinks in a time period). For instance, we have one based on logins: if Derivate(logins) > X => Send an alert to Slack.

Finally, we have alerts coming from NewRelic for infrastructure components.

For logging we use ElasticSearch, Logstash and Kibana. We are storing logs from nginx and mongodb at this point. We are also parsing mongo logs using logstash in order to identify slow queries (anything with a high number of collscans).

Website
-
All related web properties: the auth0.com site, our blog, etc. run completely separate from the app and runtime, on their own Ubuntu + Docker VMs.
Future
This is where we are going:
-
We are moving to CoreOS and Docker. We want to move to a model where we manage clusters as a whole instead of doing configuration management over individual nodes. Docker helps also by removing some moving parts by doing image-based deployment (and be able to rollback at that level as well).
-
MongoDB will be geo-replicated across DCs between AWS and Azure. We are testing latency.
-
For all the search related features we are moving to ElasticSearch to provide search based on any criteria. MongoDB didn't work out well in this scenario (given our multi-tenancy).
 HighScalability Team
HighScalability Team