This is a guest post by Dan Bartow, VP of SOASTA, talking about how they pelted MySpace with 1 million concurrent users using 800 EC2 instances. I thought this was an interesting story because: that's a lot of users, it takes big cajones to test your live site like that, and not everything worked out quite as expected. I'd like to thank Dan for taking the time to write and share this article.
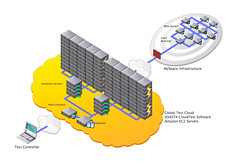
In December of 2009 MySpace launched a new wave of streaming music video offerings in New Zealand, building on the previous success of MySpace music. These new features included the ability to watch music videos, search for artist’s videos, create lists of favorites, and more. The anticipated load increase from a feature like this on a popular site like MySpace is huge, and they wanted to test these features before making them live.
If you manage the infrastructure that sits behind a high traffic application you don’t want any surprises. You want to understand your breaking points, define your capacity thresholds, and know how to react when those thresholds are exceeded. Testing the production infrastructure with actual anticipated load levels is the only way to understand how things will behave when peak traffic arrives.
For MySpace, the goal was to test an additional 1 million concurrent users on their live site stressing the new video features. The key word here is ‘concurrent’. Not over the course of an hour or day… 1 million users concurrently active on the site. It should be noted that 1 million virtual users are only a portion of what MySpace typically has on the site during its peaks. They wanted to supplement the live traffic with test traffic to get an idea of the overall performance impact of the new launch on the entire infrastructure. This requires a massive amount of load generation capability, which is where cloud computing comes into play. To do this testing, MySpace worked with SOASTA to use the cloud as a load generation platform.
Here are the details of the load that was generated during testing.
Click to read more ...














 HighScalability Team
HighScalability Team

 If Twitter is the “nervous system of the web” as some people think, then what is the brain that makes sense of all those signals (tweets) from the nervous system? That brain is the Twitter Analytics System and Kevin Weil, as Analytics Lead at Twitter, is the homunculus within in charge of figuring out what those over 100 billion tweets (approximately the number of neurons in the human brain) mean.
If Twitter is the “nervous system of the web” as some people think, then what is the brain that makes sense of all those signals (tweets) from the nervous system? That brain is the Twitter Analytics System and Kevin Weil, as Analytics Lead at Twitter, is the homunculus within in charge of figuring out what those over 100 billion tweets (approximately the number of neurons in the human brain) mean.